SemVideo: Reconstructs What You Watch from Brain Activity via Hierarchical Semantic Guidance
作者: Minghan Yang, Lan Yang, Ke Li, Honggang Zhang, Kaiyue Pang, Yizhe Song
分类: cs.CV, cs.AI
发布日期: 2026-02-25
💡 一句话要点
SemVideo:通过分层语义引导,从脑活动重建观看视频内容
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: fMRI 视频重建 脑机接口 语义引导 深度学习 视觉感知 CLIP 时间一致性
📋 核心要点
- 现有fMRI到视频重建方法在跨帧对象表示一致性和时间连贯性方面存在不足,导致重建视频质量不佳。
- SemVideo通过分层语义引导,从静态描述、运动叙述和整体摘要三个层面提取语义信息,提升重建效果。
- 实验结果表明,SemVideo在CC2017和HCP数据集上均优于现有方法,在语义对齐和时间一致性方面均有显著提升。
📝 摘要(中文)
从脑活动重建动态视觉体验,为探索人类视觉感知的神经机制提供了一条引人注目的途径。虽然基于fMRI的图像重建最近取得了显著进展,但将这种成功扩展到视频重建仍然是一个重大挑战。目前的fMRI到视频重建方法始终面临两个主要缺点:(i)跨帧的显著对象视觉表示不一致,导致外观不匹配;(ii)时间连贯性差,导致运动错位或突兀的帧转换。为了解决这些限制,我们引入了SemVideo,这是一个新颖的fMRI到视频重建框架,由分层语义信息引导。SemVideo的核心是SemMiner,一个分层引导模块,它从原始视频刺激中构建三个级别的语义线索:静态锚点描述、面向运动的叙述和整体摘要。利用这种语义引导,SemVideo包含三个关键组件:一个语义对齐解码器,将fMRI信号与来自SemMiner的CLIP风格嵌入对齐;一个运动适应解码器,使用一种新的三方注意力融合架构重建动态运动模式;以及一个条件视频渲染器,利用分层语义引导进行视频重建。在CC2017和HCP数据集上进行的实验表明,SemVideo在语义对齐和时间一致性方面都取得了优异的性能,为fMRI到视频重建设定了新的技术水平。
🔬 方法详解
问题定义:论文旨在解决从fMRI脑活动数据重建视频的问题。现有方法的主要痛点在于重建视频的帧间一致性差,具体表现为显著对象的视觉表示不一致以及时间连贯性不足,导致运动错位和帧转换突兀。
核心思路:论文的核心思路是利用视频本身蕴含的丰富语义信息来引导视频重建过程。通过构建分层的语义表示,将fMRI信号与视频的语义信息对齐,从而提升重建视频的质量和一致性。这种方法借鉴了自然语言处理中利用语义信息进行图像/视频生成的思想。
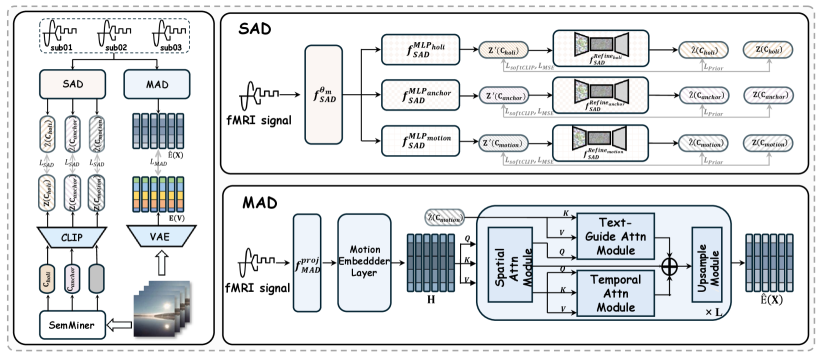
技术框架:SemVideo框架主要包含三个模块:SemMiner(分层语义挖掘器)、Semantic Alignment Decoder(语义对齐解码器)和 Motion Adaptation Decoder(运动适应解码器)以及 Conditional Video Render(条件视频渲染器)。SemMiner负责从原始视频中提取分层语义信息,包括静态锚点描述、运动叙述和整体摘要。Semantic Alignment Decoder将fMRI信号与SemMiner提取的CLIP风格嵌入对齐。Motion Adaptation Decoder使用三方注意力融合架构重建动态运动模式。Conditional Video Render利用分层语义引导进行最终的视频重建。
关键创新:该论文的关键创新在于提出了一个分层语义引导的fMRI到视频重建框架。具体来说,SemMiner模块能够从视频中提取多层次的语义信息,为后续的视频重建提供更丰富的指导。此外,Motion Adaptation Decoder中提出的三方注意力融合架构能够更好地捕捉视频中的动态运动模式。
关键设计:SemMiner模块使用预训练的CLIP模型提取视频帧的视觉特征,并使用自然语言处理技术生成静态描述、运动叙述和整体摘要。Semantic Alignment Decoder使用线性回归模型将fMRI信号映射到CLIP嵌入空间。Motion Adaptation Decoder使用Transformer架构,并引入了三方注意力机制来融合不同层次的语义信息。Conditional Video Render的具体实现细节未知,但推测使用了GAN或者扩散模型等生成模型。
🖼️ 关键图片


📊 实验亮点
SemVideo在CC2017和HCP数据集上进行了实验,结果表明其在语义对齐和时间一致性方面均优于现有方法,实现了fMRI到视频重建的新技术水平。具体的性能指标和提升幅度在论文中未明确给出,但摘要强调了其在两个关键指标上的优越性。
🎯 应用场景
该研究具有广泛的应用前景,包括:(1) 深入理解人类视觉感知的神经机制;(2) 开发新型脑机接口,帮助残疾人士恢复视觉功能;(3) 辅助精神疾病的诊断和治疗,例如通过重建患者的视觉体验来了解其认知过程;(4) 用于视频内容理解和生成,例如根据脑活动生成特定风格的视频。
📄 摘要(原文)
Reconstructing dynamic visual experiences from brain activity provides a compelling avenue for exploring the neural mechanisms of human visual perception. While recent progress in fMRI-based image reconstruction has been notable, extending this success to video reconstruction remains a significant challenge. Current fMRI-to-video reconstruction approaches consistently encounter two major shortcomings: (i) inconsistent visual representations of salient objects across frames, leading to appearance mismatches; (ii) poor temporal coherence, resulting in motion misalignment or abrupt frame transitions. To address these limitations, we introduce SemVideo, a novel fMRI-to-video reconstruction framework guided by hierarchical semantic information. At the core of SemVideo is SemMiner, a hierarchical guidance module that constructs three levels of semantic cues from the original video stimulus: static anchor descriptions, motion-oriented narratives, and holistic summaries. Leveraging this semantic guidance, SemVideo comprises three key components: a Semantic Alignment Decoder that aligns fMRI signals with CLIP-style embeddings derived from SemMiner, a Motion Adaptation Decoder that reconstructs dynamic motion patterns using a novel tripartite attention fusion architecture, and a Conditional Video Render that leverages hierarchical semantic guidance for video reconstruction. Experiments conducted on the CC2017 and HCP datasets demonstrate that SemVideo achieves superior performance in both semantic alignment and temporal consistency, setting a new state-of-the-art in fMRI-to-video reconstruction.