Skullptor: High Fidelity 3D Head Reconstruction in Seconds with Multi-View Normal Prediction
作者: Noé Artru, Rukhshanda Hussain, Emeline Got, Alexandre Messier, David B. Lindell, Abdallah Dib
分类: cs.CV, cs.GR
发布日期: 2026-02-24
备注: 14 pages, 8 figures, to be published in proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
💡 一句话要点
Skullptor:基于多视角法线预测的快速高保真3D头部重建
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D头部重建 多视角法线预测 逆渲染 几何先验 交叉视角注意力
📋 核心要点
- 现有3D头部重建方法在高保真度、计算效率和相机需求之间存在权衡,传统方法计算成本高,新兴方法细节不足。
- 提出一种混合方法,结合单目基础模型的效率和优化方法的细节,通过多视角法线预测提供几何先验。
- 实验表明,该方法在降低相机需求和计算成本的同时,实现了与密集视角摄影测量法相当的高保真重建效果。
📝 摘要(中文)
从图像重建高保真3D头部几何对于广泛的应用至关重要,但现有方法面临根本性的限制。传统摄影测量法能够实现卓越的细节,但需要大量的相机阵列(25-200+个视角)、大量的计算以及在面部毛发等具有挑战性的区域进行手动清理。最近的替代方案存在根本性的权衡:基础模型能够实现高效的单图像重建,但缺乏精细的几何细节,而基于优化的方法能够实现更高的保真度,但需要密集的视角和昂贵的计算。我们通过一种混合方法弥合了这一差距,该方法结合了两种范例的优势。我们的方法引入了一种多视角表面法线预测模型,该模型通过交叉视角注意力扩展了单目基础模型,从而在正向传递中生成几何一致的法线。然后,我们在逆渲染优化框架中利用这些预测作为强大的几何先验,以恢复高频表面细节。我们的方法优于最先进的单图像和多视角方法,实现了与密集视角摄影测量法相当的高保真重建,同时降低了相机需求和计算成本。代码和模型将会发布。
🔬 方法详解
问题定义:论文旨在解决从少量图像中高效、高保真地重建3D头部几何的问题。现有方法,如传统摄影测量法,需要大量相机和计算资源,且在处理面部毛发等复杂区域时需要手动清理。而基于单张图像的重建方法虽然高效,但缺乏精细的几何细节。因此,如何在计算效率、相机需求和重建质量之间取得平衡是本研究要解决的核心问题。
核心思路:论文的核心思路是结合单目基础模型的效率和优化方法的细节。首先,利用多视角法线预测模型从少量图像中预测几何一致的表面法线。然后,将这些预测的法线作为强几何先验,在逆渲染优化框架中进行优化,从而恢复高频表面细节。这种混合方法旨在克服现有方法的局限性,实现高效、高保真的3D头部重建。
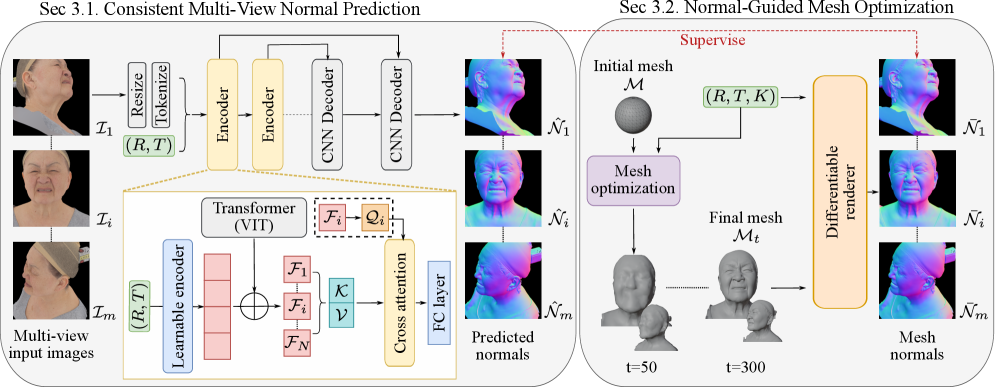
技术框架:整体框架包含两个主要阶段:1) 多视角表面法线预测:使用一个基于交叉视角注意力的神经网络,从多张输入图像中预测表面法线图。该网络以单目基础模型为基础,通过交叉视角注意力机制来保证法线的一致性。2) 逆渲染优化:将预测的法线图作为几何先验,在一个逆渲染优化框架中进行优化。该框架通过最小化渲染图像与输入图像之间的差异,以及法线图与预测法线之间的差异,来恢复高频表面细节。
关键创新:论文的关键创新在于多视角表面法线预测模型。该模型通过交叉视角注意力机制,能够有效地融合来自不同视角的图像信息,从而预测出几何一致的表面法线。与传统的单目法线预测方法相比,该模型能够更好地利用多视角信息,提高法线预测的准确性。与直接进行3D重建相比,先预测法线再进行优化,可以更好地利用几何先验,提高重建质量。
关键设计:多视角法线预测模型使用了Transformer架构,其中交叉视角注意力模块允许网络在不同视角的特征之间进行信息交换。损失函数包括一个法线一致性损失,用于鼓励预测的法线在不同视角下保持一致。逆渲染优化框架使用了可微分渲染器,允许通过梯度下降来优化3D模型。优化的目标函数包括一个光度损失(photometric loss)和一个法线损失(normal loss),分别用于保证渲染图像与输入图像的一致性,以及法线图与预测法线的一致性。
🖼️ 关键图片
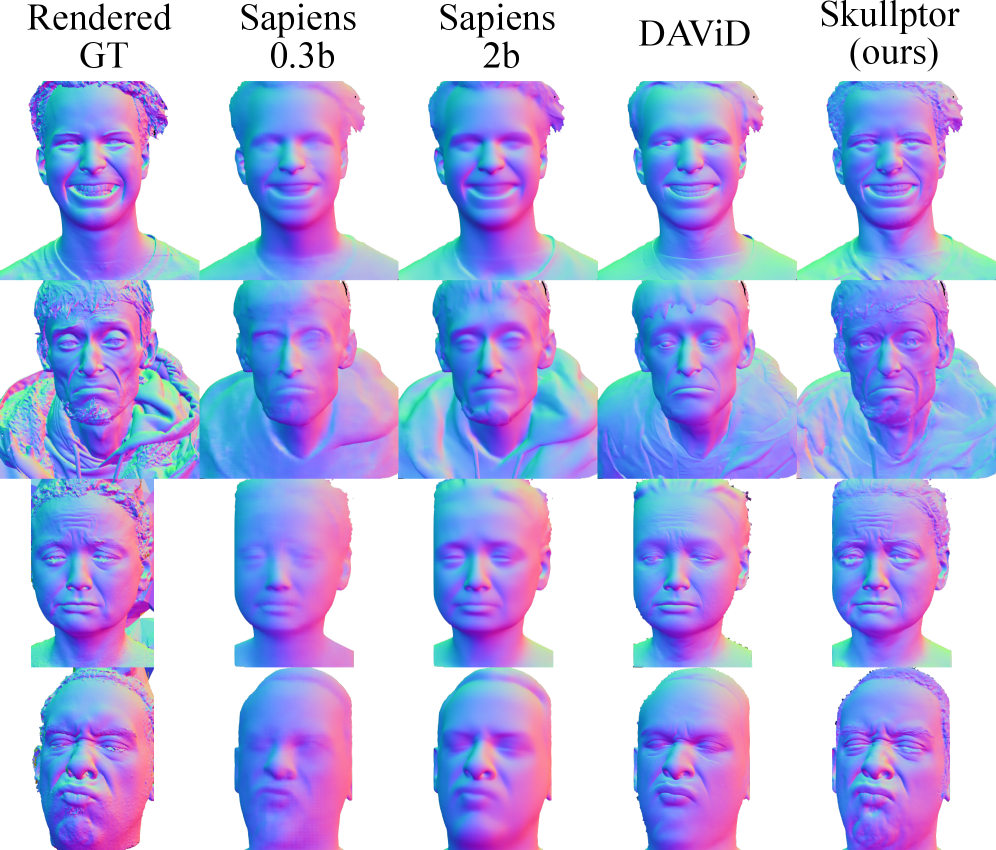

📊 实验亮点
该方法在保证高保真重建质量的同时,显著降低了对相机数量和计算资源的需求。实验结果表明,该方法在重建质量上与需要大量相机阵列的传统摄影测量法相当,同时优于现有的单图像和多视角重建方法。具体性能数据将在论文中详细展示,包括在标准数据集上的定量评估和视觉效果对比。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏、电影制作、人脸识别、个性化头像生成等领域。通过降低对相机数量和计算资源的需求,使得高保真3D头部重建技术能够更便捷地应用于移动设备和实时应用中,具有重要的实际应用价值和广阔的市场前景。
📄 摘要(原文)
Reconstructing high-fidelity 3D head geometry from images is critical for a wide range of applications, yet existing methods face fundamental limitations. Traditional photogrammetry achieves exceptional detail but requires extensive camera arrays (25-200+ views), substantial computation, and manual cleanup in challenging areas like facial hair. Recent alternatives present a fundamental trade-off: foundation models enable efficient single-image reconstruction but lack fine geometric detail, while optimization-based methods achieve higher fidelity but require dense views and expensive computation. We bridge this gap with a hybrid approach that combines the strengths of both paradigms. Our method introduces a multi-view surface normal prediction model that extends monocular foundation models with cross-view attention to produce geometrically consistent normals in a feed-forward pass. We then leverage these predictions as strong geometric priors within an inverse rendering optimization framework to recover high-frequency surface details. Our approach outperforms state-of-the-art single-image and multi-view methods, achieving high-fidelity reconstruction on par with dense-view photogrammetry while reducing camera requirements and computational cost. The code and model will be released.