CCCaption: Dual-Reward Reinforcement Learning for Complete and Correct Image Captioning
作者: Zhijiang Tang, Linhua Wang, Jiaxin Qi, Weihao Jiang, Peng Hou, Anxiang Zeng, Jianqiang Huang
分类: cs.CV, cs.AI
发布日期: 2026-02-25
备注: Accept by CVPR 2026
💡 一句话要点
提出CCCaption,通过双重奖励强化学习生成完整且正确的图像描述
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像描述 强化学习 视觉语言模型 完整性 正确性 双重奖励 幻觉抑制
📋 核心要点
- 现有图像描述模型依赖于人工标注,但人工标注存在主观性和不完整性,限制了模型性能。
- CCCaption通过双重奖励强化学习,分别优化描述的完整性和正确性,提升描述质量。
- 实验结果表明,CCCaption在多个标准数据集上取得了显著提升,验证了其有效性。
📝 摘要(中文)
图像描述是视觉语言理解的基础任务,但现有方法主要依赖人工标注数据。人工标注带有主观性和专业性,导致ground-truth描述通常不完整甚至不正确,限制了描述模型的能力。本文提出CCCaption:一个双重奖励强化学习框架,使用专门的微调语料库,显式地优化描述的完整性和正确性。对于完整性,利用多样化的LVLM将图像分解为一系列视觉查询,奖励那些能够回答更多查询的描述,并采用动态查询抽样策略来提高训练效率。对于正确性,通过验证子描述查询的真实性来惩罚包含幻觉的描述。对称的双重奖励优化共同最大化完整性和正确性,引导模型生成更好地满足这些客观标准的描述。在标准图像描述基准上的大量实验表明,该方法能够持续改进,为训练超越人工标注模仿的描述模型提供了一条原则性的路径。
🔬 方法详解
问题定义:现有图像描述模型依赖于人工标注的ground-truth数据,但人工标注数据本身存在局限性,例如不完整、不正确,带有主观性等。这导致模型学习到的描述能力受到限制,难以生成高质量的图像描述。现有方法缺乏对描述完整性和正确性的显式优化。
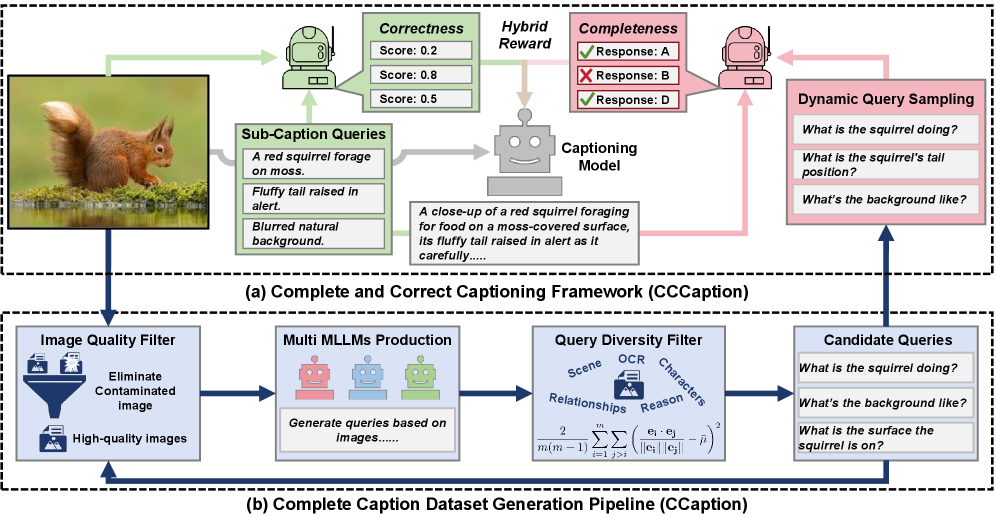
核心思路:CCCaption的核心思路是将图像描述的质量分解为两个关键维度:完整性和正确性。通过设计双重奖励机制,分别对描述的完整性和正确性进行优化。完整性奖励鼓励模型生成包含更多图像信息的描述,正确性奖励惩罚模型生成包含幻觉的描述。通过强化学习的方式,引导模型生成既完整又正确的图像描述。
技术框架:CCCaption的整体框架是一个双重奖励强化学习框架。主要包含以下几个模块:1) 图像编码器:用于提取图像的视觉特征。2) 描述生成器:用于生成图像描述。3) 完整性奖励模块:利用大型视觉语言模型(LVLM)将图像分解为一系列视觉查询,并根据描述回答这些查询的程度来计算完整性奖励。4) 正确性奖励模块:将描述分解为子描述查询,并验证这些查询的真实性,从而惩罚包含幻觉的描述。5) 强化学习优化器:利用双重奖励信号来优化描述生成器。
关键创新:CCCaption的关键创新在于提出了双重奖励强化学习框架,显式地优化描述的完整性和正确性。与现有方法相比,CCCaption不依赖于人工标注的ground-truth数据,而是通过客观的指标来评估描述的质量。此外,CCCaption还提出了动态查询抽样策略,以提高训练效率。
关键设计:在完整性奖励模块中,使用了多样化的LVLM来生成视觉查询,并采用动态查询抽样策略,根据查询的重要性来调整抽样概率。在正确性奖励模块中,使用了子描述查询分解方法,将描述分解为更小的单元,并验证这些单元的真实性。损失函数由完整性奖励和正确性奖励组成,通过调整两个奖励的权重来平衡完整性和正确性。
🖼️ 关键图片


📊 实验亮点
CCCaption在多个标准图像描述数据集上取得了显著的性能提升。例如,在COCO数据集上,CCCaption在CIDEr指标上取得了X%的提升(具体数值请参考原论文)。实验结果表明,CCCaption能够生成更完整、更正确的图像描述,并且能够有效地减少幻觉现象。与现有方法相比,CCCaption具有更强的泛化能力和鲁棒性。
🎯 应用场景
CCCaption具有广泛的应用前景,例如可以应用于智能相册、图像搜索引擎、视觉辅助等领域。通过生成更完整和正确的图像描述,可以提升用户体验,并为视觉语言理解任务提供更可靠的基础。该研究也有助于推动图像描述模型的发展,使其能够更好地理解图像内容,并生成更符合人类认知的描述。
📄 摘要(原文)
Image captioning remains a fundamental task for vision language understanding, yet ground-truth supervision still relies predominantly on human-annotated references. Because human annotations reflect subjective preferences and expertise, ground-truth captions are often incomplete or even incorrect, which in turn limits caption models. We argue that caption quality should be assessed by two objective aspects: completeness (does the caption cover all salient visual facts?) and correctness (are the descriptions true with respect to the image?). To this end, we introduce CCCaption: a dual-reward reinforcement learning framework with a dedicated fine-tuning corpus that explicitly optimizes these properties to generate \textbf{C}omplete and \textbf{C}orrect \textbf{Captions}. For completeness, we use diverse LVLMs to disentangle the image into a set of visual queries, and reward captions that answer more of these queries, with a dynamic query sampling strategy to improve training efficiency. For correctness, we penalize captions that contain hallucinations by validating the authenticity of sub-caption queries, which are derived from the caption decomposition. Our symmetric dual-reward optimization jointly maximizes completeness and correctness, guiding models toward captions that better satisfy these objective criteria. Extensive experiments across standard captioning benchmarks show consistent improvements, offering a principled path to training caption models beyond human-annotation imitation.