VGGDrive: Empowering Vision-Language Models with Cross-View Geometric Grounding for Autonomous Driving
作者: Jie Wang, Guang Li, Zhijian Huang, Chenxu Dang, Hangjun Ye, Yahong Han, Long Chen
分类: cs.CV
发布日期: 2026-02-24
备注: CVPR 2026
💡 一句话要点
VGGDrive:通过跨视角几何 grounding 增强视觉-语言模型在自动驾驶中的应用
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉-语言模型 跨视角几何 3D几何 grounding 风险感知
📋 核心要点
- 现有视觉-语言模型(VLM)在自动驾驶中缺乏跨视角3D几何建模能力,导致性能受限。
- VGGDrive通过将3D基础模型的跨视角几何信息注入VLM,弥补了VLM在3D几何理解上的不足。
- 实验表明,VGGDrive在多个自动驾驶任务上显著提升了VLM的性能,验证了该方法的有效性。
📝 摘要(中文)
本文提出了一种名为VGGDrive的新架构,旨在通过跨视角几何 grounding 增强视觉-语言模型(VLM)在自动驾驶领域的性能。现有VLM在跨视角3D几何建模方面存在不足,导致其性能平庸。VGGDrive通过将成熟的3D基础模型的跨视角几何 grounding 能力注入VLM,弥补了这一关键能力差距。具体而言,引入了一个即插即用的跨视角3D几何使能器(CVGE),将冻结的视觉3D模型的跨视角3D几何特征与VLM的2D视觉特征连接起来。CVGE解耦了基础VLM架构,并通过分层自适应注入机制有效地为VLM提供3D特征。大量实验表明,VGGDrive在包括跨视角风险感知、运动预测和轨迹规划等五个自动驾驶基准测试中,显著提升了基础VLM的性能。这项研究表明,成熟的3D基础模型可以通过有效集成来增强自动驾驶任务,并展示了这种范式在自动驾驶领域的潜力。
🔬 方法详解
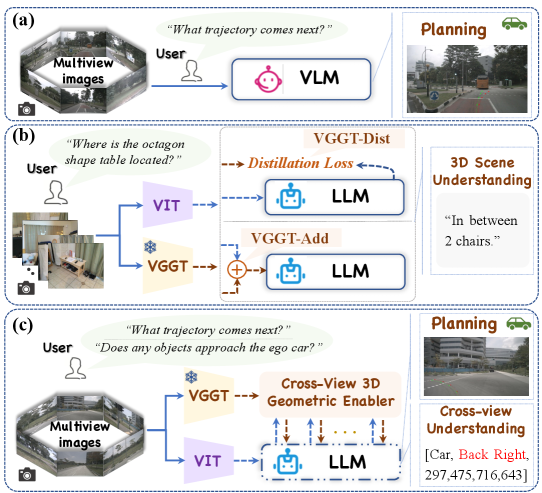
问题定义:现有视觉-语言模型(VLM)在自动驾驶场景中,难以有效利用跨视角的3D几何信息,导致在风险感知、运动预测和轨迹规划等任务中表现不佳。现有方法虽然尝试通过构建问答数据进行辅助训练,但未能从根本上赋予VLM处理复杂几何关系的能力。
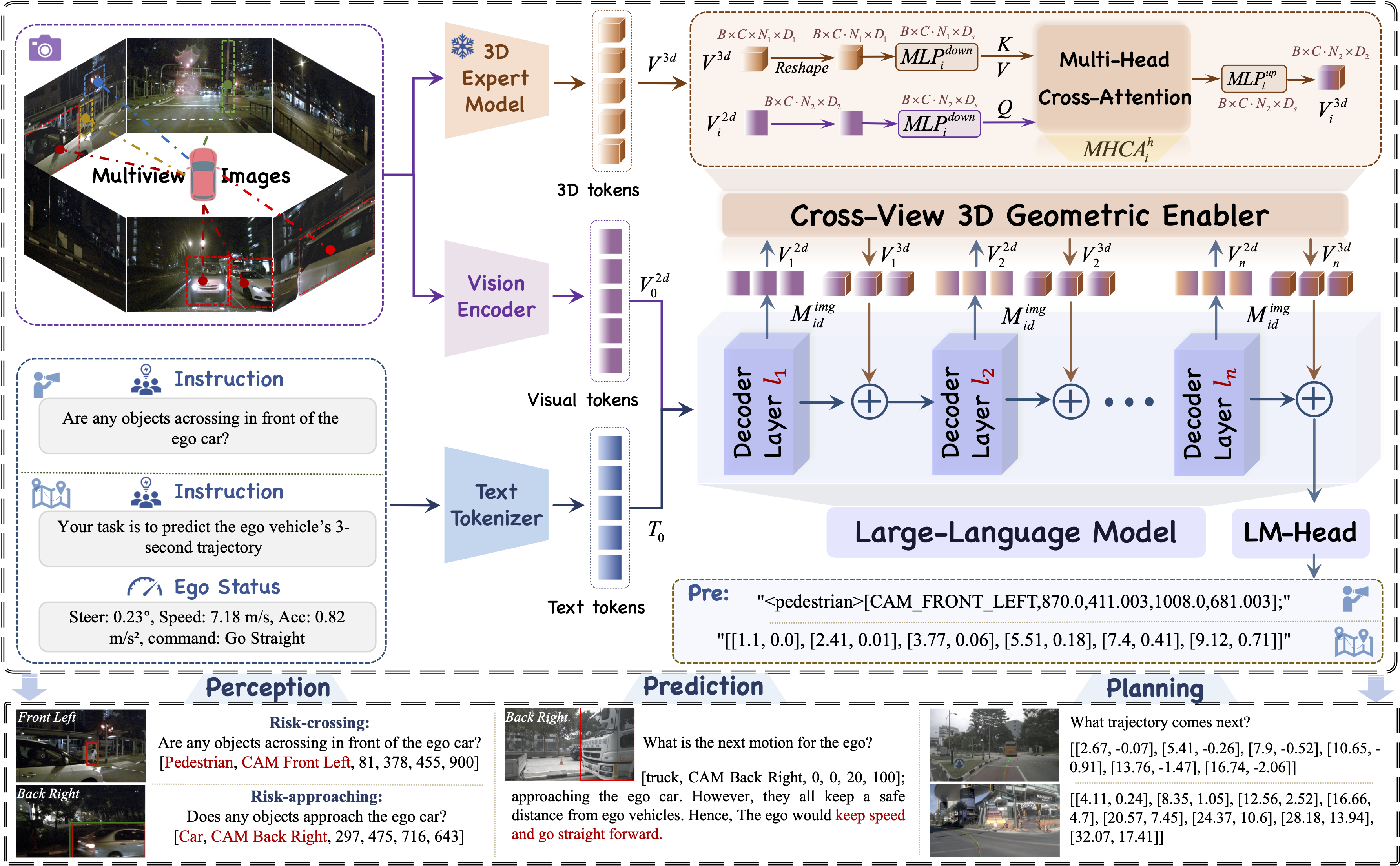
核心思路:VGGDrive的核心思路是将成熟的3D基础模型的几何理解能力迁移到VLM中,从而增强VLM对自动驾驶场景的理解。通过引入跨视角3D几何使能器(CVGE),将3D基础模型提取的几何特征注入到VLM中,实现跨视角几何信息的有效利用。
技术框架:VGGDrive的整体架构包含一个冻结的视觉3D模型、一个基础VLM和一个跨视角3D几何使能器(CVGE)。视觉3D模型负责提取场景的3D几何特征,CVGE负责将这些特征与VLM的2D视觉特征进行融合,从而增强VLM对场景的理解。CVGE采用分层自适应注入机制,将3D特征注入到VLM的不同层级中。
关键创新:VGGDrive的关键创新在于提出了跨视角3D几何使能器(CVGE),它能够有效地将3D基础模型的几何特征注入到VLM中,而无需对VLM进行大规模的重新训练。这种即插即用的设计使得VGGDrive可以灵活地应用于不同的VLM架构。
关键设计:CVGE采用分层自适应注入机制,根据VLM不同层级的特征表示能力,自适应地调整3D特征的注入强度。此外,CVGE还采用了注意力机制,用于选择性地关注重要的3D几何特征。损失函数方面,采用了标准的交叉熵损失函数进行训练。
🖼️ 关键图片
📊 实验亮点
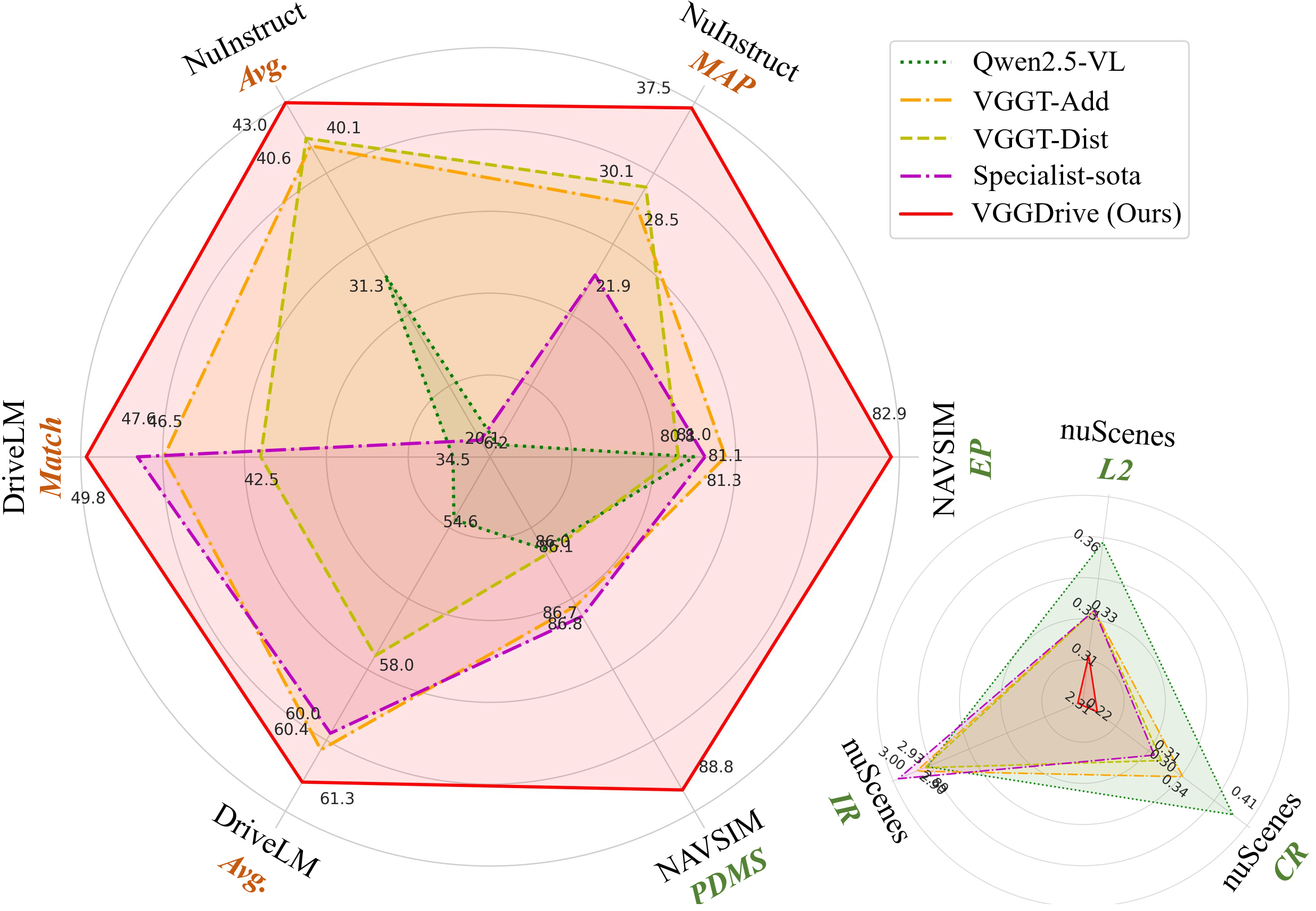
VGGDrive在五个自动驾驶基准测试中均取得了显著的性能提升。例如,在跨视角风险感知任务中,VGGDrive的性能提升了超过10%。与现有的基于问答数据的辅助训练方法相比,VGGDrive能够更有效地利用3D几何信息,从而获得更好的性能。
🎯 应用场景
VGGDrive具有广泛的应用前景,可用于提升自动驾驶系统的感知、预测和规划能力。例如,可以利用VGGDrive进行更准确的风险评估,从而提高自动驾驶车辆的安全性。此外,VGGDrive还可以应用于机器人导航、智能交通管理等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
The significance of cross-view 3D geometric modeling capabilities for autonomous driving is self-evident, yet existing Vision-Language Models (VLMs) inherently lack this capability, resulting in their mediocre performance. While some promising approaches attempt to mitigate this by constructing Q&A data for auxiliary training, they still fail to fundamentally equip VLMs with the ability to comprehensively handle diverse evaluation protocols. We thus chart a new course, advocating for the infusion of VLMs with the cross-view geometric grounding of mature 3D foundation models, closing this critical capability gap in autonomous driving. In this spirit, we propose a novel architecture, VGGDrive, which empowers Vision-language models with cross-view Geometric Grounding for autonomous Driving. Concretely, to bridge the cross-view 3D geometric features from the frozen visual 3D model with the VLM's 2D visual features, we introduce a plug-and-play Cross-View 3D Geometric Enabler (CVGE). The CVGE decouples the base VLM architecture and effectively empowers the VLM with 3D features through a hierarchical adaptive injection mechanism. Extensive experiments show that VGGDrive enhances base VLM performance across five autonomous driving benchmarks, including tasks like cross-view risk perception, motion prediction, and trajectory planning. It's our belief that mature 3D foundation models can empower autonomous driving tasks through effective integration, and we hope our initial exploration demonstrates the potential of this paradigm to the autonomous driving community.