OmniOCR: Generalist OCR for Ethnic Minority Languages
作者: Bonan Liu, Zeyu Zhang, Bingbing Meng, Han Wang, Hanshuo Zhang, Chengping Wang, Daji Ergu, Ying Cai
分类: cs.CV
发布日期: 2026-02-24
🔗 代码/项目: GITHUB
💡 一句话要点
OmniOCR:面向少数民族语言的通用OCR框架,提升低资源场景识别精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: OCR 少数民族语言 低资源学习 动态低秩适应 参数效率
📋 核心要点
- 现有OCR方法主要集中在拉丁文和中文等资源丰富的文字上,对少数民族语言的研究不足,面临数据稀缺和文字复杂性挑战。
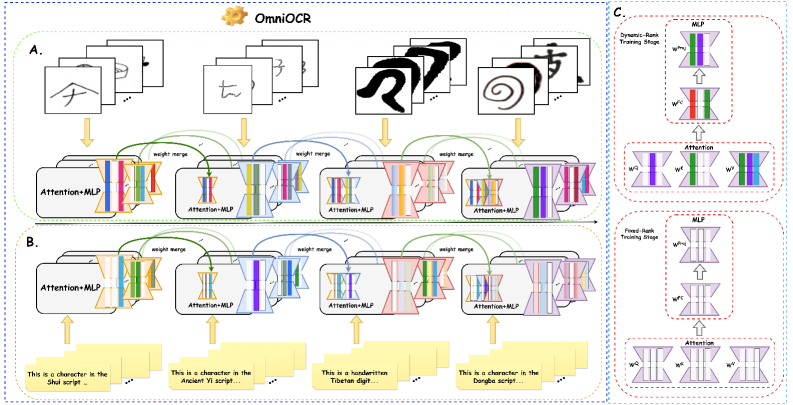
- OmniOCR通过引入动态低秩适应(Dynamic LoRA)机制,实现模型容量在不同层和不同文字间的有效分配和知识保留。
- 实验结果表明,OmniOCR在多个少数民族语言数据集上超越了零样本基础模型和传统后训练方法,精度提升显著。
📝 摘要(中文)
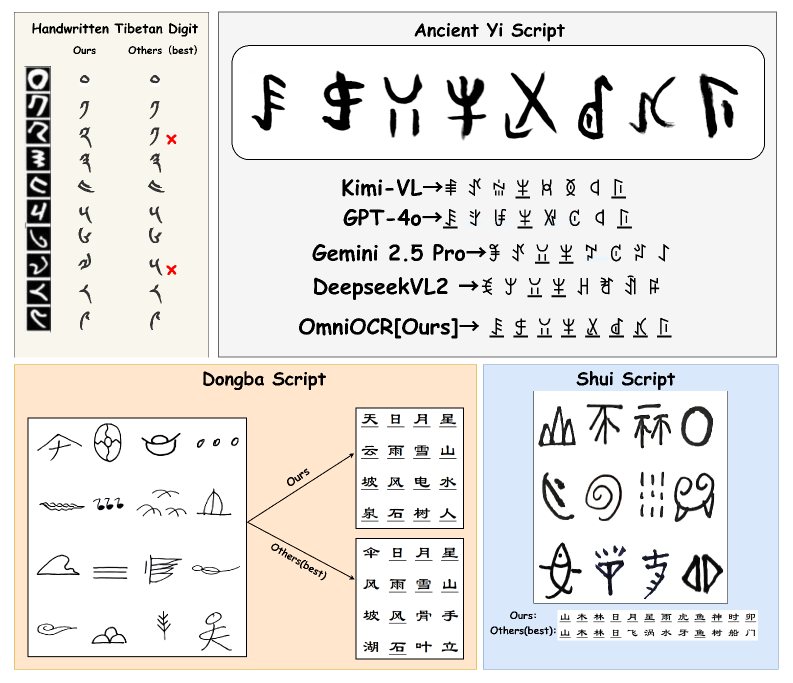
本文提出OmniOCR,一个面向少数民族文字的通用OCR框架。由于少数民族文字书写系统复杂、标注数据稀缺,以及存在多样化的历史和现代形式,导致在低资源或零样本场景下的泛化能力面临挑战。OmniOCR引入动态低秩适应(Dynamic LoRA)来跨层和跨文字分配模型容量,从而实现有效的适应并保留知识。稀疏正则化剪枝冗余更新,确保紧凑高效的适应,而无需额外的推理成本。在TibetanMNIST、Shui、古代彝文和东巴文上的评估表明,OmniOCR优于零样本基础模型和标准后训练,以卓越的参数效率实现了最先进的精度,并且与最先进的基线模型相比,在这些四个数据集上提高了39%-66%的准确率。
🔬 方法详解
问题定义:现有OCR方法在处理少数民族语言时,面临数据稀缺、文字复杂性以及历史和现代形式多样化的问题,导致模型在低资源或零样本场景下的泛化能力较差。现有方法难以在参数效率和模型性能之间取得平衡,无法有效适应不同少数民族语言的特点。
核心思路:OmniOCR的核心思路是利用动态低秩适应(Dynamic LoRA)机制,在预训练模型的基础上,针对不同的少数民族语言进行高效的参数调整。通过动态地分配模型容量,使模型能够更好地适应特定语言的特征,同时保留预训练模型中已有的知识。稀疏正则化用于剪枝冗余更新,进一步提升参数效率。
技术框架:OmniOCR框架主要包括预训练模型、动态LoRA适配模块和稀疏正则化模块。首先,使用大规模数据集预训练一个通用OCR模型。然后,针对每个少数民族语言,使用少量标注数据,通过动态LoRA适配模块调整模型参数。该模块根据不同层和不同语言的特点,动态地分配LoRA的秩,从而实现更精细的参数调整。最后,使用稀疏正则化模块对LoRA的更新进行剪枝,去除冗余的参数更新,进一步提高模型的参数效率。
关键创新:OmniOCR的关键创新在于动态低秩适应(Dynamic LoRA)机制。传统的LoRA方法对所有层使用相同的秩,无法充分利用不同层的特征。动态LoRA根据不同层和不同语言的特点,动态地分配LoRA的秩,从而实现更精细的参数调整。此外,稀疏正则化模块能够有效地剪枝冗余的参数更新,进一步提高模型的参数效率。
关键设计:动态LoRA适配模块的关键设计在于如何确定每个层和每个语言的LoRA秩。论文可能采用了一种基于梯度或信息熵的方法,根据每个层对特定语言的贡献程度,动态地调整LoRA的秩。稀疏正则化模块的关键设计在于如何选择合适的正则化系数,以平衡模型的精度和参数效率。损失函数包括交叉熵损失和稀疏正则化损失两部分。
🖼️ 关键图片

📊 实验亮点
OmniOCR在TibetanMNIST、Shui、古代彝文和东巴文四个数据集上进行了评估,实验结果表明,OmniOCR显著优于零样本基础模型和标准后训练方法。与最先进的基线模型相比,OmniOCR在这些数据集上实现了39%-66%的准确率提升,同时保持了卓越的参数效率。这些结果表明,OmniOCR在低资源少数民族语言OCR任务中具有显著的优势。
🎯 应用场景
OmniOCR在文化遗产保护、民族语言教育、智能翻译等领域具有广泛的应用前景。它可以用于识别古籍文献中的少数民族文字,帮助研究人员更好地了解历史文化。同时,OmniOCR可以应用于民族语言的在线教育平台,为学生提供更便捷的学习资源。此外,OmniOCR还可以用于开发智能翻译系统,促进不同民族之间的交流与合作。
📄 摘要(原文)
Optical character recognition (OCR) has advanced rapidly with deep learning and multimodal models, yet most methods focus on well-resourced scripts such as Latin and Chinese. Ethnic minority languages remain underexplored due to complex writing systems, scarce annotations, and diverse historical and modern forms, making generalization in low-resource or zero-shot settings challenging. To address these challenges, we present OmniOCR, a universal framework for ethnic minority scripts. OmniOCR introduces Dynamic Low-Rank Adaptation (Dynamic LoRA) to allocate model capacity across layers and scripts, enabling effective adaptation while preserving knowledge.A sparsity regularization prunes redundant updates, ensuring compact and efficient adaptation without extra inference cost. Evaluations on TibetanMNIST, Shui, ancient Yi, and Dongba show that OmniOCR outperforms zero-shot foundation models and standard post training, achieving state-of-the-art accuracy with superior parameter efficiency, and compared with the state-of-the-art baseline models, it improves accuracy by 39%-66% on these four datasets. Code: https://github.com/AIGeeksGroup/OmniOCR.