Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models
作者: Christian Simon, MAsato Ishii, Wei-Yao Wang, Koichi Saito, Akio Hayakawa, Dongseok Shim, Zhi Zhong, Shuyang Cui, Shusuke Takahashi, Takashi Shibuya, Yuki Mitsufuji
分类: cs.CV, cs.AI
发布日期: 2026-02-24
备注: Accepted to CVPR 2026
💡 一句话要点
提出MMHNet,解决视频到音频生成模型在长时序上的泛化难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频到音频生成 多模态学习 长时序建模 分层网络 Mamba 非因果模型 音频生成
📋 核心要点
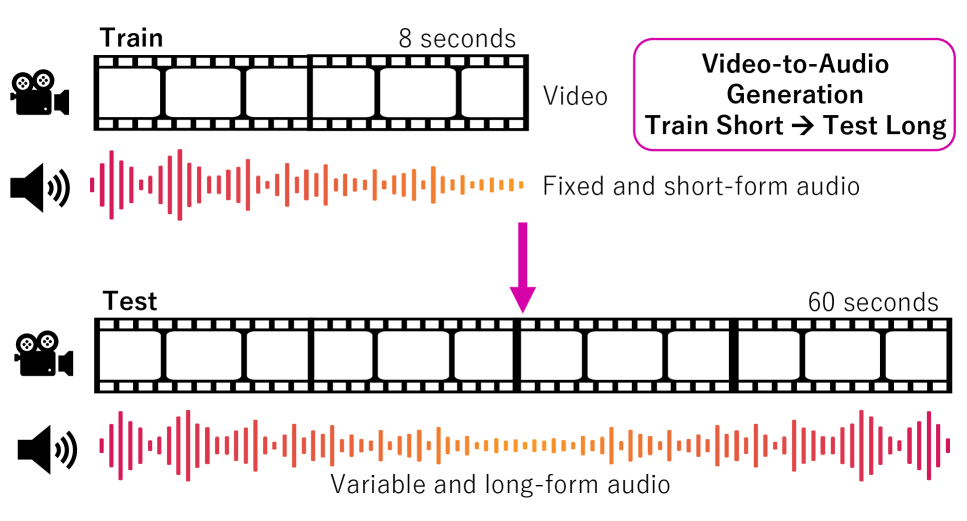
- 现有视频到音频生成模型难以处理长时序视频,面临数据稀缺和多模态信息对齐的挑战。
- 论文提出MMHNet,结合分层结构和非因果Mamba,提升模型处理长时依赖关系的能力。
- 实验证明,MMHNet在长视频到音频生成任务中表现出色,能够生成超过5分钟的音频。
📝 摘要(中文)
本文致力于解决视频到音频生成中多模态对齐的扩展性问题,尤其是在数据有限以及文本描述与帧级别视频信息不匹配的情况下。研究重点在于模型在短实例上训练后,能否泛化到更长的实例。为此,论文提出了多模态分层网络MMHNet,它是现有最先进视频到音频模型的增强扩展。该方法集成了分层方法和非因果Mamba,以支持长时音频生成。实验结果表明,该方法显著改进了长音频生成,最长可达5分钟以上。证明了在视频到音频生成任务中,无需在长时数据上训练,也能实现短时训练、长时测试。实验表明,所提出的方法在长视频到音频基准测试中取得了显著成果,优于以往的视频到音频方法。此外,该模型能够生成超过5分钟的音频,而以往的视频到音频方法在生成长时音频方面存在不足。
🔬 方法详解
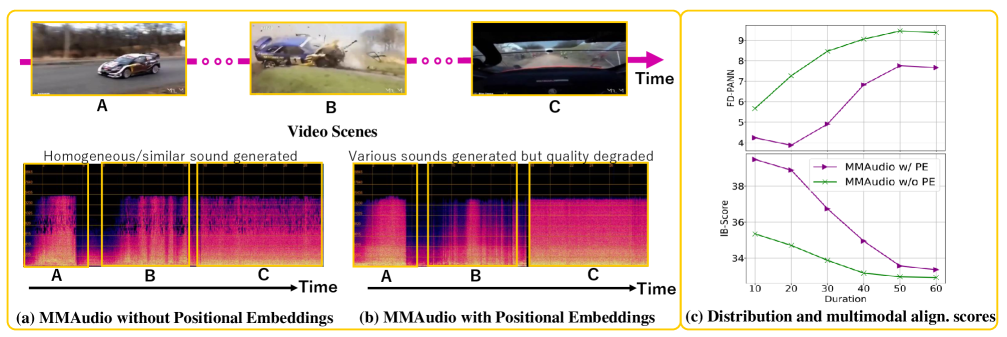
问题定义:视频到音频生成任务旨在根据给定的视频内容生成相应的音频。现有方法在处理长时序视频时面临挑战,主要原因是模型难以捕捉长距离依赖关系,并且训练数据通常是短片段,导致模型在长视频上的泛化能力不足。现有方法难以生成超过5分钟的长音频,限制了实际应用。
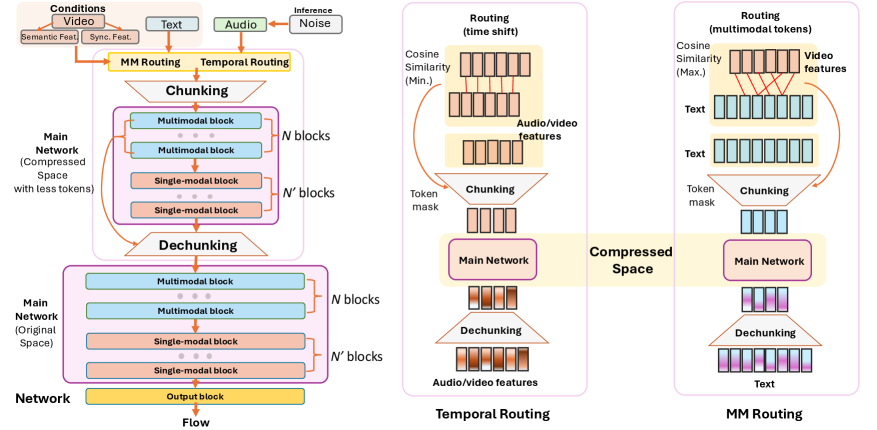
核心思路:论文的核心思路是构建一个具有分层结构的多模态网络,并结合非因果Mamba模型来增强模型对长时依赖关系的建模能力。通过分层结构,模型可以逐步提取视频和音频特征,并进行多模态融合。非因果Mamba模型能够有效地捕捉长距离上下文信息,从而提高生成长音频的质量和一致性。这样设计的目的是为了让模型能够更好地理解视频内容,并生成与之对应的、连贯的长音频。
技术框架:MMHNet的整体架构包含以下几个主要模块:1) 视频编码器:用于提取视频帧的特征表示。2) 音频编码器:用于提取音频片段的特征表示。3) 多模态融合模块:将视频和音频特征进行融合,得到多模态表示。4) 分层解码器:利用分层结构逐步生成音频。5) 非因果Mamba模块:在解码器中引入非因果Mamba,增强长时依赖建模能力。整个流程是,首先分别编码视频和音频,然后进行多模态融合,最后通过分层解码器和Mamba模块生成音频。
关键创新:论文的关键创新在于以下两点:1) 提出了多模态分层网络MMHNet,能够有效地处理长时序视频到音频的生成任务。2) 引入了非因果Mamba模型,增强了模型对长距离上下文信息的建模能力。与现有方法相比,MMHNet能够生成更长、更连贯的音频,并且在长视频上的泛化能力更强。
关键设计:在网络结构方面,采用了分层解码器,逐步生成音频。在损失函数方面,使用了标准的音频生成损失函数,例如L1损失或L2损失。非因果Mamba模块的具体实现细节包括Mamba块的层数、隐藏层维度等。此外,还采用了数据增强技术,例如时间拉伸和音高变换,以提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MMHNet在长视频到音频生成任务中取得了显著成果,优于以往的方法。具体来说,MMHNet能够生成超过5分钟的音频,而以往的方法通常只能生成几秒钟或几十秒钟的音频。在客观指标和主观评价方面,MMHNet都取得了明显的提升,证明了其在长时序视频到音频生成方面的优势。
🎯 应用场景
该研究成果可应用于电影制作、游戏开发、虚拟现实等领域,实现自动化的视频配乐和音效生成。例如,可以根据电影场景自动生成背景音乐,或者为游戏角色生成逼真的声音效果。此外,该技术还可以用于辅助听力障碍人士理解视频内容,提升他们的生活质量。未来,该技术有望进一步发展,实现更加智能和个性化的音频生成。
📄 摘要(原文)
Scaling multimodal alignment between video and audio is challenging, particularly due to limited data and the mismatch between text descriptions and frame-level video information. In this work, we tackle the scaling challenge in multimodal-to-audio generation, examining whether models trained on short instances can generalize to longer ones during testing. To tackle this challenge, we present multimodal hierarchical networks so-called MMHNet, an enhanced extension of state-of-the-art video-to-audio models. Our approach integrates a hierarchical method and non-causal Mamba to support long-form audio generation. Our proposed method significantly improves long audio generation up to more than 5 minutes. We also prove that training short and testing long is possible in the video-to-audio generation tasks without training on the longer durations. We show in our experiments that our proposed method could achieve remarkable results on long-video to audio benchmarks, beating prior works in video-to-audio tasks. Moreover, we showcase our model capability in generating more than 5 minutes, while prior video-to-audio methods fall short in generating with long durations.