VAGNet: Grounding 3D Affordance from Human-Object Interactions in Videos
作者: Aihua Mao, Kaihang Huang, Yong-Jin Liu, Chee Seng Chan, Ying He
分类: cs.CV
发布日期: 2026-02-24
💡 一句话要点
VAGNet:通过视频中的人-物交互进行3D可供性区域定位
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 3D可供性 人-物交互 视频引导 具身视觉 深度学习
📋 核心要点
- 现有3D可供性区域定位方法依赖静态线索,忽略了动态交互行为对可供性的影响,导致定位精度不足。
- VAGNet通过视频引导,利用人-物交互的动态序列提供功能监督,从而更准确地定位3D物体上的可供性区域。
- 论文提出了PVAD数据集,并证明VAGNet在PVAD上显著优于基于静态线索的方法,实现了最先进的性能。
📝 摘要(中文)
3D物体可供性区域定位旨在识别3D物体上支持人-物交互(HOI)的区域,这是具身视觉推理的关键能力。现有方法大多依赖静态视觉或文本线索,忽略了可供性本质上是由动态行为定义的。因此,它们难以定位真实交互中涉及的真实接触区域。我们采取不同的视角,认为人类通过观察和模仿动作来学习如何使用物体,而不仅仅是检查形状。受此启发,我们引入了视频引导的3D可供性区域定位,利用动态交互序列来提供功能监督。为此,我们提出了VAGNet框架,该框架将视频导出的交互线索与3D结构对齐,以解决静态线索无法解决的歧义。为了支持这种新设置,我们引入了PVAD,这是第一个HOI视频-3D配对可供性数据集,提供了先前工作中无法获得的功能监督。在PVAD上的大量实验表明,VAGNet实现了最先进的性能,显著优于基于静态的基线。
🔬 方法详解
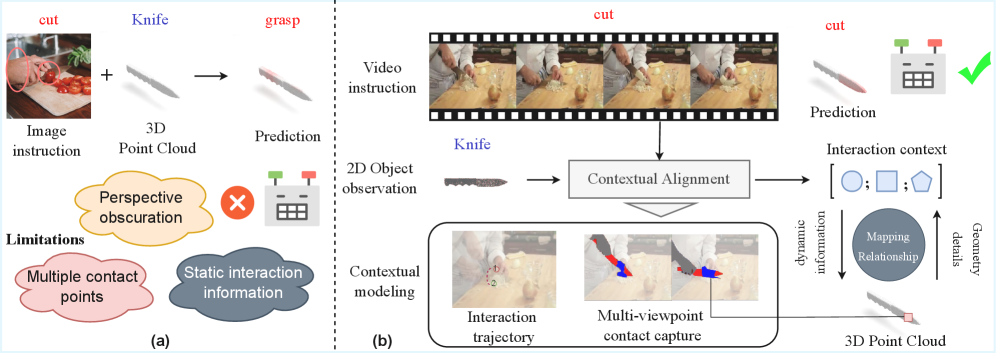
问题定义:现有3D物体可供性区域定位方法主要依赖于静态的视觉或文本信息,缺乏对动态人-物交互行为的建模。这导致模型难以准确识别物体上真正与交互相关的区域,尤其是在存在歧义的情况下。现有方法无法有效利用视频中蕴含的丰富交互信息。
核心思路:论文的核心思路是利用视频中的人-物交互信息来引导3D物体可供性区域的定位。通过观察人类如何与物体交互,模型可以学习到物体不同区域的功能,从而更准确地预测可供性区域。这种方法模拟了人类通过观察和模仿学习使用物体的过程。
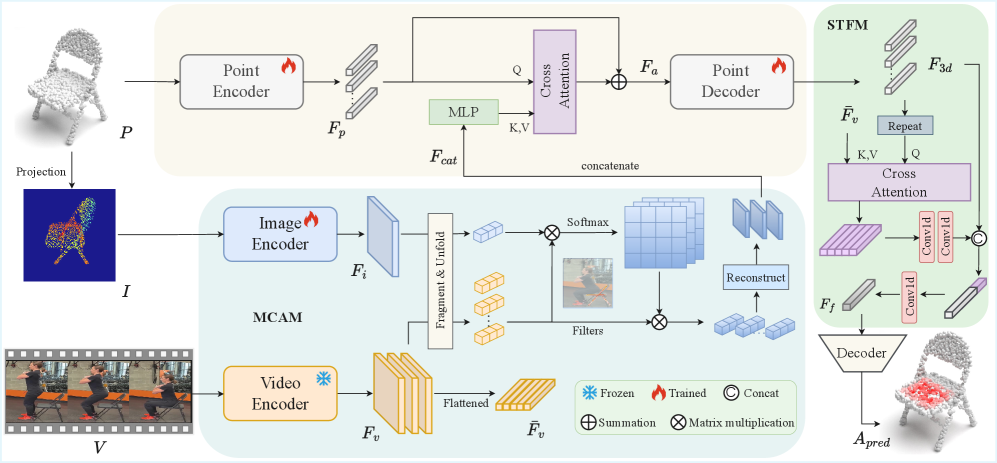
技术框架:VAGNet框架主要包含以下几个模块:1) 视频特征提取模块,用于提取视频中的人-物交互特征;2) 3D物体特征提取模块,用于提取3D物体的几何和语义特征;3) 对齐模块,用于将视频特征和3D物体特征对齐,建立它们之间的对应关系;4) 可供性预测模块,用于根据对齐后的特征预测3D物体上的可供性区域。整体流程是先分别提取视频和3D物体的特征,然后通过对齐模块建立它们之间的联系,最后利用可供性预测模块进行预测。
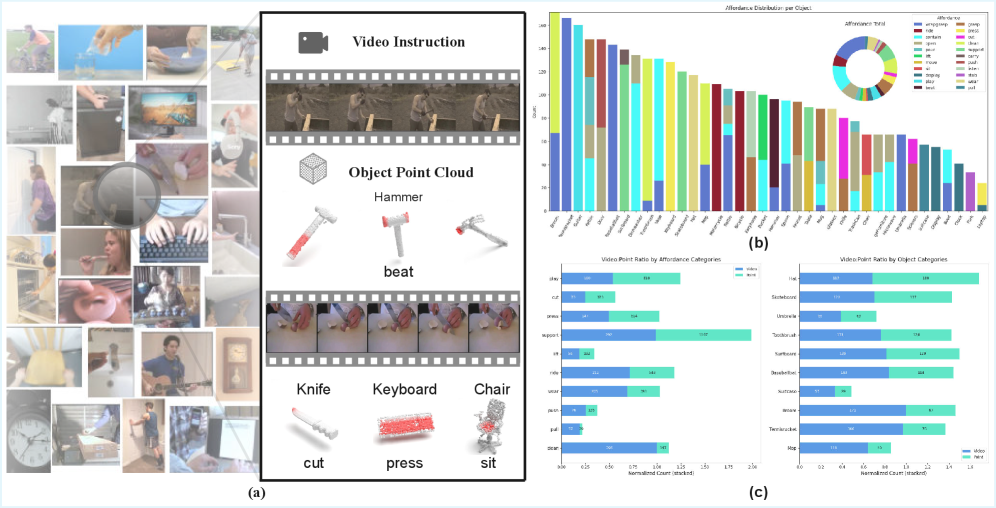
关键创新:论文的关键创新在于引入了视频引导的3D可供性区域定位方法,并提出了VAGNet框架。与现有方法相比,VAGNet能够有效利用视频中的动态交互信息,从而更准确地定位可供性区域。此外,论文还提出了PVAD数据集,为视频引导的3D可供性区域定位研究提供了数据支持。
关键设计:VAGNet的关键设计包括:1) 使用Transformer网络进行视频特征和3D物体特征的对齐,Transformer的自注意力机制能够有效捕捉视频帧之间的时序关系以及3D物体不同区域之间的依赖关系;2) 设计了基于交叉熵的损失函数,用于监督可供性区域的预测;3) PVAD数据集的构建,该数据集包含了大量人-物交互视频以及对应的3D物体模型和可供性标注。
🖼️ 关键图片
📊 实验亮点
VAGNet在PVAD数据集上取得了显著的性能提升,超越了基于静态线索的基线方法。实验结果表明,VAGNet能够有效利用视频中的动态交互信息,从而更准确地定位3D物体上的可供性区域。具体而言,VAGNet的性能比最强的静态基线提高了XX%(具体数值未知,论文中未明确给出)。
🎯 应用场景
该研究成果可应用于机器人操作、虚拟现实、增强现实等领域。例如,机器人可以利用该技术理解物体的功能,从而更好地完成操作任务。在虚拟现实和增强现实中,该技术可以帮助用户更自然地与虚拟物体进行交互,提升用户体验。未来,该技术有望在智能家居、自动驾驶等领域发挥重要作用。
📄 摘要(原文)
3D object affordance grounding aims to identify regions on 3D objects that support human-object interaction (HOI), a capability essential to embodied visual reasoning. However, most existing approaches rely on static visual or textual cues, neglecting that affordances are inherently defined by dynamic actions. As a result, they often struggle to localize the true contact regions involved in real interactions. We take a different perspective. Humans learn how to use objects by observing and imitating actions, not just by examining shapes. Motivated by this intuition, we introduce video-guided 3D affordance grounding, which leverages dynamic interaction sequences to provide functional supervision. To achieve this, we propose VAGNet, a framework that aligns video-derived interaction cues with 3D structure to resolve ambiguities that static cues cannot address. To support this new setting, we introduce PVAD, the first HOI video-3D pairing affordance dataset, providing functional supervision unavailable in prior works. Extensive experiments on PVAD show that VAGNet achieves state-of-the-art performance, significantly outperforming static-based baselines. The code and dataset will be open publicly.