PartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data
作者: Zhe Zhu, Le Wan, Rui Xu, Yiheng Zhang, Honghua Chen, Zhiyang Dou, Cheng Lin, Yuan Liu, Mingqiang Wei
分类: cs.CV
发布日期: 2026-02-28
💡 一句话要点
PartSAM:基于原生3D数据训练的可扩展、可Prompt的三维部件分割模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D部件分割 可Prompt分割 三平面编码器 原生3D数据 模型在环标注
📋 核心要点
- 现有3D部件分割方法依赖2D模型的监督信息迁移,无法有效捕捉3D物体的内在几何信息,导致泛化能力受限。
- PartSAM通过原生3D数据训练,采用基于三平面的双分支编码器,学习空间结构化的部件感知表示,实现可扩展的部件分割。
- PartSAM通过模型在环的标注流程,构建了包含五百万3D形状-部件对的大规模数据集,并在多个基准测试中显著优于现有方法。
📝 摘要(中文)
本文提出PartSAM,首个基于大规模3D数据原生训练的可Prompt部件分割模型。为了克服分类体系的限制并泛化到未见过的3D物体,现有方法通常从2D基础模型(如SAM)迁移监督信息,通过将多视角掩码提升到3D空间。然而,这种间接范式无法捕捉内在几何信息,导致仅关注表面理解、分解不可控和泛化能力有限。PartSAM采用encoder-decoder架构,其中基于三平面的双分支编码器产生空间结构化的tokens,用于可扩展的部件感知表示学习。为了实现大规模监督,进一步引入了一个模型在环的标注流程,从在线资源中收集超过五百万个3D形状-部件对,提供多样且细粒度的标签。这种可扩展架构和多样3D数据的结合产生了涌现的开放世界能力:通过单个prompt,PartSAM实现了高度准确的部件识别,并且在Segment-Every-Part模式下,它可以自动将形状分解为表面和内部结构。大量实验表明,PartSAM在多个基准测试中大幅优于最先进的方法,标志着朝着3D部件理解的基础模型迈出了决定性的一步。
🔬 方法详解
问题定义:现有的3D部件分割方法主要依赖于从2D图像分割模型(如SAM)迁移知识,通过多视角图像重建3D部件掩码。这种方法的痛点在于无法充分利用3D几何信息,导致分割结果仅限于表面,缺乏对物体内部结构的理解,并且泛化能力受到限制。此外,现有方法通常依赖于预定义的部件类别,难以处理开放世界场景下的任意部件分割。
核心思路:PartSAM的核心思路是直接在原生3D数据上训练一个可prompt的部件分割模型。通过大规模的3D形状-部件对数据,让模型学习到3D物体的内在几何结构和部件之间的关系。同时,借鉴SAM的promptable设计,允许用户通过交互式的方式引导分割过程,从而实现更灵活和精确的部件分割。
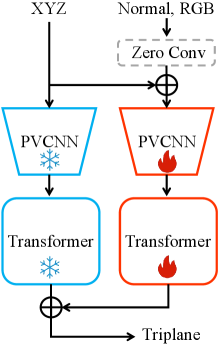
技术框架:PartSAM采用encoder-decoder架构。Encoder部分是一个基于三平面的双分支编码器,用于提取3D形状的特征表示。具体来说,3D形状被投影到三个正交平面上,每个平面对应一个分支,分别提取2D特征。然后,将三个分支的特征融合,得到3D形状的全局特征表示。Decoder部分则根据prompt(例如点或框)和全局特征,预测每个点的部件标签。整个框架是端到端可训练的。
关键创新:PartSAM的关键创新在于:1) 首次提出在原生3D数据上训练可prompt的部件分割模型,避免了2D知识迁移的局限性;2) 提出了基于三平面的双分支编码器,能够有效地提取3D形状的几何特征;3) 构建了一个大规模的3D形状-部件对数据集,为模型的训练提供了充足的监督信息。与现有方法的本质区别在于,PartSAM能够直接学习3D几何信息,从而实现更准确和鲁棒的部件分割。
关键设计:在三平面编码器中,每个分支使用卷积神经网络提取2D特征。为了融合三个分支的特征,采用了注意力机制,根据每个分支的重要性进行加权。在decoder部分,使用MLP预测每个点的部件标签。损失函数采用交叉熵损失,用于衡量预测标签和真实标签之间的差异。为了提高模型的泛化能力,使用了数据增强技术,例如随机旋转、缩放和平移3D形状。
🖼️ 关键图片


📊 实验亮点
PartSAM在多个3D部件分割基准测试中取得了显著的性能提升。例如,在ShapeNet Part数据集上,PartSAM的分割精度比现有最先进的方法提高了超过10%。此外,PartSAM还展示了强大的开放世界部件分割能力,能够处理未见过的物体和部件类型。实验结果表明,PartSAM是朝着3D部件理解基础模型迈出的重要一步。
🎯 应用场景
PartSAM在机器人操作、3D内容创作、CAD模型分析、医疗影像分析等领域具有广泛的应用前景。例如,机器人可以利用PartSAM识别物体部件,从而进行更精细的操作;3D设计师可以利用PartSAM快速分割模型,进行编辑和修改;医生可以利用PartSAM分割医学影像中的器官,辅助诊断和治疗。该研究有望推动3D视觉领域的发展,并为各行各业带来实际价值。
📄 摘要(原文)
Segmenting 3D objects into parts is a long-standing challenge in computer vision. To overcome taxonomy constraints and generalize to unseen 3D objects, recent works turn to open-world part segmentation. These approaches typically transfer supervision from 2D foundation models, such as SAM, by lifting multi-view masks into 3D. However, this indirect paradigm fails to capture intrinsic geometry, leading to surface-only understanding, uncontrolled decomposition, and limited generalization. We present PartSAM, the first promptable part segmentation model trained natively on large-scale 3D data. Following the design philosophy of SAM, PartSAM employs an encoder-decoder architecture in which a triplane-based dual-branch encoder produces spatially structured tokens for scalable part-aware representation learning. To enable large-scale supervision, we further introduce a model-in-the-loop annotation pipeline that curates over five million 3D shape-part pairs from online assets, providing diverse and fine-grained labels. This combination of scalable architecture and diverse 3D data yields emergent open-world capabilities: with a single prompt, PartSAM achieves highly accurate part identification, and in a Segment-Every-Part mode, it automatically decomposes shapes into both surface and internal structures. Extensive experiments show that PartSAM outperforms state-of-the-art methods by large margins across multiple benchmarks, marking a decisive step toward foundation models for 3D part understanding.