UDVideoQA: A Traffic Video Question Answering Dataset for Multi-Object Spatio-Temporal Reasoning in Urban Dynamics
作者: Joseph Raj Vishal, Nagasiri Poluri, Katha Naik, Rutuja Patil, Kashyap Hegde Kota, Krishna Vinod, Prithvi Jai Ramesh, Mohammad Farhadi, Yezhou Yang, Bharatesh Chakravarthi
分类: cs.CV
发布日期: 2026-02-24
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出UDVideoQA数据集,用于城市交通视频中多目标时空推理的视频问答任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 城市交通 视频问答 多目标跟踪 时空推理 数据集 视频语言模型 因果推理
📋 核心要点
- 现有视频语言模型在理解城市交通中复杂的多智能体动态方面存在挑战,缺乏针对性的数据集。
- UDVideoQA数据集通过真实交通视频、事件驱动的动态模糊和分层推理问答对,提供了一个全面的评估基准。
- 实验表明,现有模型在视觉基础和因果推理之间存在差距,微调后的Qwen2.5-VL 7B模型可有效弥补这一差距。
📝 摘要(中文)
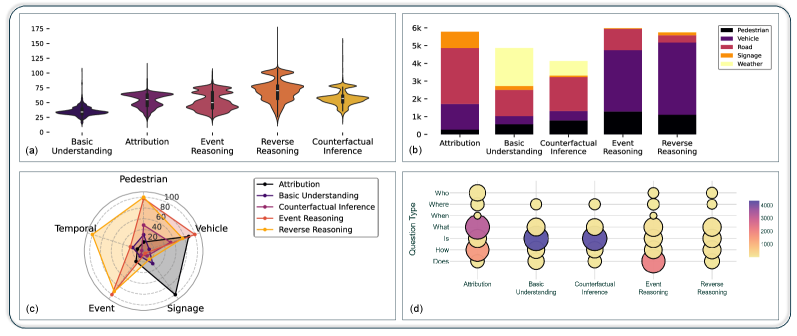
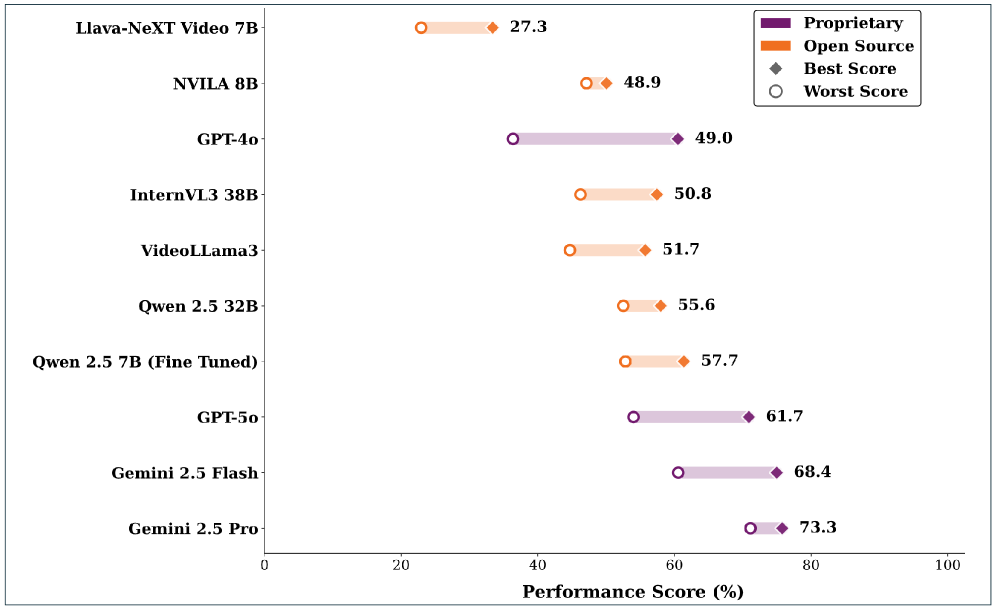
本文提出了城市动态视频问答(UDVideoQA)数据集,旨在解决视频语言模型在理解复杂、多智能体城市交通动态方面的挑战。该数据集包含16小时的交通录像,覆盖多种交通、天气和光照条件。采用事件驱动的动态模糊技术保护隐私,同时保证场景的真实性。数据集包含2.8万个问答对,这些问答对基于8小时的密集标注视频生成,平均每秒一个问题。其分类体系遵循分层推理级别,从基本理解和归因到事件推理、逆向推理和反事实推理,从而能够系统地评估视觉基础和因果推理。对10个SOTA VideoLM在UDVideoQA上进行了基准测试,并在一个补充的视频问题生成基准上测试了8个模型。结果表明,存在持续的感知-推理差距,擅长抽象推理的模型通常在基本视觉基础方面失败。虽然像Gemini Pro这样的模型实现了最高的零样本准确率,但在UDVideoQA上微调较小的Qwen2.5-VL 7B模型可以弥合这一差距,实现与专有系统相当的性能。在VideoQGen中,Gemini 2.5 Pro和Qwen3 Max生成了最相关和复杂的问题,但所有模型都表现出有限的语言多样性,突显了以人为本的评估的必要性。UDVideoQA套件,包括数据集、标注工具以及VideoQA和VideoQGen的基准,为推进稳健、注重隐私和真实的多模态推理奠定了基础。
🔬 方法详解
问题定义:现有视频问答模型难以有效理解和推理城市交通视频中复杂的多目标时空关系。现有方法在视觉感知和高层次推理之间存在脱节,缺乏针对城市交通场景的细粒度理解能力。同时,隐私保护也是一个重要的问题,需要避免泄露车辆和行人的敏感信息。
核心思路:论文的核心思路是构建一个高质量、大规模的城市交通视频问答数据集,该数据集不仅包含丰富的视觉信息,还涵盖了不同层次的推理能力,包括基本理解、事件推理、逆向推理和反事实推理。通过在该数据集上训练和评估模型,可以促进视频语言模型在城市交通场景中的应用。
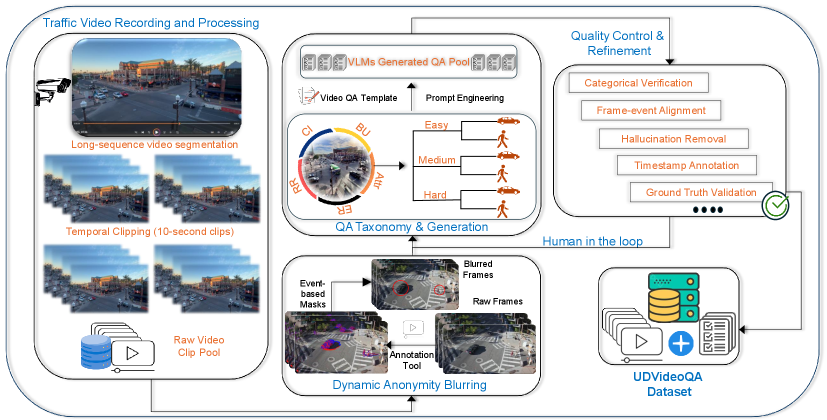
技术框架:UDVideoQA数据集的构建流程包括以下几个主要阶段:1) 数据采集:从多个城市路口采集16小时的交通视频。2) 隐私保护:采用事件驱动的动态模糊技术,对视频中的车辆和行人进行模糊处理,保护隐私。3) 问题生成:基于8小时的密集标注视频,生成2.8万个问答对,平均每秒一个问题。4) 问题分类:将问题分为不同的推理级别,包括基本理解、事件推理、逆向推理和反事实推理。5) 模型评估:在UDVideoQA数据集上评估多个SOTA VideoLM的性能。
关键创新:UDVideoQA数据集的关键创新点在于:1) 专注于城市交通场景,填补了现有视频问答数据集的空白。2) 采用事件驱动的动态模糊技术,在保护隐私的同时保证了场景的真实性。3) 构建了分层推理问题分类体系,可以系统地评估模型的视觉基础和因果推理能力。4) 同时提供了视频问答和视频问题生成两个基准,促进了多模态推理的研究。
关键设计:在数据采集方面,选择了多个城市路口,覆盖了不同的交通、天气和光照条件。在隐私保护方面,采用了事件驱动的动态模糊技术,只对视频中发生变化的区域进行模糊处理,避免过度模糊导致信息丢失。在问题生成方面,采用了统一的标注流程,保证了问答对的质量和一致性。在模型评估方面,选择了多个SOTA VideoLM,并采用了零样本和微调两种评估方式。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有SOTA VideoLM在UDVideoQA数据集上表现出明显的感知-推理差距。Gemini Pro在零样本设置下表现最佳,但微调后的Qwen2.5-VL 7B模型可以达到与其相当的性能,表明小模型通过针对性训练也能取得优异效果。在视频问题生成方面,Gemini 2.5 Pro和Qwen3 Max生成的问题更相关和复杂,但语言多样性有限。
🎯 应用场景
该研究成果可应用于智能交通系统、自动驾驶、城市规划和公共安全等领域。通过提升视频语言模型对城市交通视频的理解和推理能力,可以实现更智能的交通管理、更安全的自动驾驶和更高效的城市规划。此外,该数据集还可以用于研究视频问答和视频问题生成等相关任务。
📄 摘要(原文)
Understanding the complex, multi-agent dynamics of urban traffic remains a fundamental challenge for video language models. This paper introduces Urban Dynamics VideoQA, a benchmark dataset that captures the unscripted real-world behavior of dynamic urban scenes. UDVideoQA is curated from 16 hours of traffic footage recorded at multiple city intersections under diverse traffic, weather, and lighting conditions. It employs an event-driven dynamic blur technique to ensure privacy preservation without compromising scene fidelity. Using a unified annotation pipeline, the dataset contains 28K question-answer pairs generated across 8 hours of densely annotated video, averaging one question per second. Its taxonomy follows a hierarchical reasoning level, spanning basic understanding and attribution to event reasoning, reverse reasoning, and counterfactual inference, enabling systematic evaluation of both visual grounding and causal reasoning. Comprehensive experiments benchmark 10 SOTA VideoLMs on UDVideoQA and 8 models on a complementary video question generation benchmark. Results reveal a persistent perception-reasoning gap, showing models that excel in abstract inference often fail with fundamental visual grounding. While models like Gemini Pro achieve the highest zero-shot accuracy, fine-tuning the smaller Qwen2.5-VL 7B model on UDVideoQA bridges this gap, achieving performance comparable to proprietary systems. In VideoQGen, Gemini 2.5 Pro, and Qwen3 Max generate the most relevant and complex questions, though all models exhibit limited linguistic diversity, underscoring the need for human-centric evaluation. The UDVideoQA suite, including the dataset, annotation tools, and benchmarks for both VideoQA and VideoQGen, provides a foundation for advancing robust, privacy-aware, and real-world multimodal reasoning. UDVideoQA is available at https://ud-videoqa.github.io/UD-VideoQA/UD-VideoQA/.