SPATIALALIGN: Aligning Dynamic Spatial Relationships in Video Generation
作者: Fengming Liu, Tat-Jen Cham, Chuanxia Zheng
分类: cs.CV
发布日期: 2026-02-26
💡 一句话要点
SPATIALALIGN:通过自提升框架增强文本到视频生成模型对动态空间关系的建模能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 文本到视频生成 动态空间关系 直接偏好优化 几何关系建模 视频理解
📋 核心要点
- 现有的文本到视频生成模型通常侧重于生成视频的美学质量,而忽略了视频中动态空间关系的准确表达。
- SPATIALALIGN框架通过零阶正则化的直接偏好优化(DPO)微调T2V模型,使其更好地符合文本提示中的动态空间关系。
- 论文提出了DSR-SCORE指标来定量评估生成视频与文本提示中动态空间关系的对齐程度,并通过实验验证了该方法的有效性。
📝 摘要(中文)
本文提出SPATIALALIGN,一个自提升框架,旨在增强文本到视频(T2V)生成模型描绘文本提示中指定的动态空间关系(DSR)的能力。我们提出了一种零阶正则化的直接偏好优化(DPO)方法,用于微调T2V模型,使其更好地与DSR对齐。具体来说,我们设计了DSR-SCORE,一种基于几何的指标,用于定量衡量生成的视频与提示中指定的DSR之间的对齐程度,这比依赖VLM进行评估的先前工作更进一步。我们还构建了一个包含多样化DSR的文本-视频对数据集,以促进相关研究。大量实验表明,我们微调后的模型在空间关系方面显著优于基线模型。
🔬 方法详解
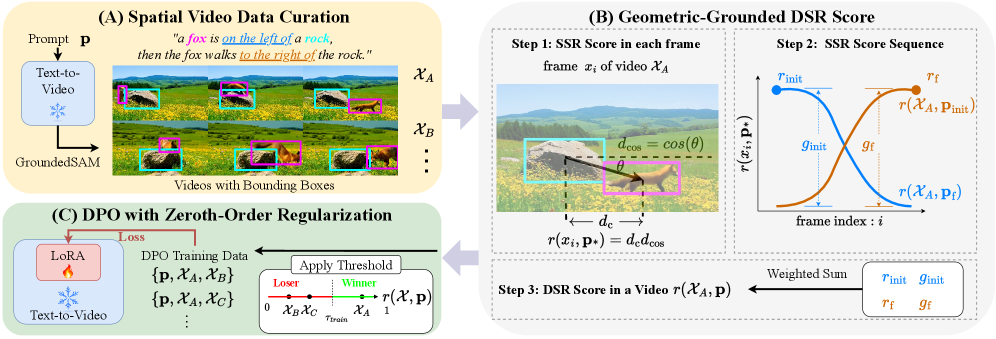
问题定义:文本到视频生成任务旨在根据给定的文本描述生成相应的视频。然而,现有方法往往难以准确捕捉和表达文本中描述的动态空间关系,例如“A在B的左边移动到C的右边”。现有方法主要关注视频的视觉质量,缺乏对空间关系一致性的约束和评估。
核心思路:SPATIALALIGN的核心思路是通过自提升的方式,利用直接偏好优化(DPO)算法,微调现有的文本到视频生成模型,使其更好地对齐文本描述中的动态空间关系。该方法通过引入一个基于几何的DSR-SCORE指标,来定量评估生成视频中空间关系的准确性,并以此作为DPO算法的优化目标。
技术框架:SPATIALALIGN框架主要包含以下几个模块:1) 文本到视频生成模型(T2V),作为基础模型;2) 动态空间关系数据集,用于训练和评估;3) DSR-SCORE指标,用于评估生成视频中空间关系的准确性;4) 零阶正则化的直接偏好优化(DPO)算法,用于微调T2V模型。整个流程是:首先,使用T2V模型生成视频;然后,使用DSR-SCORE评估生成视频中空间关系的准确性;最后,使用DPO算法根据DSR-SCORE的结果微调T2V模型。
关键创新:该论文的关键创新点在于:1) 提出了DSR-SCORE指标,能够定量评估生成视频中动态空间关系的准确性,克服了以往依赖人工评估或VLM评估的局限性;2) 提出了零阶正则化的DPO算法,能够有效地微调T2V模型,使其更好地对齐文本描述中的动态空间关系;3) 构建了一个包含多样化DSR的文本-视频对数据集,为相关研究提供了数据基础。
关键设计:DSR-SCORE指标基于几何关系,通过检测视频中关键对象的位置,计算它们之间的空间关系,并与文本描述中的空间关系进行比较,从而得到一个量化的分数。DPO算法使用DSR-SCORE作为奖励信号,通过优化T2V模型的参数,使其生成的视频能够获得更高的DSR-SCORE。零阶正则化项用于防止DPO算法过度拟合,提高模型的泛化能力。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过SPATIALALIGN框架微调后的T2V模型在动态空间关系表达方面显著优于基线模型。DSR-SCORE指标的评估结果显示,微调后的模型在空间关系准确性方面取得了显著提升,具体提升幅度未知。此外,人工评估也表明,微调后的模型生成的视频在空间关系方面更加符合文本描述。
🎯 应用场景
该研究成果可应用于视频内容创作、游戏开发、机器人导航等领域。例如,可以根据文本描述自动生成包含特定空间关系的动画或游戏场景;也可以用于训练机器人理解和执行包含空间关系的指令。未来,该技术有望进一步提升人机交互的自然性和智能化水平。
📄 摘要(原文)
Most text-to-video (T2V) generators prioritize aesthetic quality, but often ignoring the spatial constraints in the generated videos. In this work, we present SPATIALALIGN, a self-improvement framework that enhances T2V models capabilities to depict Dynamic Spatial Relationships (DSR) specified in text prompts. We present a zeroth-order regularized Direct Preference Optimization (DPO) to fine-tune T2V models towards better alignment with DSR. Specifically, we design DSR-SCORE, a geometry-based metric that quantitatively measures the alignment between generated videos and the specified DSRs in prompts, which is a step forward from prior works that rely on VLM for evaluation. We also conduct a dataset of text-video pairs with diverse DSRs to facilitate the study. Extensive experiments demonstrate that our fine-tuned model significantly out performs the baseline in spatial relationships. The code will be released in Link.