NoLan: Mitigating Object Hallucinations in Large Vision-Language Models via Dynamic Suppression of Language Priors
作者: Lingfeng Ren, Weihao Yu, Runpeng Yu, Xinchao Wang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2026-02-25
备注: Code: https://github.com/lingfengren/NoLan
🔗 代码/项目: GITHUB
💡 一句话要点
NoLan:通过动态抑制语言先验缓解大型视觉语言模型中的对象幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 对象幻觉 语言先验 动态抑制 后处理 多模态学习 文本生成 知识蒸馏
📋 核心要点
- 现有大型视觉语言模型易产生对象幻觉,即生成图像中不存在的对象,降低了模型可靠性。
- NoLan通过动态抑制语言解码器的先验知识,减少模型对语言信息的过度依赖,从而抑制幻觉。
- 实验表明,NoLan在多个LVLM和任务上有效降低了对象幻觉,显著提升了模型准确率。
📝 摘要(中文)
对象幻觉是大型视觉语言模型(LVLMs)中的一个关键问题,即输出包含输入图像中不存在的对象。本文旨在回答一个自然产生的问题:LVLM流程的哪个组件主要导致对象幻觉?是感知视觉信息的视觉编码器,还是生成文本响应的语言解码器?通过设计一个系统的实验来分析视觉编码器和语言解码器在幻觉生成中的作用,我们的观察表明,对象幻觉主要与语言解码器的强先验相关。基于这一发现,我们提出了一个简单且无需训练的框架,即无语言幻觉解码(NoLan),它通过动态抑制语言先验来优化输出分布,并根据多模态和纯文本输入之间的输出分布差异进行调节。实验结果表明,NoLan有效地减少了各种LVLM在不同任务上的对象幻觉。例如,NoLan在POPE上取得了显著的改进,将LLaVA-1.5 7B和Qwen-VL 7B的准确率分别提高了6.45和7.21。
🔬 方法详解
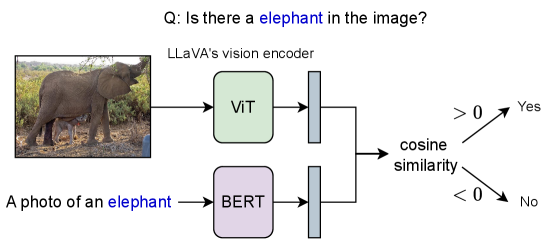
问题定义:大型视觉语言模型(LVLMs)在生成文本描述时,经常会产生“对象幻觉”,即在输出中包含图像中实际不存在的对象。现有的LVLM容易受到语言先验的影响,过度依赖语言模型自身的知识,而忽略了视觉输入的信息,导致幻觉的产生。
核心思路:NoLan的核心思路是通过动态抑制语言解码器的先验知识,来减少模型对语言信息的过度依赖,从而抑制对象幻觉。其基本假设是,如果模型过度依赖语言先验,那么在没有视觉输入的情况下,模型仍然会倾向于生成某些特定的对象。
技术框架:NoLan是一个无需训练的后处理框架,它作用于LVLM的解码阶段。其主要流程如下:1) 首先,分别使用多模态输入(图像+文本提示)和纯文本输入(仅文本提示)通过LVLM,得到两个输出分布。2) 然后,计算这两个输出分布之间的差异,该差异反映了语言先验的强度。3) 最后,根据这个差异,动态地调整输出分布,抑制语言先验,得到最终的输出。
关键创新:NoLan的关键创新在于其动态抑制语言先验的机制。与直接修改模型结构或训练过程不同,NoLan通过后处理的方式,在解码阶段对输出分布进行调整,从而有效地减少了对象幻觉。这种方法无需重新训练模型,具有很强的通用性和易用性。
关键设计:NoLan的关键设计在于如何计算和应用语言先验的抑制。具体来说,论文使用KL散度来衡量多模态和纯文本输入之间的输出分布差异。然后,使用一个可调节的参数来控制抑制的强度。最终的输出分布通过对原始输出分布进行加权平均得到,权重由KL散度和抑制强度参数决定。
🖼️ 关键图片


📊 实验亮点
NoLan在POPE数据集上取得了显著的性能提升。例如,在LLaVA-1.5 7B模型上,NoLan将准确率提高了6.45%。在Qwen-VL 7B模型上,NoLan将准确率提高了7.21%。这些结果表明,NoLan能够有效地减少对象幻觉,并提升LVLM的性能。
🎯 应用场景
NoLan可广泛应用于各种需要可靠视觉语言交互的场景,例如智能客服、图像编辑、机器人导航、自动驾驶等。通过减少对象幻觉,NoLan能够提升LVLM在这些场景中的实用性和安全性,增强用户信任度,并为更高级的视觉语言任务奠定基础。
📄 摘要(原文)
Object hallucination is a critical issue in Large Vision-Language Models (LVLMs), where outputs include objects that do not appear in the input image. A natural question arises from this phenomenon: Which component of the LVLM pipeline primarily contributes to object hallucinations? The vision encoder to perceive visual information, or the language decoder to generate text responses? In this work, we strive to answer this question through designing a systematic experiment to analyze the roles of the vision encoder and the language decoder in hallucination generation. Our observations reveal that object hallucinations are predominantly associated with the strong priors from the language decoder. Based on this finding, we propose a simple and training-free framework, No-Language-Hallucination Decoding, NoLan, which refines the output distribution by dynamically suppressing language priors, modulated based on the output distribution difference between multimodal and text-only inputs. Experimental results demonstrate that NoLan effectively reduces object hallucinations across various LVLMs on different tasks. For instance, NoLan achieves substantial improvements on POPE, enhancing the accuracy of LLaVA-1.5 7B and Qwen-VL 7B by up to 6.45 and 7.21, respectively. The code is publicly available at: https://github.com/lingfengren/NoLan.