Efficient Encoder-Free Fourier-based 3D Large Multimodal Model
作者: Guofeng Mei, Wei Lin, Luigi Riz, Yujiao Wu, Yiming Wang, Fabio Poiesi
分类: cs.CV, cs.AI
发布日期: 2026-02-28
💡 一句话要点
提出Fase3D:一种高效无编码器的傅里叶3D大模型,用于处理大规模点云场景。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D大型多模态模型 点云处理 快速傅里叶变换 无编码器 全局上下文建模 空间填充曲线 LoRA适配器
📋 核心要点
- 现有3D LMM依赖于计算量大的预训练视觉编码器,效率低且难以扩展到大规模点云。
- Fase3D通过结合点云序列化和快速傅里叶变换(FFT)的tokenizer,在无编码器的情况下实现高效的全局上下文建模。
- Fase3D在计算和参数效率上显著优于基于编码器的3D LMM,同时保持了相当的性能。
📝 摘要(中文)
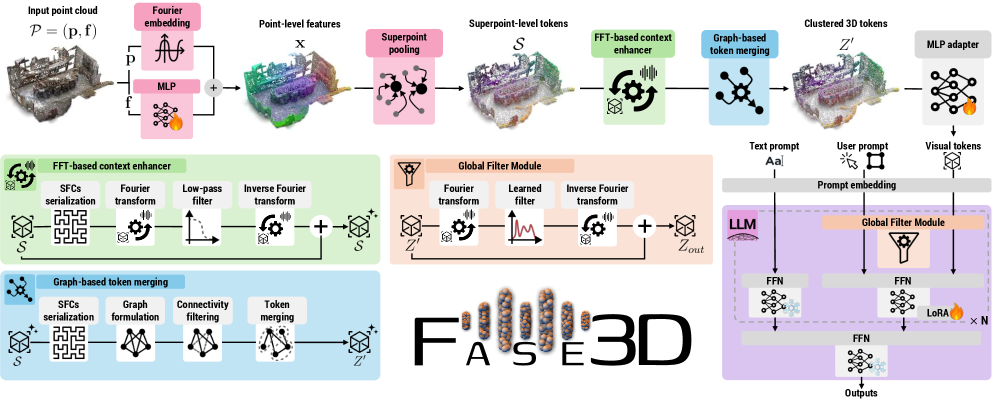
大型多模态模型(LMMs)处理3D数据时通常依赖于计算量大的预训练视觉编码器来提取几何特征。虽然最近的2D LMMs已经开始消除这种编码器以提高效率和可扩展性,但由于点云的无序性和大规模性,将这种范式扩展到3D仍然具有挑战性。这留下了一个关键的未解决问题:我们如何设计一个LMM,在没有繁琐的编码器的情况下,有效且高效地对无序3D数据进行标记化?我们提出了Fase3D,这是第一个高效的、无编码器的、基于傅里叶的3D场景LMM。Fase3D通过一种新颖的标记器解决了可扩展性和置换不变性的挑战,该标记器结合了点云序列化和快速傅里叶变换(FFT)来近似自注意力。这种设计实现了一种有效且计算量最小的架构,建立在三个关键创新之上:首先,我们通过结构化的超点紧凑地表示大型场景。其次,我们的空间填充曲线序列化,然后进行FFT,实现了高效的全局上下文建模和基于图的token合并。最后,我们的傅里叶增强LoRA适配器以可忽略的成本将全局频率感知交互注入到LLM中。Fase3D实现了与基于编码器的3D LMM相当的性能,同时在计算和参数方面效率更高。
🔬 方法详解
问题定义:现有3D大型多模态模型依赖于预训练的视觉编码器来提取3D几何特征,这些编码器计算量大,参数众多,限制了模型的可扩展性和效率。尤其是在处理大规模、无序的点云数据时,如何高效地进行特征提取和全局上下文建模是一个关键问题。现有方法的痛点在于计算复杂度高,难以应用于实际场景。
核心思路:Fase3D的核心思路是利用快速傅里叶变换(FFT)在频域中近似自注意力机制,从而避免使用传统的视觉编码器。通过将点云数据序列化并进行FFT,模型能够在频域中捕捉全局上下文信息,并进行高效的token合并。这种方法旨在降低计算复杂度,提高模型效率,同时保持甚至提升性能。
技术框架:Fase3D的整体架构包含以下几个主要阶段:1) 超点表示:将大规模点云场景划分为结构化的超点,以紧凑地表示场景。2) 空间填充曲线序列化:使用空间填充曲线(如希尔伯特曲线)将无序的点云数据转换为有序的序列。3) 快速傅里叶变换(FFT):对序列化的数据进行FFT,将其转换到频域。4) Token合并:在频域中进行基于图的token合并,减少token数量。5) 傅里叶增强LoRA适配器:使用LoRA适配器将频域信息注入到大型语言模型(LLM)中。
关键创新:Fase3D最重要的技术创新在于使用FFT来近似自注意力机制,从而避免了使用传统的视觉编码器。这种方法不仅降低了计算复杂度,还使得模型能够更好地捕捉全局上下文信息。此外,使用空间填充曲线进行点云序列化也是一个关键创新,它使得能够将无序的点云数据转换为有序的序列,从而能够应用FFT。
关键设计:Fase3D的关键设计包括:1) 使用结构化的超点来紧凑地表示大规模场景。2) 使用希尔伯特曲线进行点云序列化。3) 使用FFT进行频域转换和全局上下文建模。4) 使用基于图的token合并来减少token数量。5) 使用傅里叶增强LoRA适配器将频域信息注入到LLM中。具体的参数设置、损失函数和网络结构等细节在论文中有更详细的描述。
🖼️ 关键图片


📊 实验亮点
Fase3D在性能上与基于编码器的3D LMM相当,但在计算效率和参数数量上显著优于后者。具体而言,Fase3D在多个3D场景理解任务上取得了具有竞争力的结果,同时减少了大量的计算资源和参数。实验结果表明,Fase3D是一种高效且有效的3D大型多模态模型。
🎯 应用场景
Fase3D具有广泛的应用前景,包括自动驾驶、机器人导航、三维场景理解、虚拟现实和增强现实等领域。通过高效地处理大规模点云数据,Fase3D可以帮助机器人更好地理解周围环境,从而实现更安全、更智能的导航和交互。此外,该模型还可以用于三维场景重建、物体识别和语义分割等任务,为相关应用提供强大的技术支持。
📄 摘要(原文)
Large Multimodal Models (LMMs) that process 3D data typically rely on heavy, pre-trained visual encoders to extract geometric features. While recent 2D LMMs have begun to eliminate such encoders for efficiency and scalability, extending this paradigm to 3D remains challenging due to the unordered and large-scale nature of point clouds. This leaves a critical unanswered question: How can we design an LMM that tokenizes unordered 3D data effectively and efficiently without a cumbersome encoder? We propose Fase3D, the first efficient encoder-free Fourier-based 3D scene LMM. Fase3D tackles the challenges of scalability and permutation invariance with a novel tokenizer that combines point cloud serialization and the Fast Fourier Transform (FFT) to approximate self-attention. This design enables an effective and computationally minimal architecture, built upon three key innovations: First, we represent large scenes compactly via structured superpoints. Second, our space-filling curve serialization followed by an FFT enables efficient global context modeling and graph-based token merging. Lastly, our Fourier-augmented LoRA adapters inject global frequency-aware interactions into the LLMs at a negligible cost. Fase3D achieves performance comparable to encoder-based 3D LMMs while being significantly more efficient in computation and parameters. Project website:this https URL.