RAYNOVA: 3D-Geometry-Free Auto-Regressive Driving World Modeling with Unified Spatio-Temporal Representation
作者: Yichen Xie, Chensheng Peng, Mazen Abdelfattah, Yihan Hu, Jiezhi Yang, Eric Higgins, Ryan Brigden, Masayoshi Tomizuka, Wei Zhan
分类: cs.CV
发布日期: 2026-02-24
备注: Accepted by CVPR 2026; Project website: http://yichen928.github.io/raynova
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RAYNOVA:提出无3D几何先验的自回归驾驶世界建模方法,实现统一时空表示。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 自动驾驶 视频生成 时空建模 自回归模型 无几何先验 多视图学习
📋 核心要点
- 现有世界模型通常独立处理空间和时间相关性,限制了对复杂动态场景的理解和泛化能力。
- RAYNOVA采用双重因果自回归框架,结合全局注意力机制,实现统一的4D时空推理,无需显式的3D几何先验。
- 实验表明,RAYNOVA在nuScenes数据集上取得了领先的多视图视频生成效果,并具有更高的吞吐量和可控性。
📝 摘要(中文)
世界基础模型旨在模拟真实世界的演变,使其具有物理上合理的行为。与分别处理空间和时间相关性的现有方法不同,我们提出了RAYNOVA,一个无几何的世界模型,它采用双重因果自回归框架。它在自回归过程中遵循尺度和时间拓扑顺序,并利用全局注意力进行统一的4D时空推理。与现有施加强3D几何先验的工作不同,RAYNOVA基于相对Plücker-ray位置编码,构建跨视图、帧和尺度的各向同性时空表示,从而能够稳健地泛化到不同的相机设置和自运动。我们进一步引入了一种循环训练范式,以减轻长时程视频生成中的分布漂移。RAYNOVA在nuScenes上实现了最先进的多视图视频生成结果,同时在不同的输入条件下提供了更高的吞吐量和强大的可控性,推广到新的视图和相机配置,而无需显式的3D场景表示。我们的代码将在http://yichen928.github.io/raynova上发布。
🔬 方法详解
问题定义:现有世界模型在驾驶场景中进行视频生成时,通常依赖于分离的空间和时间处理,或者需要强3D几何先验。这些方法难以捕捉复杂的时空依赖关系,并且泛化能力受限,尤其是在面对新的相机配置和自运动时。此外,长时程视频生成容易出现分布漂移问题,导致生成质量下降。
核心思路:RAYNOVA的核心思路是构建一个无几何先验的、统一的4D时空表示,并通过双重因果自回归框架来建模场景的演变。通过相对Plücker-ray位置编码,实现跨视图、帧和尺度的各向同性表示,从而增强模型的泛化能力。同时,采用循环训练范式来缓解长时程视频生成中的分布漂移。
技术框架:RAYNOVA的整体架构包含以下几个主要模块:1) 相对Plücker-ray位置编码模块,用于构建各向同性的时空表示;2) 双重因果自回归模块,按照尺度和时间拓扑顺序进行建模;3) 全局注意力模块,用于进行统一的4D时空推理;4) 循环训练模块,用于缓解长时程视频生成中的分布漂移。模型首先将多视图图像输入到编码器中,提取特征并进行位置编码,然后通过自回归模块生成未来的视频帧。
关键创新:RAYNOVA最重要的技术创新点在于其无几何先验的统一时空表示和双重因果自回归框架。与现有方法相比,RAYNOVA避免了对3D几何信息的依赖,从而能够更好地泛化到不同的相机配置和自运动。双重因果自回归框架能够有效地建模场景的时空依赖关系,提高视频生成的质量和一致性。
关键设计:RAYNOVA的关键设计包括:1) 相对Plücker-ray位置编码,用于构建各向同性的时空表示;2) 双重因果自回归框架,按照尺度和时间拓扑顺序进行建模;3) 全局注意力机制,用于进行统一的4D时空推理;4) 循环训练范式,通过在训练过程中引入生成的视频帧,来缓解长时程视频生成中的分布漂移。具体的损失函数包括重构损失和对抗损失,用于提高生成视频的质量和真实感。
🖼️ 关键图片

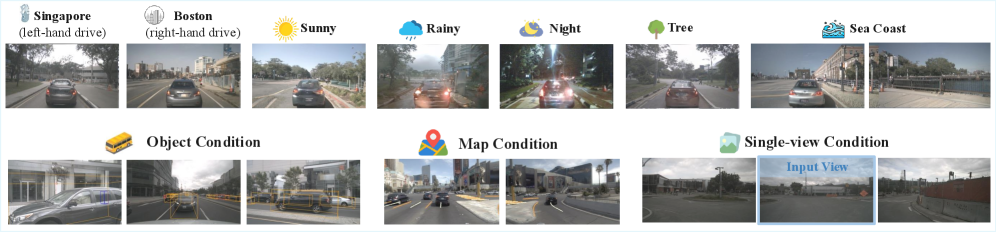

📊 实验亮点
RAYNOVA在nuScenes数据集上取得了最先进的多视图视频生成结果,显著优于现有的方法。实验结果表明,RAYNOVA在生成质量、一致性和可控性方面均有显著提升。此外,RAYNOVA还具有更高的吞吐量,能够实时生成高质量的视频帧。该模型能够推广到新的视图和相机配置,而无需显式的3D场景表示,展示了其强大的泛化能力。
🎯 应用场景
RAYNOVA在自动驾驶领域具有广泛的应用前景,例如可以用于驾驶模拟、场景理解、运动规划和决策制定。通过生成逼真的未来场景,RAYNOVA可以帮助自动驾驶系统更好地理解周围环境,预测其他车辆和行人的行为,从而提高驾驶的安全性和可靠性。此外,RAYNOVA还可以应用于虚拟现实、游戏开发等领域,创造更加沉浸式的用户体验。
📄 摘要(原文)
World foundation models aim to simulate the evolution of the real world with physically plausible behavior. Unlike prior methods that handle spatial and temporal correlations separately, we propose RAYNOVA, a geometry-free world model that employs a dual-causal autoregressive framework. It follows both scale-wise and temporal topological orders in the autoregressive process, and leverages global attention for unified 4D spatio-temporal reasoning. Different from existing works that impose strong 3D geometric priors, RAYNOVA constructs an isotropic spatio-temporal representation across views, frames, and scales based on relative Plücker-ray positional encoding, enabling robust generalization to diverse camera setups and ego motions. We further introduce a recurrent training paradigm to alleviate distribution drift in long-horizon video generation. RAYNOVA achieves state-of-the-art multi-view video generation results on nuScenes, while offering higher throughput and strong controllability under diverse input conditions, generalizing to novel views and camera configurations without explicit 3D scene representation. Our code will be released at http://yichen928.github.io/raynova.