Learning to Drive is a Free Gift: Large-Scale Label-Free Autonomy Pretraining from Unposed In-The-Wild Videos
作者: Matthew Strong, Wei-Jer Chang, Quentin Herau, Jiezhi Yang, Yihan Hu, Chensheng Peng, Wei Zhan
分类: cs.CV
发布日期: 2026-02-25
备注: Accepted at CVPR 2026
💡 一句话要点
提出LFG:一种基于无标注野外视频的大规模自动驾驶预训练方法
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 无监督学习 视频表征学习 时间上下文建模 多模态学习
📋 核心要点
- 现有自动驾驶方法依赖大量标注数据,成本高昂,而公开的驾驶视频缺乏标注,难以学习语义和3D几何信息。
- LFG利用前馈网络和自回归模块,通过多模态教师提供的伪监督信号,从无标注视频中学习统一的伪4D表征。
- 实验表明,LFG在自动驾驶规划任务中超越了多相机和激光雷达基线,并在语义、几何和运动预测任务中表现出色。
📝 摘要(中文)
本文提出了一种名为LFG的无标注、教师指导的框架,用于直接从无位姿视频中学习自动驾驶表征。不同于以往主要关注帧间一致性的自监督方法,本文认为安全和反应式驾驶关键依赖于时间上下文。为此,本文利用配备轻量级自回归模块的前馈架构,使用多模态监督信号进行训练,引导模型联合预测当前和未来的点云图、相机位姿、语义分割和运动掩码。多模态教师提供序列级别的伪监督,使LFG能够从原始YouTube视频中学习统一的伪4D表征,无需位姿、标签或激光雷达数据。所得到的编码器不仅能有效地迁移到NAVSIM基准上的下游自动驾驶规划任务,仅使用单个单目相机就超过了多相机和激光雷达基线,而且在语义、几何和定性运动预测任务中也表现出强大的性能。这些几何和运动感知特征使LFG成为一个引人注目的以视频为中心的自动驾驶基础模型。
🔬 方法详解
问题定义:现有自动驾驶模型训练依赖于大量的标注数据,获取成本高昂。虽然存在大量的公开驾驶视频,但由于缺乏精确的标注(如相机位姿、语义分割、深度信息等),难以直接利用这些数据进行有效的表征学习,尤其是在捕捉场景的语义结构和3D几何信息方面。以往的自监督学习方法主要关注帧与帧之间的一致性,忽略了时间上下文对于安全驾驶的重要性。
核心思路:本文的核心思路是利用大规模无标注的驾驶视频,通过教师模型生成伪标签,训练一个能够同时感知语义、几何和运动信息的自动驾驶模型。通过引入时间上下文建模,使模型能够更好地理解驾驶场景,从而提升自动驾驶的安全性。这种方法避免了对大量数据进行人工标注的需求,降低了训练成本。
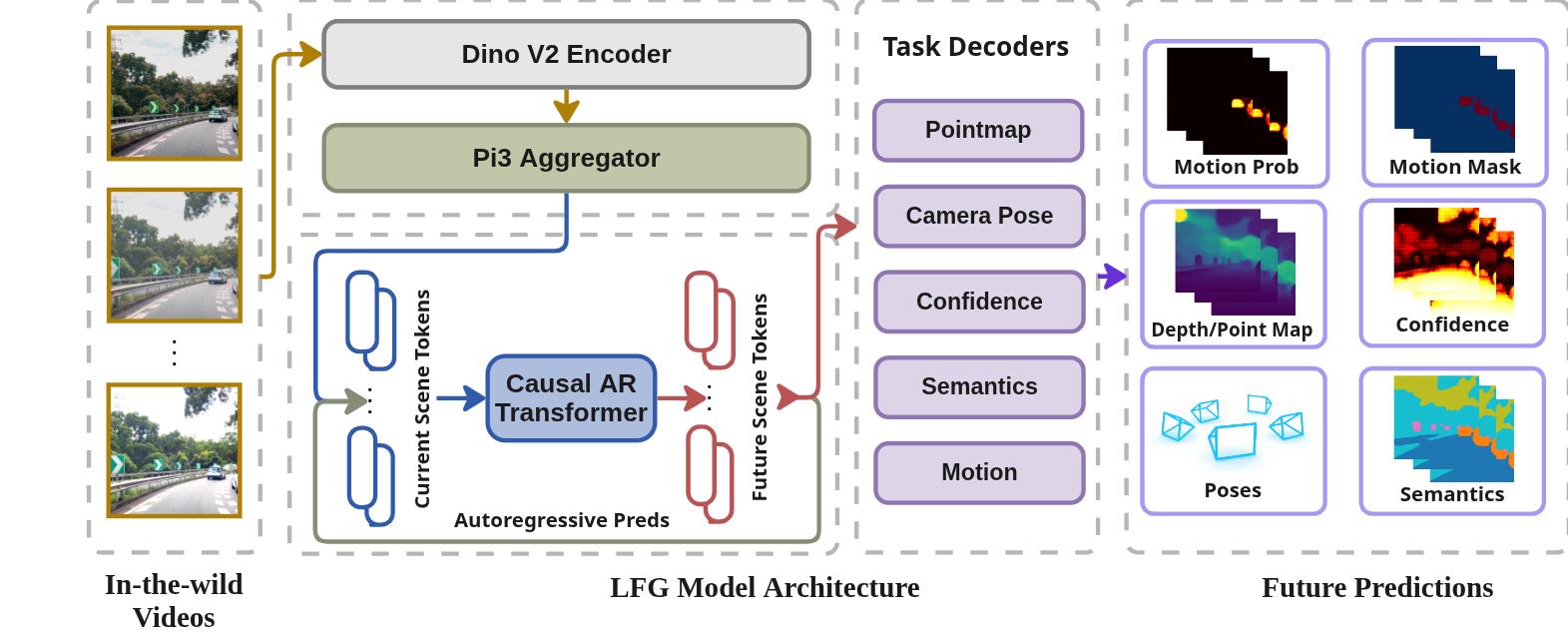
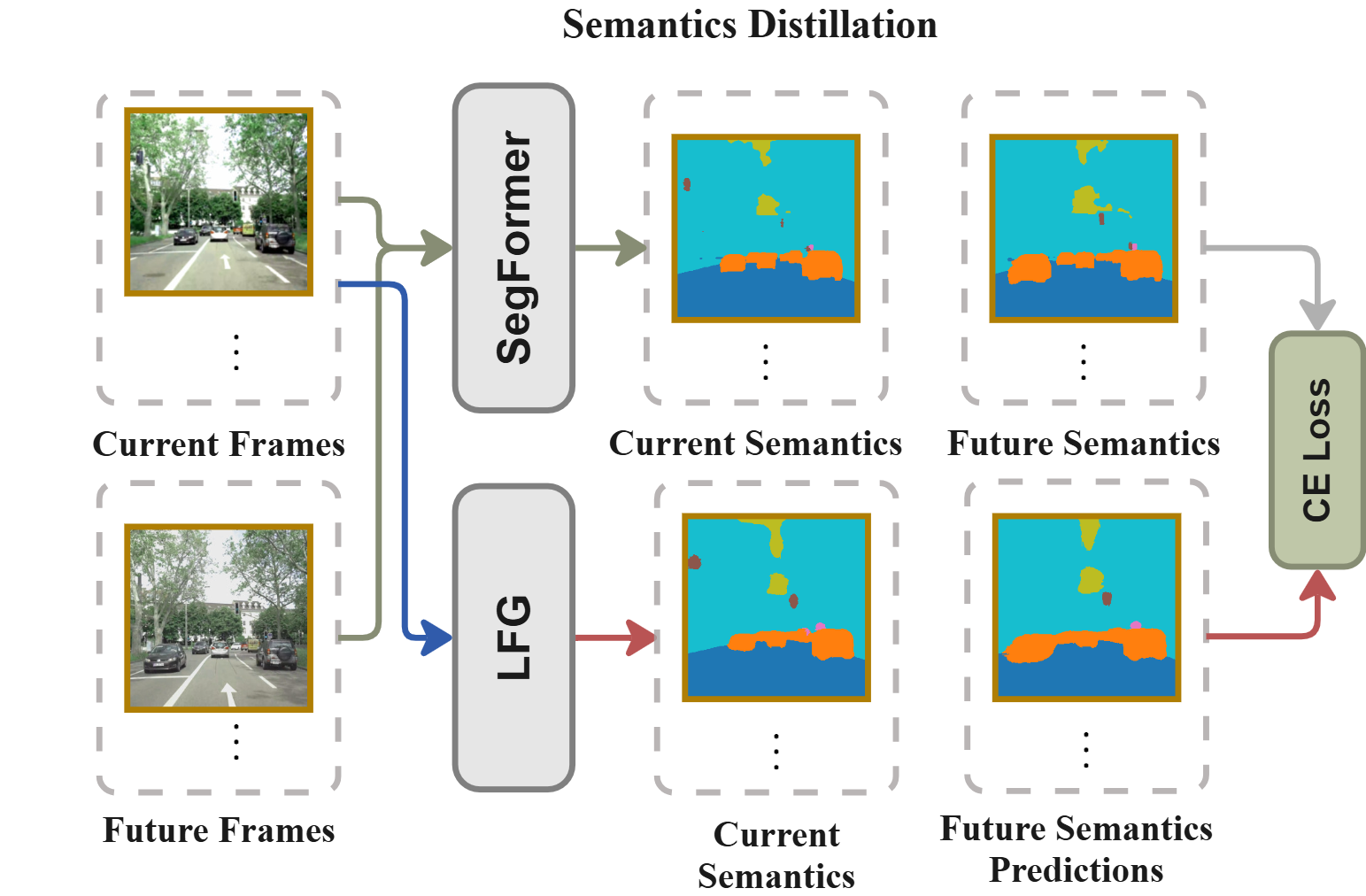
技术框架:LFG的整体框架包含一个前馈空间模型和一个轻量级的自回归模块。首先,前馈空间模型处理输入的视频帧,提取视觉特征。然后,自回归模块利用这些特征进行时间序列建模,捕捉视频中的时间上下文信息。多模态教师模型(例如,预训练的语义分割模型、深度估计模型等)为训练过程提供伪监督信号,包括点云图、相机位姿、语义分割和运动掩码等。模型的目标是联合预测当前和未来的这些信息。
关键创新:LFG的关键创新在于利用多模态教师模型生成伪标签,从而实现对大规模无标注视频的有效利用。与以往的自监督学习方法不同,LFG更加强调时间上下文的重要性,通过自回归模块对视频中的时间信息进行建模。此外,LFG学习的是一种统一的伪4D表征,能够同时捕捉场景的语义、几何和运动信息。
关键设计:LFG的关键设计包括:1) 使用前馈网络提取空间特征,保证计算效率;2) 引入轻量级的自回归模块,降低计算复杂度;3) 使用多模态教师模型提供丰富的伪监督信息,引导模型学习;4) 设计合适的损失函数,平衡不同模态之间的预测精度;5) 采用数据增强技术,提高模型的泛化能力。具体的网络结构和参数设置在论文中进行了详细描述,但未在摘要中体现。
🖼️ 关键图片

📊 实验亮点
LFG在NAVSIM基准测试中,仅使用单目相机就超越了多相机和激光雷达基线,证明了其强大的表征学习能力。此外,LFG在语义分割、深度估计和运动预测等任务中也取得了优异的性能,表明其学习到的表征能够有效地捕捉场景的语义、几何和运动信息。这些实验结果表明,LFG是一种极具潜力的自动驾驶基础模型。
🎯 应用场景
LFG具有广泛的应用前景,可用于自动驾驶、高级驾驶辅助系统(ADAS)、机器人导航等领域。通过利用大量的无标注视频数据,LFG可以降低自动驾驶模型的训练成本,提高模型的泛化能力和安全性。此外,LFG学习到的统一表征可以用于多种下游任务,如路径规划、行为预测等,为自动驾驶系统的开发提供强大的支持。未来,LFG可以进一步扩展到其他场景,如室内导航、无人机等。
📄 摘要(原文)
Ego-centric driving videos available online provide an abundant source of visual data for autonomous driving, yet their lack of annotations makes it difficult to learn representations that capture both semantic structure and 3D geometry. Recent advances in large feedforward spatial models demonstrate that point maps and ego-motion can be inferred in a single forward pass, suggesting a promising direction for scalable driving perception. We therefore propose a label-free, teacher-guided framework for learning autonomous driving representations directly from unposed videos. Unlike prior self-supervised approaches that focus primarily on frame-to-frame consistency, we posit that safe and reactive driving depends critically on temporal context. To this end, we leverage a feedforward architecture equipped with a lightweight autoregressive module, trained using multi-modal supervisory signals that guide the model to jointly predict current and future point maps, camera poses, semantic segmentation, and motion masks. Multi-modal teachers provide sequence-level pseudo-supervision, enabling LFG to learn a unified pseudo-4D representation from raw YouTube videos without poses, labels, or LiDAR. The resulting encoder not only transfers effectively to downstream autonomous driving planning on the NAVSIM benchmark, surpassing multi-camera and LiDAR baselines with only a single monocular camera, but also yields strong performance when evaluated on a range of semantic, geometric, and qualitative motion prediction tasks. These geometry and motion-aware features position LFG as a compelling video-centric foundation model for autonomous driving.