SpatiaLQA: A Benchmark for Evaluating Spatial Logical Reasoning in Vision-Language Models
作者: Yuechen Xie, Xiaoyan Zhang, Yicheng Shan, Hao Zhu, Rui Tang, Rong Wei, Mingli Song, Yuanyu Wan, Jie Song
分类: cs.CV, cs.LG
发布日期: 2026-02-24
备注: Accepted by CVPR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出SpatiaLQA基准,评估视觉语言模型在复杂空间逻辑推理中的能力
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 空间逻辑推理 场景图 递归分解 视觉问答
📋 核心要点
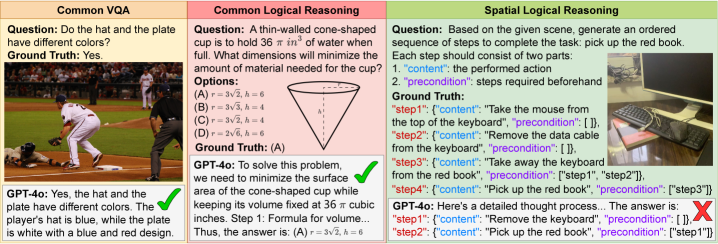
- 现有视觉语言模型在复杂空间关系和多步骤逻辑推理方面存在不足,难以应对真实场景。
- 提出递归场景图辅助推理方法,利用视觉基础模型将复杂场景分解为任务相关的场景图。
- 实验结果表明,该方法显著提升了视觉语言模型在SpatiaLQA基准上的空间逻辑推理能力。
📝 摘要(中文)
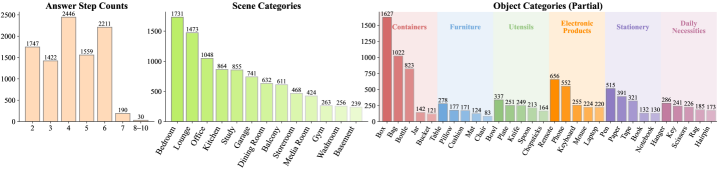
视觉语言模型(VLMs)因其出色的理解和推理能力而被越来越多地应用于实际场景。尽管VLMs在常见的视觉问答和逻辑推理方面已经表现出令人印象深刻的能力,但它们仍然缺乏在复杂现实环境中做出合理决策的能力。我们将这种能力定义为空间逻辑推理,它不仅需要理解复杂场景中物体之间的空间关系,还需要理解多步骤任务中步骤之间的逻辑依赖关系。为了弥补这一差距,我们引入了空间逻辑问答(SpatiaLQA),这是一个旨在评估VLMs空间逻辑推理能力的基准。SpatiaLQA包含9605个问答对,这些问答对来自241个真实的室内场景。我们对41个主流VLMs进行了广泛的实验,结果表明,即使是最先进的模型也在空间逻辑推理方面存在困难。为了解决这个问题,我们提出了一种称为递归场景图辅助推理的方法,该方法利用视觉基础模型将复杂场景逐步分解为与任务相关的场景图,从而增强VLMs的空间逻辑推理能力,优于以往所有方法。代码和数据集可在https://github.com/xieyc99/SpatiaLQA获取。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型在复杂现实场景下的空间逻辑推理能力不足的问题。现有方法难以有效理解场景中物体间的空间关系以及多步骤任务中的逻辑依赖,导致无法做出合理的决策。
核心思路:论文的核心思路是将复杂的视觉场景分解为更易于理解和推理的场景图。通过递归地构建场景图,模型可以逐步提取与任务相关的空间关系和逻辑信息,从而提高推理的准确性。这种分解的思想借鉴了人类解决复杂问题的策略。
技术框架:整体框架包含以下几个主要步骤:1) 图像输入:将包含复杂场景的图像输入模型。2) 场景图构建:利用视觉基础模型(例如目标检测器和关系预测器)初步构建场景图。3) 递归分解:根据任务需求,递归地将场景图分解为更小的、与任务相关的子图。4) 逻辑推理:在分解后的场景图上进行逻辑推理,得到最终答案。5) 答案输出:输出最终的答案。
关键创新:论文的关键创新在于提出了递归场景图辅助推理的方法。与以往直接在原始图像上进行推理的方法不同,该方法通过逐步分解场景,将复杂的推理过程转化为一系列更简单的子问题,从而降低了推理的难度。这种方法更符合人类的认知方式,也更易于被视觉语言模型所学习。
关键设计:递归分解的具体实现依赖于视觉基础模型的能力。论文中使用了预训练的目标检测器和关系预测器来构建初始场景图。递归分解的过程可以通过定义不同的分解策略来实现,例如基于物体类型、空间关系或任务需求进行分解。损失函数的设计需要考虑分解的质量和推理的准确性,可以采用交叉熵损失或对比学习损失等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的递归场景图辅助推理方法在SpatiaLQA基准上显著优于现有的主流视觉语言模型。具体而言,该方法在准确率方面取得了显著提升,超过了所有对比基线。这表明该方法能够有效地提高视觉语言模型在复杂空间逻辑推理任务中的性能。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、自动驾驶等领域。例如,机器人可以利用空间逻辑推理能力理解用户的指令,并在复杂的室内环境中执行任务。此外,该技术还可以用于辅助视觉障碍人士理解周围环境,提高生活质量。未来,该研究有望推动视觉语言模型在实际场景中的广泛应用。
📄 摘要(原文)
Vision-Language Models (VLMs) have been increasingly applied in real-world scenarios due to their outstanding understanding and reasoning capabilities. Although VLMs have already demonstrated impressive capabilities in common visual question answering and logical reasoning, they still lack the ability to make reasonable decisions in complex real-world environments. We define this ability as spatial logical reasoning, which not only requires understanding the spatial relationships among objects in complex scenes, but also the logical dependencies between steps in multi-step tasks. To bridge this gap, we introduce Spatial Logical Question Answering (SpatiaLQA), a benchmark designed to evaluate the spatial logical reasoning capabilities of VLMs. SpatiaLQA consists of 9,605 question answer pairs derived from 241 real-world indoor scenes. We conduct extensive experiments on 41 mainstream VLMs, and the results show that even the most advanced models still struggle with spatial logical reasoning. To address this issue, we propose a method called recursive scene graph assisted reasoning, which leverages visual foundation models to progressively decompose complex scenes into task-relevant scene graphs, thereby enhancing the spatial logical reasoning ability of VLMs, outperforming all previous methods. Code and dataset are available at https://github.com/xieyc99/SpatiaLQA.