LongVideo-R1: Smart Navigation for Low-cost Long Video Understanding
作者: Jihao Qiu, Lingxi Xie, Xinyue Huo, Qi Tian, Qixiang Ye
分类: cs.CV
发布日期: 2026-02-24
备注: 17 pages, 9 figures, 8 tables, accepted to CVPR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出LongVideo-R1,通过主动推理导航实现低成本长视频理解。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多模态学习 大型语言模型 主动推理 强化学习 视频导航 低成本计算
📋 核心要点
- 现有长视频理解方法计算成本高昂,难以在低预算场景下应用,存在效率瓶颈。
- LongVideo-R1通过主动推理和导航,智能选择信息量大的视频片段,避免冗余搜索,提升效率。
- 实验表明,LongVideo-R1在多个长视频基准测试中,实现了问答准确性和效率之间的良好平衡。
📝 摘要(中文)
本文致力于解决在低计算预算下进行长视频理解这一关键但未被充分探索的挑战。我们提出了LongVideo-R1,一个主动的、具备推理能力的多模态大型语言模型(MLLM)代理,旨在实现高效的视频上下文导航,避免穷举搜索的冗余。LongVideo-R1的核心在于一个推理模块,该模块利用高层次的视觉线索来推断最具信息量的视频片段,以便后续处理。在推理过程中,该代理从顶层视觉摘要开始遍历,并迭代地细化其关注点,一旦获得足够的知识来回答查询,便立即停止探索过程。为了方便训练,我们首先从CGBench(一个带有 grounding 注释的视频语料库)中提取分层视频字幕,并引导GPT-5生成33K高质量的思维链(chain-of-thought)轨迹。LongVideo-R1代理通过一个两阶段范式在Qwen-3-8B模型上进行微调:监督微调(SFT),然后是强化学习(RL),其中RL采用专门设计的奖励函数来最大化选择性和高效的片段导航。在多个长视频基准上的实验验证了该方法的有效性,该方法在问答准确性和效率之间取得了优越的平衡。所有整理的数据和源代码都将在补充材料中提供,并将公开发布。
🔬 方法详解
问题定义:论文旨在解决长视频理解任务中,计算资源受限情况下的效率问题。现有方法通常采用穷举搜索或随机采样,导致计算冗余,无法在低成本设备上有效运行。因此,如何以更少的计算量获取长视频的关键信息,是本文要解决的核心问题。
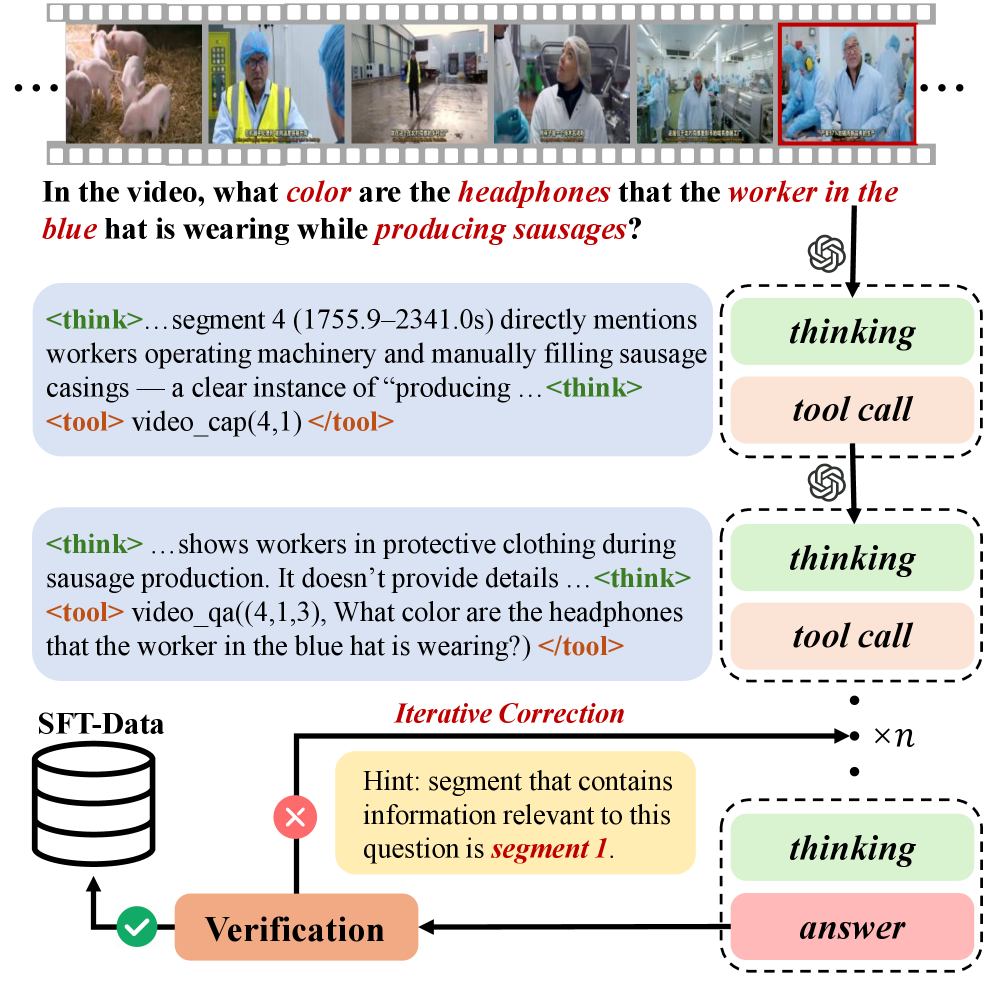
核心思路:论文的核心思路是模仿人类的阅读理解过程,通过主动推理和导航,有选择性地探索视频内容。Agent 从全局摘要开始,逐步聚焦到与问题相关的局部片段,避免不必要的计算。这种“由粗到精”的策略显著提升了效率。
技术框架:LongVideo-R1 的整体框架包含以下几个主要模块:1) 视频摘要提取模块,用于生成视频的层次化摘要信息;2) 推理模块,基于视觉线索和问题,判断下一步需要探索的视频片段;3) 多模态大型语言模型(MLLM),用于理解视频内容和生成答案;4) 强化学习模块,用于优化 Agent 的导航策略。整个流程是:输入视频和问题,Agent 首先利用推理模块选择片段,然后 MLLM 处理该片段并更新知识,重复此过程直到获得足够信息回答问题。
关键创新:LongVideo-R1 的关键创新在于其主动推理和导航机制。与传统的被动式处理不同,LongVideo-R1 能够根据当前知识和问题,主动选择最有价值的视频片段进行分析。这种主动性显著减少了计算量,提高了效率。此外,使用强化学习来优化导航策略,使得 Agent 能够自适应地学习最佳的探索路径。
关键设计:论文采用了两阶段训练策略:首先是监督微调(SFT),使用 GPT-5 生成的 chain-of-thought 数据来训练 Agent 的推理能力;然后是强化学习(RL),使用专门设计的奖励函数来鼓励 Agent 选择信息量大的片段,并惩罚冗余的探索。奖励函数的设计是关键,需要平衡准确性和效率。具体参数设置和网络结构细节在论文补充材料中提供。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LongVideo-R1 在多个长视频基准测试中取得了显著的性能提升。具体来说,在保持较高问答准确率的同时,计算成本显著降低,与现有方法相比,在效率方面有明显优势。这些结果验证了 LongVideo-R1 在低计算预算下进行长视频理解的有效性。
🎯 应用场景
LongVideo-R1 在视频监控、智能安防、在线教育、视频搜索等领域具有广泛的应用前景。例如,在视频监控中,可以快速定位异常事件;在在线教育中,可以帮助学生快速找到课程重点;在视频搜索中,可以提高搜索效率和准确性。该研究有助于推动低成本、高效率的长视频理解技术的发展。
📄 摘要(原文)
This paper addresses the critical and underexplored challenge of long video understanding with low computational budgets. We propose LongVideo-R1, an active, reasoning-equipped multimodal large language model (MLLM) agent designed for efficient video context navigation, avoiding the redundancy of exhaustive search. At the core of LongVideo-R1 lies a reasoning module that leverages high-level visual cues to infer the most informative video clip for subsequent processing. During inference, the agent initiates traversal from top-level visual summaries and iteratively refines its focus, immediately halting the exploration process upon acquiring sufficient knowledge to answer the query. To facilitate training, we first extract hierarchical video captions from CGBench, a video corpus with grounding annotations, and guide GPT-5 to generate 33K high-quality chain-of-thought-with-tool trajectories. The LongVideo-R1 agent is fine-tuned upon the Qwen-3-8B model through a two-stage paradigm: supervised fine-tuning (SFT) followed by reinforcement learning (RL), where RL employs a specifically designed reward function to maximize selective and efficient clip navigation. Experiments on multiple long video benchmarks validate the effectiveness of name, which enjoys superior tradeoff between QA accuracy and efficiency. All curated data and source code are provided in the supplementary material and will be made publicly available. Code and data are available at: https://github.com/qiujihao19/LongVideo-R1