From Perception to Action: An Interactive Benchmark for Vision Reasoning
作者: Yuhao Wu, Maojia Song, Yihuai Lan, Lei Wang, Zhiqiang Hu, Yao Xiao, Heng Zhou, Weihua Zheng, Dylan Raharja, Soujanya Poria, Roy Ka-Wei Lee
分类: cs.CV
发布日期: 2026-02-24
备注: Work in processing. Website: https://social-ai-studio.github.io/CHAIN/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出CHAIN基准测试,用于评估视觉推理模型在交互式物理环境中的行动能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视觉推理 交互式基准 物理模拟 具身智能 视觉-语言模型
📋 核心要点
- 现有VLM评估缺乏对物理结构和因果约束的考量,无法有效评估智能体在动态环境中基于物理规则进行推理和行动的能力。
- CHAIN基准测试通过构建交互式的3D物理环境,要求模型理解物理约束,规划并执行结构化的动作序列,从而实现主动问题解决。
- 实验结果表明,现有VLM模型在理解物理结构和因果约束方面存在不足,难以生成可靠的长期规划并有效执行动作。
📝 摘要(中文)
为了弥补现有视觉-语言模型(VLM)评估侧重于结构无关、单轮设置的不足,本文提出了动作与交互的因果层级(CHAIN)基准测试。CHAIN是一个交互式的3D物理驱动测试平台,旨在评估模型理解、规划和执行基于物理约束的结构化动作序列的能力。CHAIN将评估从被动感知转变为主动问题解决,涵盖了诸如互锁机械谜题以及3D堆叠和打包等任务。对最先进的VLM和基于扩散的模型进行了统一交互设置下的全面研究。结果表明,性能最佳的模型仍然难以理解物理结构和因果约束,常常无法产生可靠的长期规划,并且不能稳健地将感知到的结构转化为有效的行动。
🔬 方法详解
问题定义:现有视觉-语言模型(VLM)的评估主要集中在结构无关、单轮的设置上,例如视觉问答(VQA)。这些评估方法无法有效评估智能体在动态环境中,基于几何、接触和支撑关系等物理约束进行推理和行动的能力。现有方法的痛点在于缺乏对物理结构和因果关系的深入理解和利用。
核心思路:本文的核心思路是构建一个交互式的3D物理环境,通过设计一系列需要理解物理约束才能完成的任务,来评估模型在感知、推理和行动方面的能力。这种主动问题解决的评估方式能够更全面地反映模型对物理世界的理解程度。
技术框架:CHAIN基准测试包含以下几个关键组成部分:1) 一个3D物理模拟环境,用于模拟真实世界的物理交互;2) 一系列具有挑战性的任务,例如互锁机械谜题和3D堆叠打包,这些任务需要模型理解几何、接触和支撑关系;3) 一套评估指标,用于衡量模型在理解、规划和执行动作方面的性能。整体流程是:模型接收环境的视觉输入,根据任务目标生成动作序列,环境执行动作并返回新的视觉输入,模型根据新的输入调整后续动作,直到任务完成或失败。
关键创新:CHAIN基准测试的关键创新在于其交互性和物理驱动性。与传统的静态图像或视频理解任务不同,CHAIN要求模型主动与环境交互,并通过试错来学习物理规律。此外,CHAIN的任务设计强调了物理约束的重要性,迫使模型必须理解几何、接触和支撑关系才能成功完成任务。
关键设计:CHAIN基准测试的任务设计包括互锁机械谜题和3D堆叠打包等。这些任务需要模型理解不同物体的形状、大小和相对位置,以及它们之间的接触和支撑关系。评估指标包括任务完成率、动作序列长度和执行时间等。具体的参数设置、损失函数和网络结构取决于所使用的VLM模型,但CHAIN提供了一个统一的交互式评估平台,可以方便地比较不同模型的性能。
🖼️ 关键图片


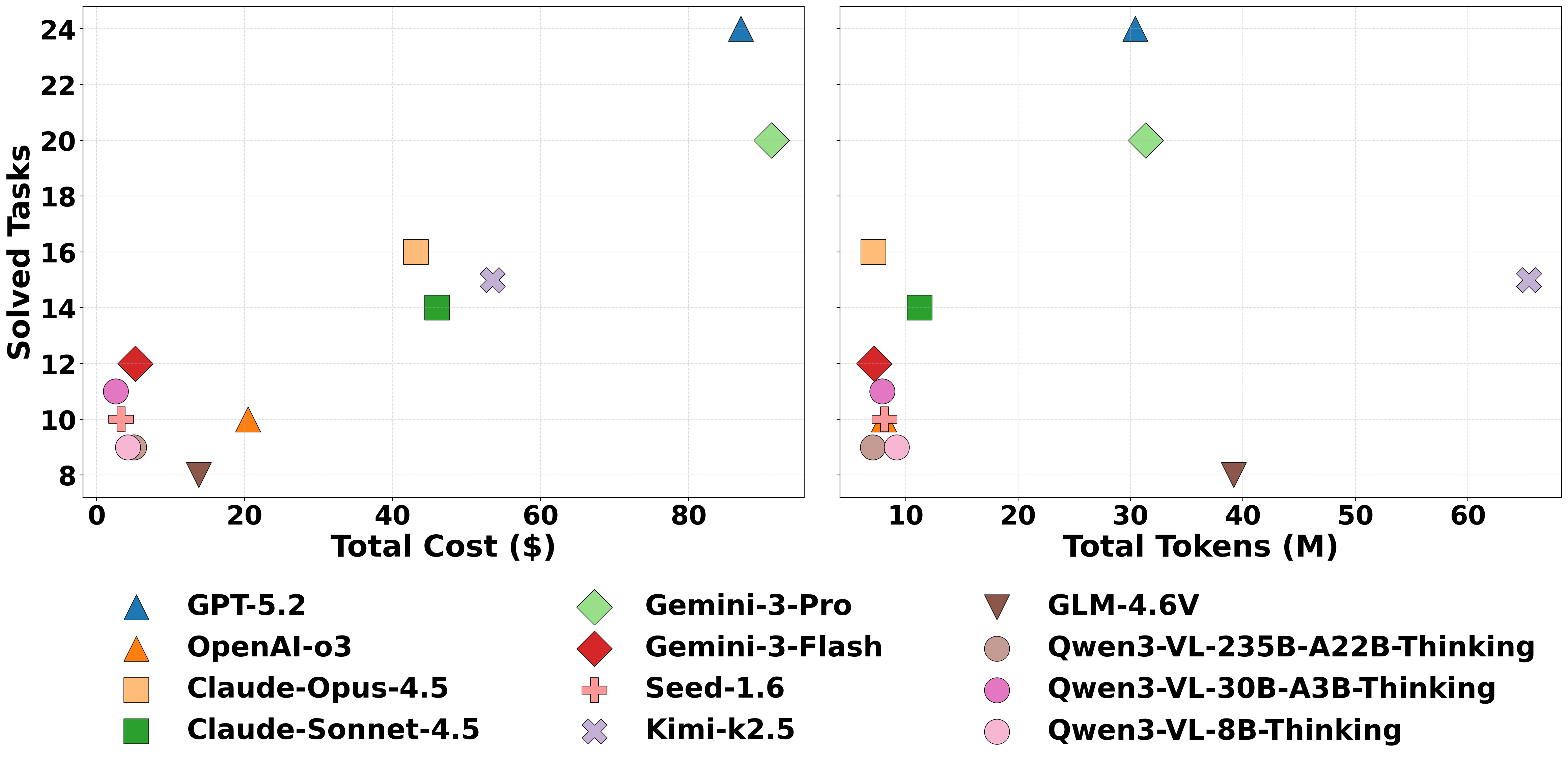
📊 实验亮点
实验结果表明,即使是最先进的VLM和基于扩散的模型在CHAIN基准测试中仍然表现不佳,表明它们在理解物理结构和因果约束方面存在显著不足。这些模型常常无法生成可靠的长期规划,并且难以将感知到的结构转化为有效的行动。这突显了现有模型在物理推理方面的局限性,并为未来的研究方向提供了重要的启示。
🎯 应用场景
该研究成果可应用于具身智能体、交互式设计和长程操作等领域。例如,可以训练机器人理解物理环境,规划并执行复杂的装配任务;也可以用于辅助设计师进行产品设计,确保设计的可行性和稳定性。未来,该研究有望推动智能体在真实物理世界中实现更高级别的自主性和适应性。
📄 摘要(原文)
Understanding the physical structure is essential for real-world applications such as embodied agents, interactive design, and long-horizon manipulation. Yet, prevailing Vision-Language Model (VLM) evaluations still center on structure-agnostic, single-turn setups (e.g., VQA), which fail to assess agents' ability to reason about how geometry, contact, and support relations jointly constrain what actions are possible in a dynamic environment. To address this gap, we introduce the Causal Hierarchy of Actions and Interactions (CHAIN) benchmark, an interactive 3D, physics-driven testbed designed to evaluate whether models can understand, plan, and execute structured action sequences grounded in physical constraints. CHAIN shifts evaluation from passive perception to active problem solving, spanning tasks such as interlocking mechanical puzzles and 3D stacking and packing. We conduct a comprehensive study of state-of-the-art VLMs and diffusion-based models under unified interactive settings. Our results show that top-performing models still struggle to internalize physical structure and causal constraints, often failing to produce reliable long-horizon plans and cannot robustly translate perceived structure into effective actions. The project is available at https://social-ai-studio.github.io/CHAIN/.