Object-Scene-Camera Decomposition and Recomposition for Data-Efficient Monocular 3D Object Detection
作者: Zhaonian Kuang, Rui Ding, Meng Yang, Xinhu Zheng, Gang Hua
分类: cs.CV, cs.RO
发布日期: 2026-02-24
备注: IJCV
💡 一句话要点
提出对象-场景-相机解耦重组方法,提升单目3D目标检测的数据效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 单目3D目标检测 数据增强 解耦重组 对象场景相机 稀疏监督
📋 核心要点
- 单目3D目标检测对数据依赖性强,现有方法易受训练数据中对象、场景和相机姿势的强关联性影响,导致模型泛化能力不足。
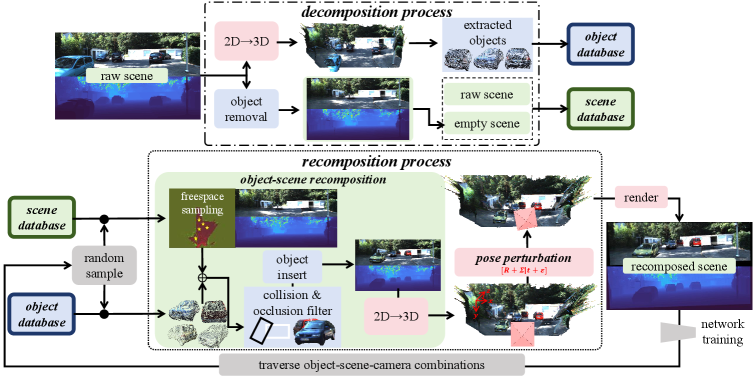
- 论文提出一种在线解耦重组方案,将训练图像分解为3D对象、背景场景和相机姿势,然后重新组合生成新的训练数据,增加数据多样性。
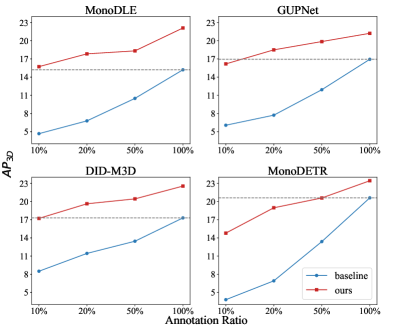
- 该方法可作为即插即用模块提升现有M3OD模型性能,在KITTI和Waymo数据集上,多个模型验证了其有效性,尤其是在稀疏标注场景下。
📝 摘要(中文)
单目3D目标检测(M3OD)本质上是病态问题,因此训练高性能的基于深度学习的M3OD模型需要大量的标注数据,这些数据具有来自不同场景、各种对象和相机姿势的复杂视觉变化。然而,由于强烈的人为偏差,对象、场景和相机姿势这三个独立实体在图像捕获以构建训练数据时总是紧密纠缠在一起。具体来说,特定的3D对象总是在具有固定相机姿势的特定场景中捕获,因此缺乏必要的多样性。这种紧密的纠缠导致了训练数据利用不足和过度拟合的挑战性问题。为了缓解这个问题,我们提出了一种在线对象-场景-相机解耦和重组数据处理方案,以更有效地利用训练数据。我们首先以高效的计算和存储方式将训练图像完全分解为纹理化的3D对象点模型和背景场景。然后,我们通过将3D对象插入到背景场景的自由空间中,并使用来自纹理化3D点表示的扰动相机姿势渲染它们,从而在每个epoch中不断重组新的训练图像。通过这种方式,所有epoch中刷新的训练数据可以覆盖独立对象、场景和相机姿势组合的完整范围。该方案可以作为一个即插即用的组件来提升M3OD模型,灵活地应用于完全监督和稀疏监督设置。在稀疏监督设置中,所有实例中距离自车相机最近的对象会被稀疏标注。然后,我们可以灵活地增加标注对象以控制标注成本。为了验证,我们的方法被广泛应用于五个具有代表性的M3OD模型,并在KITTI和更复杂的Waymo数据集上进行了评估。
🔬 方法详解
问题定义:单目3D目标检测(M3OD)需要大量标注数据,但现有数据集中的对象、场景和相机姿势存在强关联性,导致模型训练时数据利用率低,容易过拟合,泛化能力差。现有方法难以有效解耦这些因素,无法充分利用有限的训练数据。
核心思路:论文的核心思路是将训练数据中的对象、场景和相机姿势进行解耦,然后通过重新组合这些解耦的元素来生成新的、更多样化的训练数据。这样可以打破原始数据中的关联性,使模型能够学习到更鲁棒的特征,从而提高泛化能力。通过在线重组,每个epoch都使用新的训练数据,进一步提升模型性能。
技术框架:该方法主要包含两个阶段:分解阶段和重组阶段。在分解阶段,训练图像被分解为纹理化的3D对象点模型和背景场景。在重组阶段,3D对象被插入到背景场景的自由空间中,并使用扰动的相机姿势进行渲染,从而生成新的训练图像。这个过程在每个epoch中重复进行,以确保训练数据的多样性。
关键创新:该方法最重要的创新点在于提出了对象-场景-相机解耦和重组的在线数据增强方案。与传统的数据增强方法不同,该方法不是简单地对原始图像进行变换,而是从根本上改变了数据的组成方式,从而创造出更多样化的训练数据。这种方法能够有效地解决数据关联性问题,提高模型的泛化能力。
关键设计:在分解阶段,使用高效的计算和存储方式来表示3D对象点模型和背景场景。在重组阶段,需要仔细选择对象插入的位置,以确保场景的真实性。相机姿势的扰动范围也需要仔细调整,以避免生成不合理的图像。此外,该方法可以灵活地应用于完全监督和稀疏监督设置,并可以控制标注成本。
🖼️ 关键图片
📊 实验亮点
该方法在KITTI和Waymo数据集上进行了广泛的实验验证,结果表明该方法可以显著提高现有M3OD模型的性能。例如,在稀疏监督设置下,该方法能够有效地利用有限的标注数据,并取得与完全监督方法相媲美的结果。实验结果表明,该方法是一种有效的数据增强方案,可以提高模型的泛化能力。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、增强现实等领域。通过提高单目3D目标检测的数据效率,可以降低对大量标注数据的依赖,从而降低开发成本,加速相关技术的落地。该方法尤其适用于资源受限的场景,例如在标注数据较少的地区或在计算能力有限的设备上。
📄 摘要(原文)
Monocular 3D object detection (M3OD) is intrinsically ill-posed, hence training a high-performance deep learning based M3OD model requires a humongous amount of labeled data with complicated visual variation from diverse scenes, variety of objects and camera poses.However, we observe that, due to strong human bias, the three independent entities, i.e., object, scene, and camera pose, are always tightly entangled when an image is captured to construct training data. More specifically, specific 3D objects are always captured in particular scenes with fixed camera poses, and hence lacks necessary diversity. Such tight entanglement induces the challenging issues of insufficient utilization and overfitting to uniform training data. To mitigate this, we propose an online object-scene-camera decomposition and recomposition data manipulation scheme to more efficiently exploit the training data. We first fully decompose training images into textured 3D object point models and background scenes in an efficient computation and storage manner. We then continuously recompose new training images in each epoch by inserting the 3D objects into the freespace of the background scenes, and rendering them with perturbed camera poses from textured 3D point representation. In this way, the refreshed training data in all epochs can cover the full spectrum of independent object, scene, and camera pose combinations. This scheme can serve as a plug-and-play component to boost M3OD models, working flexibly with both fully and sparsely supervised settings. In the sparsely-supervised setting, objects closest to the ego-camera for all instances are sparsely annotated. We then can flexibly increase the annotated objects to control annotation cost. For validation, our method is widely applied to five representative M3OD models and evaluated on both the KITTI and the more complicated Waymo datasets.