Human Video Generation from a Single Image with 3D Pose and View Control
作者: Tiantian Wang, Chun-Han Yao, Tao Hu, Mallikarjun Byrasandra Ramalinga Reddy, Ming-Hsuan Yang, Varun Jampani
分类: cs.CV
发布日期: 2026-02-24
💡 一句话要点
提出HVG模型,通过单张图像生成具有3D姿态和视角控制的高质量人体视频。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 人体视频生成 单图生成视频 3D姿态控制 扩散模型 多视角一致性
📋 核心要点
- 现有方法在单图生成人体视频时,难以推断视角一致且依赖于运动的服装褶皱。
- HVG模型通过关节姿态调制、视角和时间对齐以及渐进式时空采样,实现高质量人体视频生成。
- 实验证明,HVG在生成高质量4D人体视频方面优于现有方法,适用于各种人体图像和姿态输入。
📝 摘要(中文)
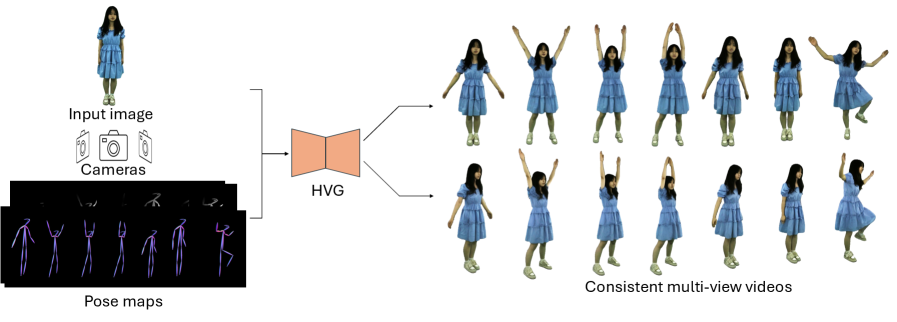
本文提出了一种名为Human Video Generation in 4D (HVG)的潜在视频扩散模型,旨在从单张图像生成高质量、多视角、时空一致的人体视频,并支持3D姿态和视角控制。HVG通过三个关键设计实现这一目标:(i) 关节姿态调制,通过新颖的双维度骨骼图捕捉3D关节的解剖关系,并通过引入3D信息解决跨视角的自遮挡问题;(ii) 视角和时间对齐,确保多视角一致性以及参考图像和姿态序列之间的对齐,以实现帧间稳定性;(iii) 具有时间对齐的渐进式时空采样,以保持长多视角动画中的平滑过渡。在图像到视频任务上的大量实验表明,HVG在从各种人体图像和姿态输入生成高质量4D人体视频方面优于现有方法。
🔬 方法详解
问题定义:论文旨在解决从单张图像生成高质量、多视角、时空一致的人体视频的问题,并支持3D姿态和视角控制。现有方法在处理人体视频生成时,尤其是在从单张图像推断视角一致且依赖于运动的服装褶皱方面面临挑战。此外,保持生成视频的时空一致性也是一个难题。
核心思路:论文的核心思路是利用潜在视频扩散模型,并结合3D人体姿态信息,通过三个关键设计来解决上述问题。首先,通过关节姿态调制来捕捉3D关节的解剖关系并解决自遮挡问题。其次,通过视角和时间对齐来确保多视角一致性和帧间稳定性。最后,通过渐进式时空采样来保持长多视角动画中的平滑过渡。
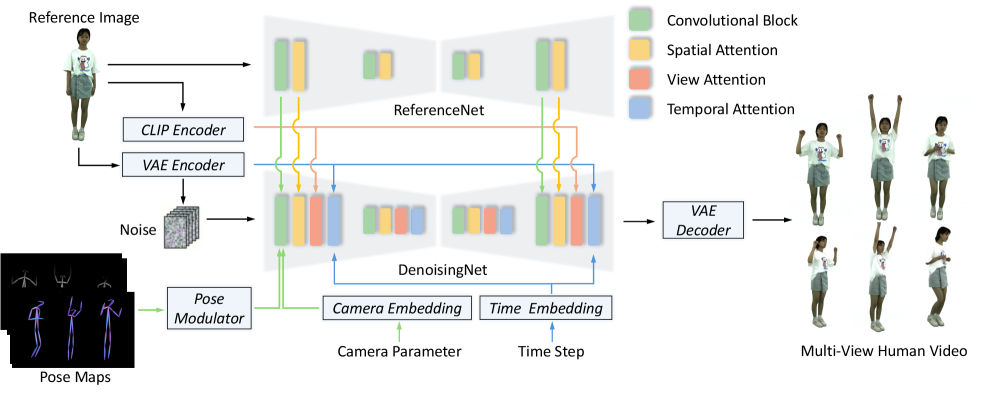
技术框架:HVG的整体框架是一个潜在视频扩散模型,包含以下主要模块:1) 图像编码器,用于将输入图像编码到潜在空间;2) 姿态编码器,用于将3D姿态序列编码到潜在空间;3) 扩散模型,用于在潜在空间中生成视频;4) 解码器,用于将潜在空间中的视频解码为像素空间中的视频。该模型通过关节姿态调制模块将3D姿态信息融入到扩散过程中,并通过视角和时间对齐模块来保证生成视频的多视角一致性和帧间稳定性。
关键创新:论文的关键创新在于以下几个方面:1) 提出了双维度骨骼图,用于捕捉3D关节的解剖关系;2) 引入了3D信息来解决跨视角的自遮挡问题;3) 提出了视角和时间对齐模块,用于确保多视角一致性和帧间稳定性;4) 提出了渐进式时空采样策略,用于保持长多视角动画中的平滑过渡。
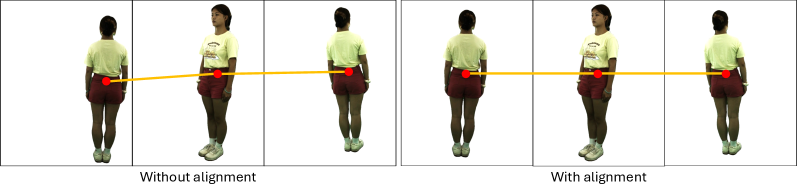
关键设计:关节姿态调制模块使用双维度骨骼图来表示3D关节的解剖关系,该骨骼图包含关节之间的距离和角度信息。视角和时间对齐模块使用可变形卷积来对齐参考图像和姿态序列。渐进式时空采样策略通过逐步增加采样分辨率来生成高质量的视频。损失函数包括重建损失、对抗损失和感知损失,用于提高生成视频的质量和真实感。
🖼️ 关键图片
📊 实验亮点
论文通过大量实验验证了HVG模型的有效性。在图像到视频任务上,HVG在生成高质量4D人体视频方面显著优于现有方法。具体来说,HVG在多个指标上取得了SOTA的结果,包括FID、PSNR和SSIM等。实验结果表明,HVG能够生成视角一致、时空连贯且具有逼真服装褶皱的人体视频。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏开发、电影制作等领域,例如,可以根据单张照片和用户指定的姿态生成逼真的人体动画,用于虚拟形象定制或虚拟试衣等应用。此外,该技术还可以用于生成训练数据,以改进人体姿态估计和动作识别等任务的性能。未来,该技术有望进一步扩展到其他类型的视频生成任务,例如,生成动物或物体的动画。
📄 摘要(原文)
Recent diffusion methods have made significant progress in generating videos from single images due to their powerful visual generation capabilities. However, challenges persist in image-to-video synthesis, particularly in human video generation, where inferring view-consistent, motion-dependent clothing wrinkles from a single image remains a formidable problem. In this paper, we present Human Video Generation in 4D (HVG), a latent video diffusion model capable of generating high-quality, multi-view, spatiotemporally coherent human videos from a single image with 3D pose and view control. HVG achieves this through three key designs: (i) Articulated Pose Modulation, which captures the anatomical relationships of 3D joints via a novel dual-dimensional bone map and resolves self-occlusions across views by introducing 3D information; (ii) View and Temporal Alignment, which ensures multi-view consistency and alignment between a reference image and pose sequences for frame-to-frame stability; and (iii) Progressive Spatio-Temporal Sampling with temporal alignment to maintain smooth transitions in long multi-view animations. Extensive experiments on image-to-video tasks demonstrate that HVG outperforms existing methods in generating high-quality 4D human videos from diverse human images and pose inputs.