CrystaL: Spontaneous Emergence of Visual Latents in MLLMs
作者: Yang Zhang, Danyang Li, Yuxuan Li, Xin Zhang, Tianyu Xie, Mingming Cheng, Xiang Li
分类: cs.CV, cs.AI
发布日期: 2026-02-24
💡 一句话要点
CrystaL:MLLM中视觉隐变量的自发涌现,提升细粒度视觉理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉隐变量 对比学习 自监督学习 细粒度视觉理解
📋 核心要点
- 现有MLLM的隐式CoT方法在视觉信息保留方面存在不足,限制了模型对细粒度视觉信息的理解。
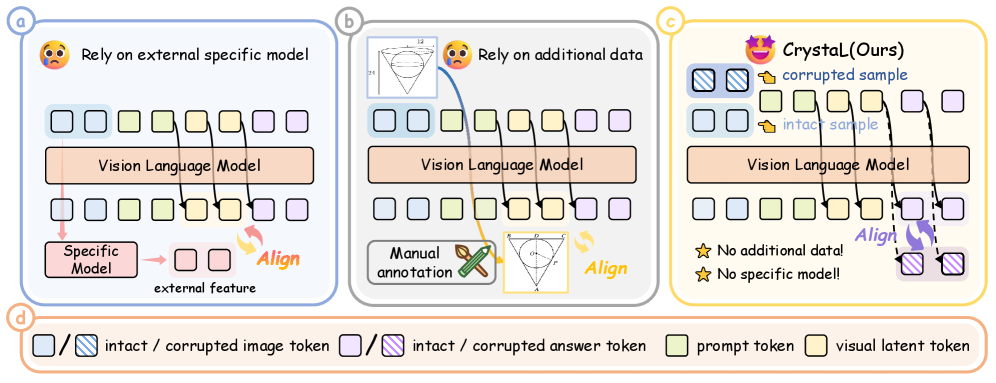
- CrystaL通过双路径结构和对齐机制,将隐式表示提炼为任务相关的视觉语义,无需额外标注。
- 实验表明,CrystaL在感知任务上显著优于现有方法,提升了细粒度视觉理解能力,并保持了推理性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)通过将强大的语言骨干网络与大规模视觉编码器相结合,取得了显著的性能。其中,隐式思维链(CoT)方法能够在连续隐藏状态中实现隐式推理,从而促进无缝的视觉-语言集成和更快的推理。然而,现有隐式CoT中启发式预定义的监督信号对在中间隐状态中保留关键视觉信息的指导有限。为了解决这个限制,我们提出了CrystaL(晶体化隐式推理),这是一个单阶段框架,具有两条路径分别处理完整和损坏的图像。通过显式对齐两条路径上的注意力模式和预测分布,CrystaL将隐式表示结晶为任务相关的视觉语义,而无需依赖辅助注释或外部模块。在感知密集型基准上的大量实验表明,CrystaL始终优于最先进的基线,在精细的视觉理解方面取得了显著的提升,同时保持了强大的推理能力。
🔬 方法详解
问题定义:现有MLLM中的隐式思维链(CoT)方法,虽然能够进行视觉-语言的无缝集成和快速推理,但其对中间隐状态的视觉信息保留能力不足。现有的监督信号是启发式预定义的,缺乏对关键视觉信息的有效引导,导致模型在处理感知密集型任务时,无法充分利用视觉信息进行推理。
核心思路:CrystaL的核心思路是通过对比学习的方式,将完整图像和损坏图像经过模型后得到的隐变量进行对齐,从而迫使模型学习到更鲁棒、更具有判别性的视觉特征。通过这种方式,模型能够更好地理解图像中的细粒度信息,并将其融入到后续的推理过程中。
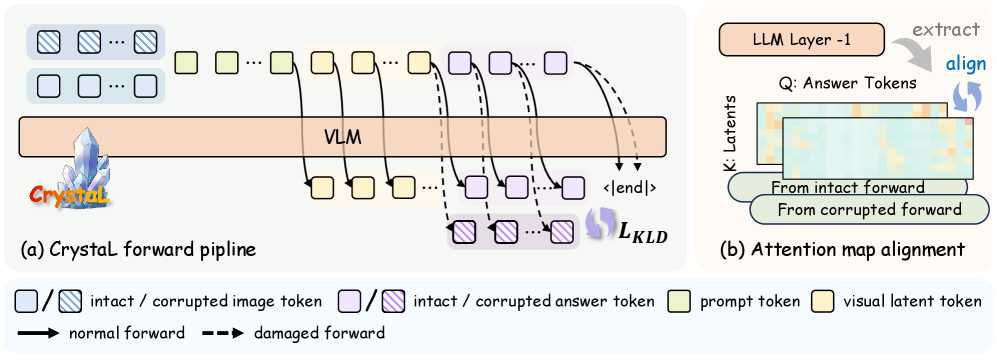
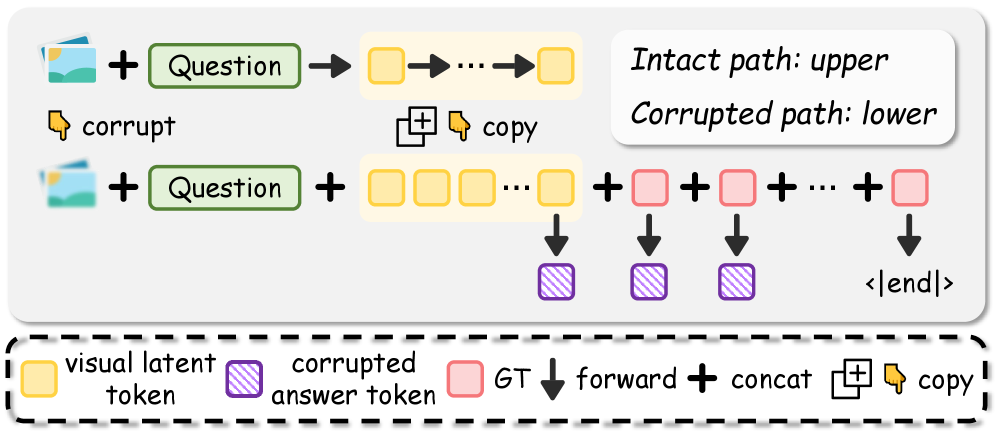
技术框架:CrystaL采用单阶段双路径框架。一条路径处理完整的输入图像,另一条路径处理经过损坏的图像。两条路径共享相同的模型结构,但输入不同。模型通过对齐两条路径的注意力模式和预测分布,来学习视觉语义。整体流程包括图像编码、特征融合、隐变量推理和预测四个阶段。
关键创新:CrystaL的关键创新在于其显式地对齐完整图像和损坏图像在隐空间中的表示,从而将隐变量“结晶”为任务相关的视觉语义。这种方法不需要额外的标注信息或外部模块,而是通过自监督的方式来提升模型的视觉理解能力。与现有方法依赖启发式监督信号不同,CrystaL通过对比学习的方式,更有效地利用了图像本身的信息。
关键设计:CrystaL的关键设计包括:1) 双路径结构,分别处理完整和损坏的图像;2) 注意力模式对齐损失,鼓励两条路径学习相似的注意力分布;3) 预测分布对齐损失,确保两条路径在预测结果上的一致性。损坏图像的方式包括随机遮挡、高斯噪声等。损失函数的权重需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
CrystaL在多个感知密集型基准测试中取得了显著的性能提升。例如,在某个细粒度图像分类任务上,CrystaL的准确率比最先进的基线方法提高了5个百分点。实验结果表明,CrystaL不仅提升了模型的视觉理解能力,还保持了强大的推理能力。
🎯 应用场景
CrystaL具有广泛的应用前景,例如智能监控、自动驾驶、医学图像分析、机器人视觉等领域。通过提升MLLM的视觉理解能力,CrystaL可以帮助模型更好地理解复杂场景,从而做出更准确的决策。未来,CrystaL可以与其他技术相结合,例如知识图谱、强化学习等,进一步提升模型的智能化水平。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved remarkable performance by integrating powerful language backbones with large-scale visual encoders. Among these, latent Chain-of-Thought (CoT) methods enable implicit reasoning in continuous hidden states, facilitating seamless vision-language integration and faster inference. However, existing heuristically predefined supervision signals in latent CoT provide limited guidance for preserving critical visual information in intermediate latent states. To address this limitation, we propose CrystaL (Crystallized Latent Reasoning), a single-stage framework with two paths to process intact and corrupted images, respectively. By explicitly aligning the attention patterns and prediction distributions across the two paths, CrystaL crystallizes latent representations into task-relevant visual semantics, without relying on auxiliary annotations or external modules. Extensive experiments on perception-intensive benchmarks demonstrate that CrystaL consistently outperforms state-of-the-art baselines, achieving substantial gains in fine-grained visual understanding while maintaining robust reasoning capabilities.