RobustVisRAG: Causality-Aware Vision-Based Retrieval-Augmented Generation under Visual Degradations
作者: I-Hsiang Chen, Yu-Wei Liu, Tse-Yu Wu, Yu-Chien Chiang, Jen-Chien Yang, Wei-Ting Chen
分类: cs.CV
发布日期: 2026-02-25
备注: Accepted by CVPR2026; Project Page: https://robustvisrag.github.io
💡 一句话要点
RobustVisRAG:提出因果感知的视觉退化鲁棒检索增强生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉退化 检索增强生成 因果推理 鲁棒性 视觉语言模型
📋 核心要点
- 现有VisRAG模型在视觉输入存在退化时性能显著下降,原因是语义信息与退化因素在视觉编码器中相互纠缠。
- RobustVisRAG采用因果引导的双路径框架,通过非因果路径捕获退化信号,并利用因果路径学习纯净的语义表示。
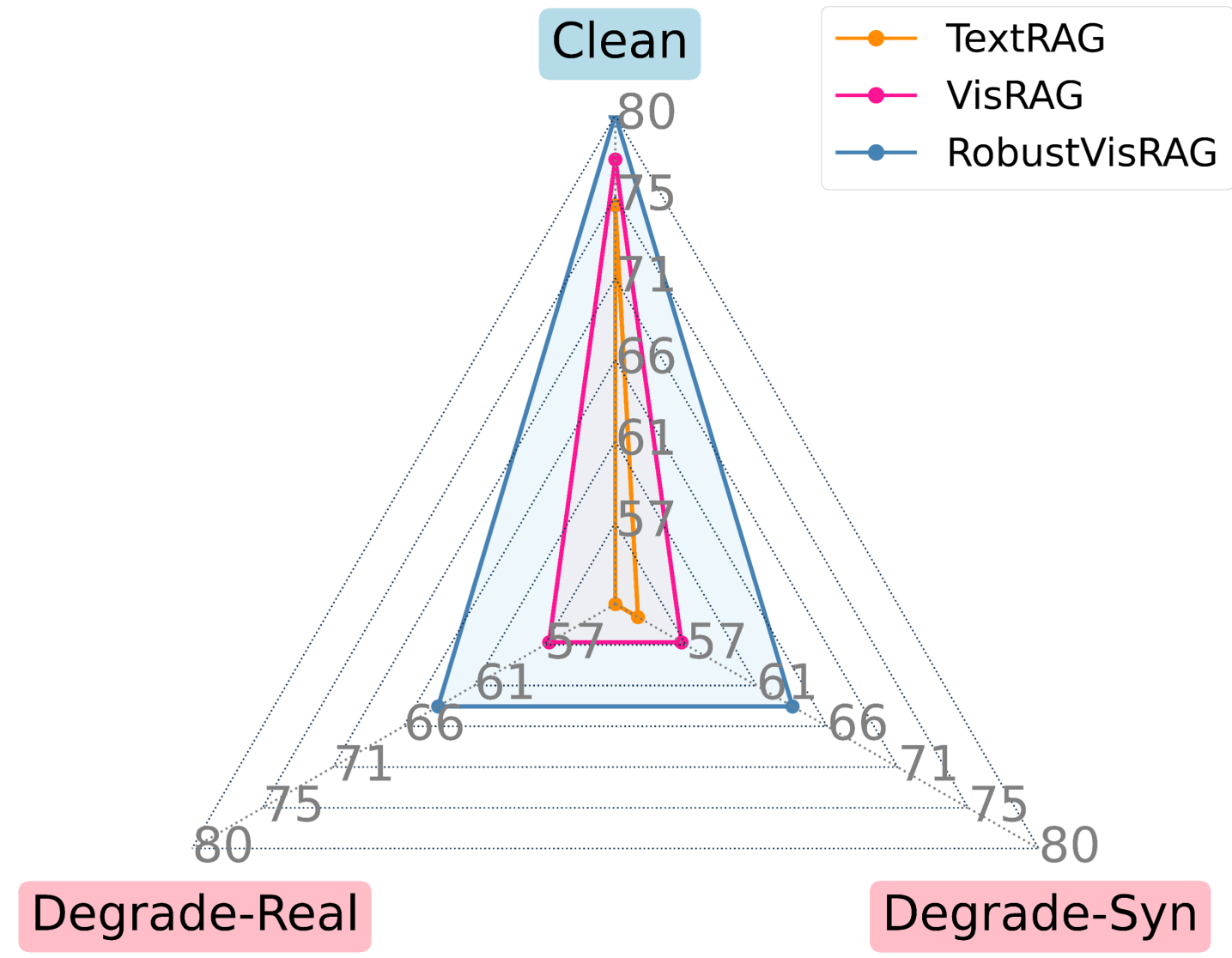
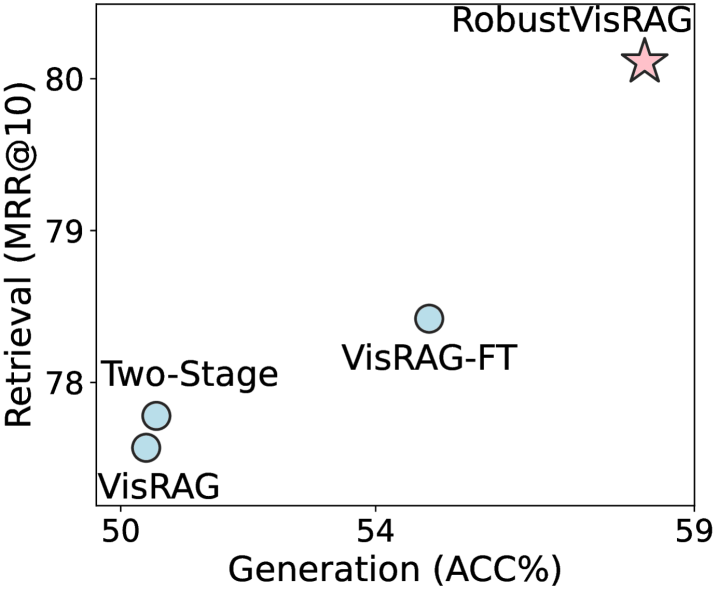
- 实验表明,RobustVisRAG在真实退化场景下,检索、生成和端到端性能分别提升了7.35%、6.35%和12.40%。
📝 摘要(中文)
基于视觉的检索增强生成(VisRAG)利用视觉-语言模型(VLMs)联合检索相关的视觉文档,并基于多模态证据生成有根据的答案。然而,当视觉输入受到模糊、噪声、低光或阴影等失真影响时,现有的VisRAG模型性能会下降,因为语义和退化因素在预训练的视觉编码器中纠缠在一起,导致检索和生成阶段的错误。为了解决这个限制,我们引入了RobustVisRAG,一个因果引导的双路径框架,它提高了VisRAG的鲁棒性,同时保持了效率和零样本泛化能力。RobustVisRAG使用非因果路径通过单向注意力捕获退化信号,并使用因果路径学习由这些信号引导的纯化语义。结合提出的非因果失真建模和因果语义对齐目标,该框架强制语义和退化之间的清晰分离,从而在具有挑战性的视觉条件下实现稳定的检索和生成。为了评估真实条件下的鲁棒性,我们引入了Distortion-VisRAG数据集,这是一个大规模基准,包含跨七个领域的合成和真实退化文档,具有12种合成和5种真实失真类型,全面反映了实际的视觉退化。实验结果表明,RobustVisRAG在真实世界退化的情况下,检索、生成和端到端性能分别提高了7.35%、6.35%和12.40%,同时在干净输入上保持了相当的准确性。
🔬 方法详解
问题定义:现有VisRAG模型在处理包含视觉退化(如模糊、噪声、低光照等)的图像时,性能会显著下降。这是因为预训练的视觉编码器难以区分图像的语义内容和退化因素,导致检索和生成过程出现错误。现有方法缺乏对视觉退化因素的有效建模和解耦,无法保证在各种视觉条件下都能稳定工作。
核心思路:RobustVisRAG的核心思路是通过因果推理来解耦图像的语义信息和退化因素。该方法利用双路径结构,一条路径(非因果路径)专门用于捕获退化信号,另一条路径(因果路径)则在退化信号的引导下学习纯净的语义表示。通过这种方式,模型能够更好地理解图像的真实内容,并减少退化因素对检索和生成的影响。
技术框架:RobustVisRAG框架包含两个主要路径:非因果路径和因果路径。非因果路径使用单向注意力机制来捕获图像中的退化信号。这些信号被用于引导因果路径,使其能够学习到与退化无关的语义表示。框架还包括两个关键的损失函数:非因果失真建模损失和因果语义对齐损失。前者用于训练非因果路径,使其能够准确地预测图像中的退化类型和程度;后者用于对齐两条路径的输出,确保因果路径学习到的语义表示与非因果路径捕获的退化信号一致。
关键创新:RobustVisRAG的关键创新在于其因果引导的双路径结构,以及相应的非因果失真建模和因果语义对齐损失函数。与现有方法相比,RobustVisRAG能够更有效地解耦图像的语义信息和退化因素,从而提高模型在各种视觉条件下的鲁棒性。此外,该框架还具有良好的效率和零样本泛化能力。
关键设计:RobustVisRAG的关键设计包括:1) 使用单向注意力机制来捕获退化信号,避免语义信息对退化信号的干扰;2) 设计非因果失真建模损失,鼓励非因果路径学习准确的退化表示;3) 设计因果语义对齐损失,促使因果路径学习与退化无关的语义表示;4) 构建大规模的Distortion-VisRAG数据集,包含多种合成和真实的视觉退化,用于评估模型的鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RobustVisRAG在真实世界退化数据集上,检索准确率提升了7.35%,生成质量提升了6.35%,端到端性能提升了12.40%。同时,该模型在干净数据集上保持了与现有方法相当的性能,证明了其在鲁棒性提升的同时,没有牺牲原有性能。
🎯 应用场景
RobustVisRAG可应用于各种需要处理视觉退化数据的场景,例如:自动驾驶(雨雾天气)、医学影像分析(低质量扫描)、安防监控(光照不足)等。该研究有助于提升视觉系统的可靠性和准确性,在实际应用中具有重要价值,并可能推动相关领域的发展。
📄 摘要(原文)
Vision-based Retrieval-Augmented Generation (VisRAG) leverages vision-language models (VLMs) to jointly retrieve relevant visual documents and generate grounded answers based on multimodal evidence. However, existing VisRAG models degrade in performance when visual inputs suffer from distortions such as blur, noise, low light, or shadow, where semantic and degradation factors become entangled within pretrained visual encoders, leading to errors in both retrieval and generation stages. To address this limitation, we introduce RobustVisRAG, a causality-guided dual-path framework that improves VisRAG robustness while preserving efficiency and zero-shot generalization. RobustVisRAG uses a non-causal path to capture degradation signals through unidirectional attention and a causal path to learn purified semantics guided by these signals. Together with the proposed Non-Causal Distortion Modeling and Causal Semantic Alignment objectives, the framework enforces a clear separation between semantics and degradations, enabling stable retrieval and generation under challenging visual conditions. To evaluate robustness under realistic conditions, we introduce the Distortion-VisRAG dataset, a large-scale benchmark containing both synthetic and real-world degraded documents across seven domains, with 12 synthetic and 5 real distortion types that comprehensively reflect practical visual degradations. Experimental results show that RobustVisRAG improves retrieval, generation, and end-to-end performance by 7.35%, 6.35%, and 12.40%, respectively, on real-world degradations, while maintaining comparable accuracy on clean inputs.