Benchmarking Video Foundation Models for Remote Parkinson's Disease Screening
作者: Md Saiful Islam, Ekram Hossain, Abdelrahman Abdelkader, Tariq Adnan, Fazla Rabbi Mashrur, Sooyong Park, Praveen Kumar, Qasim Sudais, Natalia Chunga, Nami Shah, Jan Freyberg, Christopher Kanan, Ruth Schneider, Ehsan Hoque
分类: cs.CV
发布日期: 2026-02-28
💡 一句话要点
利用视频基础模型进行远程帕金森病筛查的基准测试研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频分析 帕金森病筛查 视频基础模型 远程医疗 临床任务 表征学习 迁移学习
📋 核心要点
- 现有帕金森病筛查方法依赖手工特征,缺乏自动化和泛化能力,难以适应远程筛查的需求。
- 本研究利用视频基础模型(VFMs)提取视频特征,无需针对特定任务进行定制,实现高效的表征学习。
- 实验结果表明,不同VFM在不同临床任务中表现各异,为远程帕金森病筛查提供了模型选择和任务组合的指导。
📝 摘要(中文)
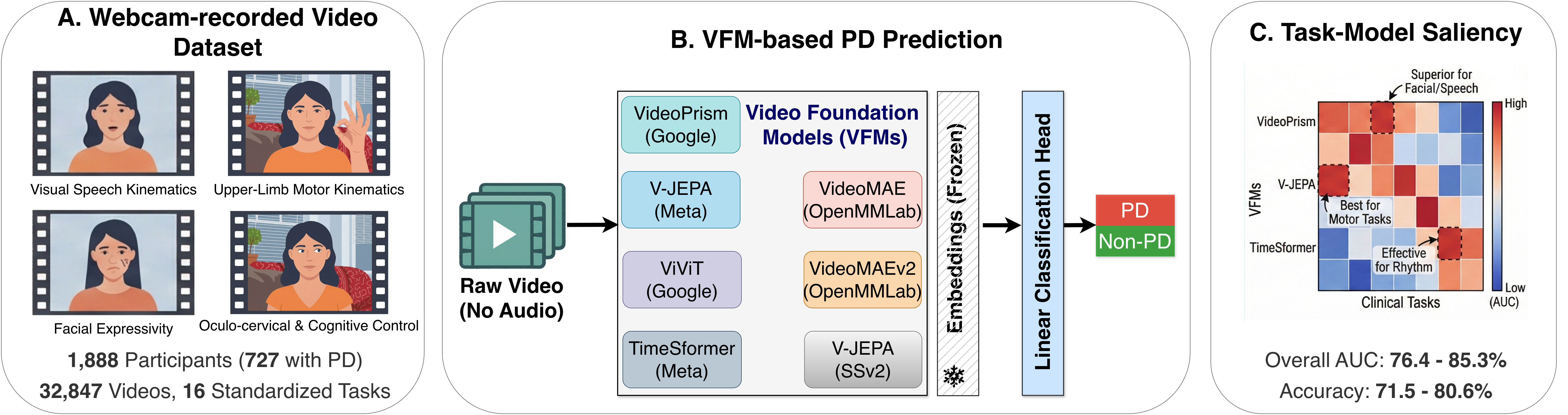
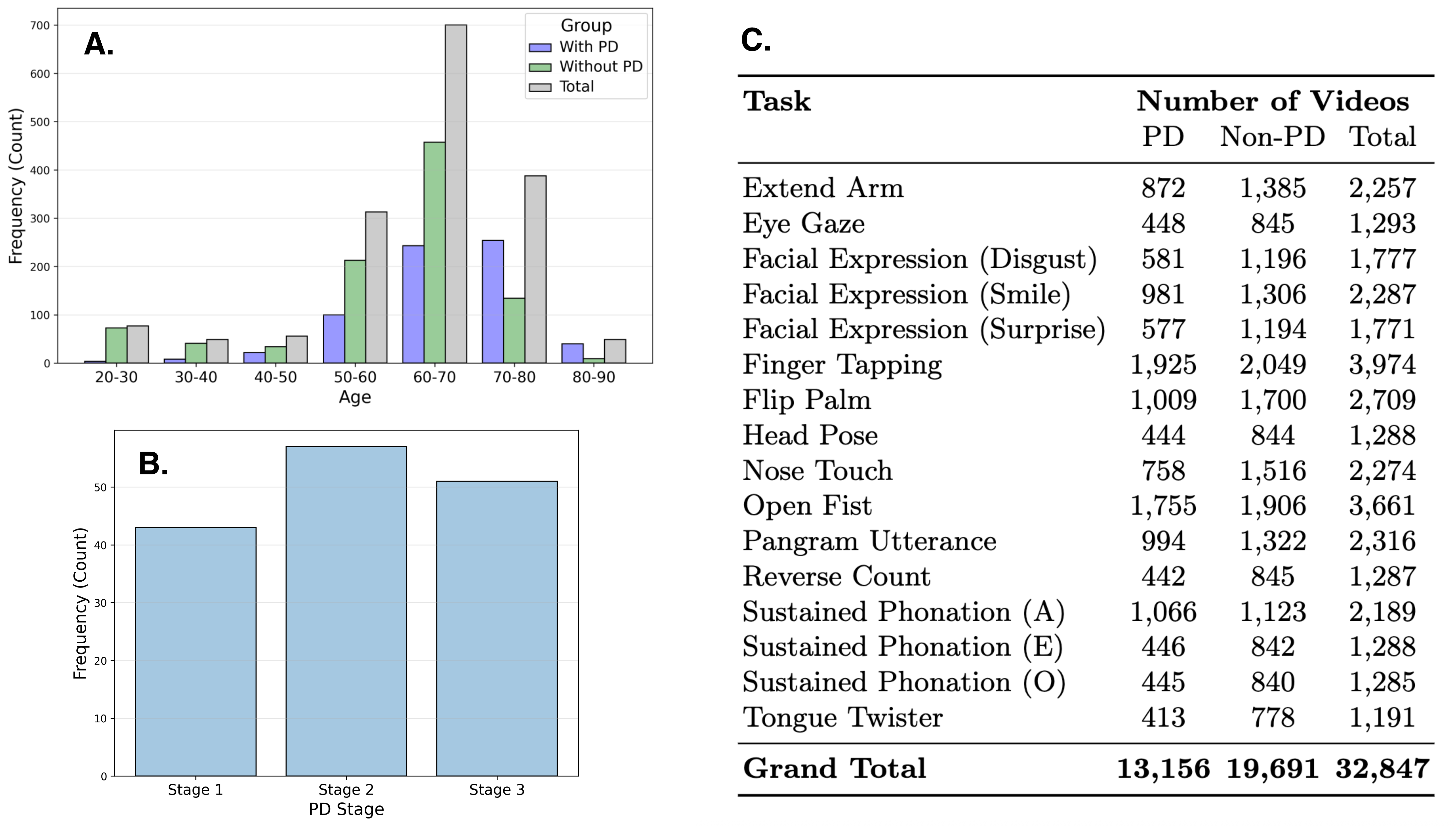
本研究旨在探索基于视频的远程帕金森病(PD)筛查方法。尽管传统方法依赖于模仿临床量表的手工特征,但视频基础模型(VFMs)的最新进展使得无需任务特定定制即可进行表征学习。然而,不同VFM架构在各种临床任务中的相对有效性仍然知之甚少。我们使用来自1888名参与者(其中727名患有PD)的新型视频数据集进行了一项大规模系统研究,该数据集包含跨16项标准化临床任务的32847个视频。我们评估了七个最先进的VFMs——包括VideoPrism、V-JEPA、ViViT和VideoMAE——以确定它们在临床筛查中的鲁棒性。通过评估带有线性分类头的冻结嵌入,我们证明了任务显著性高度依赖于模型:VideoPrism擅长捕捉视觉语音运动学(无音频)和面部表情,而V-JEPA在肢体运动任务中表现更佳。值得注意的是,TimeSformer在手指敲击等节奏任务中仍然具有很强的竞争力。我们的实验产生了76.4 - 85.3%的AUC和71.5 - 80.6%的准确率。虽然高特异性(高达90.3%)表明其在排除健康个体方面具有强大的潜力,但较低的敏感性(43.2 - 57.3%)突出了任务感知校准以及整合多项任务和模态的必要性。总的来说,这项工作为基于VFM的PD筛查建立了一个严格的基线,并为远程神经系统监测中选择合适的任务和架构提供了路线图。代码和匿名结构化数据已公开。
🔬 方法详解
问题定义:该论文旨在解决远程帕金森病(PD)筛查的问题。现有方法主要依赖于手工设计的特征,这些特征需要专家知识,且泛化能力有限。此外,传统方法难以处理大规模视频数据,限制了远程筛查的应用。
核心思路:论文的核心思路是利用视频基础模型(VFMs)自动学习视频中的表征,从而避免了手工特征工程的需要。通过评估不同VFM在不同临床任务中的表现,为远程PD筛查选择合适的模型和任务组合。
技术框架:整体框架包括数据收集、VFM特征提取和线性分类器训练三个主要阶段。首先,收集包含16项标准化临床任务的大规模视频数据集。然后,使用七种不同的VFM(VideoPrism、V-JEPA、ViViT、VideoMAE等)提取视频特征。最后,使用线性分类器对提取的特征进行分类,评估不同VFM在PD筛查中的性能。
关键创新:该研究的关键创新在于对多种最先进的VFM在PD筛查任务中的性能进行了系统性的比较和分析。通过实验发现,不同VFM在不同临床任务中表现出不同的优势,这为任务感知的模型选择提供了依据。此外,该研究还构建了一个大规模的视频数据集,为PD筛查研究提供了宝贵的数据资源。
关键设计:该研究的关键设计包括:1) 使用冻结的VFM嵌入,避免了在小数据集上微调VFM带来的过拟合问题;2) 使用线性分类器进行分类,简化了模型训练过程;3) 针对不同的临床任务,评估了不同VFM的性能,并分析了任务显著性对模型选择的影响;4) 评估了模型的特异性和敏感性,为临床应用提供了参考。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同的视频基础模型在不同的临床任务中表现出显著差异。VideoPrism在捕捉视觉语音运动学和面部表情方面表现出色,而V-JEPA在肢体运动任务中表现更佳。TimeSformer在节奏任务中仍然具有竞争力。实验获得了76.4 - 85.3%的AUC和71.5 - 80.6%的准确率,特异性高达90.3%。
🎯 应用场景
该研究成果可应用于远程医疗、智能健康监测等领域,实现帕金森病的早期筛查和诊断。通过视频分析,可以降低筛查成本,提高筛查效率,尤其是在医疗资源匮乏的地区具有重要意义。未来,该技术可扩展到其他神经系统疾病的筛查和监测。
📄 摘要(原文)
Video-based assessments offer a scalable pathway for remote Parkinson's disease (PD) screening. While traditional approaches rely on handcrafted features mimicking clinical scales, recent advances in video foundation models (VFMs) enable representation learning without task-specific customization. However, the comparative effectiveness of different VFM architectures across diverse clinical tasks remains poorly understood. We present a large-scale systematic study using a novel video dataset from 1,888 participants (727 with PD), comprising 32,847 videos across 16 standardized clinical tasks. We evaluate seven state-of-the-art VFMs -- including VideoPrism, V-JEPA, ViViT, and VideoMAE -- to determine their robustness in clinical screening. By evaluating frozen embeddings with a linear classification head, we demonstrate that task saliency is highly model-dependent: VideoPrism excels in capturing visual speech kinematics (no audio) and facial expressivity, while V-JEPA proves superior for upper-limb motor tasks. Notably, TimeSformer remains highly competitive for rhythmic tasks like finger tapping. Our experiments yield AUCs of 76.4 - 85.3% and accuracies of 71.5 - 80.6%. While high specificity (up to 90.3%) suggests strong potential for ruling out healthy individuals, the lower sensitivity (43.2 - 57.3%) highlights the need for task-aware calibration and integration of multiple tasks and modalities. Overall, this work establishes a rigorous baseline for VFM-based PD screening and provides a roadmap for selecting suitable tasks and architectures in remote neurological monitoring. Code and anonymized structured data are publicly available:this https URL_video_benchmarking-A2C5