Are Multimodal Large Language Models Good Annotators for Image Tagging?
作者: Ming-Kun Xie, Jia-Hao Xiao, Zhiqiang Kou, Zhongnian Li, Gang Niu, Masashi Sugiyama
分类: cs.CV
发布日期: 2026-02-24
💡 一句话要点
提出TagLLM框架,提升多模态大语言模型在图像标签任务中的标注质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 图像标签 自动标注 提示工程 标签消歧
📋 核心要点
- 传统图像标签依赖人工标注,成本高昂,多模态大语言模型(MLLM)有潜力降低成本,但其标注质量与人工标注的差距尚不明确。
- 论文提出TagLLM框架,通过候选生成和标签消歧两个模块,缩小MLLM生成标注与人工标注之间的差距,提升标注质量。
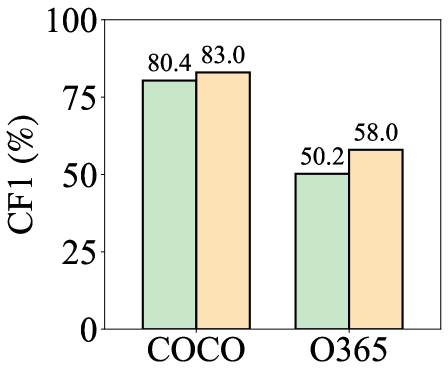
- 实验表明,TagLLM在下游训练任务中,能够弥合MLLM与人工标注之间60%-80%的性能差距,显著提升标注效果。
📝 摘要(中文)
图像标签是计算机视觉中的一项基础任务,传统上依赖于人工标注的数据集来训练多标签分类器,这会产生大量的人力和成本。多模态大语言模型(MLLM)为自动化标注提供了有希望的潜力,但它们取代人工标注者的能力仍未被充分探索。本文旨在分析MLLM生成标注与人工标注之间的差距,并提出一种有效的解决方案,使基于MLLM的标注能够取代人工标注。分析表明,在保守估计下,MLLM可以将标注成本降低到人工成本的千分之一,主要在于GPU使用,与人工工作相比几乎可以忽略不计。它们的标注质量达到人工性能的50%到80%,同时在下游训练任务中达到90%以上的性能。基于这些发现,我们提出了TagLLM,一种用于图像标签的新框架,旨在缩小MLLM生成标注与人工标注之间的差距。TagLLM包括两个组成部分:候选生成,它采用结构化的分组提示来有效地生成一个紧凑的候选集,该候选集尽可能多地覆盖真实标签,同时减少后续标注工作量;以及标签消歧,它交互式地校准提示中类别的语义概念,并有效地细化候选标签。大量实验表明,TagLLM显著缩小了MLLM生成标注与人工标注之间的差距,尤其是在下游训练性能方面,它弥合了大约60%到80%的差距。
🔬 方法详解
问题定义:图像标签任务需要大量人工标注数据,成本高昂且耗时。现有的多模态大语言模型(MLLM)虽然具备自动标注的潜力,但其标注质量与人工标注存在差距,难以直接替代人工标注,尤其是在标签的准确性和完整性方面。
核心思路:TagLLM的核心思路是通过结构化的提示工程和交互式的标签校准,提升MLLM在图像标签任务中的标注质量。具体来说,首先通过分组提示生成候选标签集合,然后通过标签消歧模块,利用交互式的方式校准标签的语义概念,从而更准确地识别图像中的标签。
技术框架:TagLLM框架包含两个主要模块:候选生成和标签消歧。候选生成模块采用结构化的分组提示,高效生成一个紧凑的候选标签集合,力求覆盖尽可能多的真实标签,同时减少后续标注的工作量。标签消歧模块则通过与MLLM的交互,校准提示中类别的语义概念,并有效地细化候选标签,最终输出高质量的图像标签。
关键创新:TagLLM的关键创新在于其结合了结构化提示工程和交互式标签校准。结构化提示工程能够引导MLLM更全面地考虑图像中的各种标签,而交互式标签校准则能够纠正MLLM对标签语义的误解,从而提高标注的准确性。与直接使用MLLM进行标注相比,TagLLM能够显著提升标注质量。
关键设计:在候选生成阶段,论文采用了分组提示策略,将标签分成不同的组,并分别提示MLLM识别每组中的标签。在标签消歧阶段,论文设计了一种交互式的校准机制,通过向MLLM提供标签的定义和示例,引导MLLM理解标签的真实含义。具体的参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TagLLM能够显著缩小MLLM生成标注与人工标注之间的差距,尤其是在下游训练性能方面,弥合了大约60%到80%的差距。这表明TagLLM能够有效提升MLLM在图像标签任务中的标注质量,使其更接近人工标注水平。
🎯 应用场景
TagLLM可应用于各种需要图像标签的场景,例如自动驾驶、智能安防、电商商品识别、医学图像分析等。该研究降低了图像数据标注的成本,加速了相关人工智能模型的开发和部署,具有重要的实际应用价值和广泛的未来影响。
📄 摘要(原文)
Image tagging, a fundamental vision task, traditionally relies on human-annotated datasets to train multi-label classifiers, which incurs significant labor and costs. While Multimodal Large Language Models (MLLMs) offer promising potential to automate annotation, their capability to replace human annotators remains underexplored. This paper aims to analyze the gap between MLLM-generated and human annotations and to propose an effective solution that enables MLLM-based annotation to replace manual labeling. Our analysis of MLLM annotations reveals that, under a conservative estimate, MLLMs can reduce annotation cost to as low as one-thousandth of the human cost, mainly accounting for GPU usage, which is nearly negligible compared to manual efforts. Their annotation quality reaches about 50\% to 80\% of human performance, while achieving over 90\% performance on downstream training tasks.Motivated by these findings, we propose TagLLM, a novel framework for image tagging, which aims to narrow the gap between MLLM-generated and human annotations. TagLLM comprises two components: Candidates generation, which employs structured group-wise prompting to efficiently produce a compact candidate set that covers as many true labels as possible while reducing subsequent annotation workload; and label disambiguation, which interactively calibrates the semantic concept of categories in the prompts and effectively refines the candidate labels. Extensive experiments show that TagLLM substantially narrows the gap between MLLM-generated and human annotations, especially in downstream training performance, where it closes about 60\% to 80\% of the difference.