Efficient and Explainable End-to-End Autonomous Driving via Masked Vision-Language-Action Diffusion
作者: Jiaru Zhang, Manav Gagvani, Can Cui, Juntong Peng, Ruqi Zhang, Ziran Wang
分类: cs.CV
发布日期: 2026-02-24
💡 一句话要点
提出MVLAD-AD,通过掩码扩散模型实现高效、可解释的端到端自动驾驶。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 端到端学习 扩散模型 视觉语言模型 动作规划 可解释性 离散动作空间
📋 核心要点
- 现有端到端自动驾驶模型存在推理延迟高、动作精度不足和缺乏可解释性等问题。
- MVLAD-AD通过掩码扩散模型,结合离散动作token化和几何感知嵌入学习,实现高效且可解释的规划。
- 在nuScenes数据集上的实验表明,MVLAD-AD在效率和规划精度上优于现有自回归和扩散模型。
📝 摘要(中文)
大型语言模型(LLMs)和视觉-语言模型(VLMs)已成为端到端自动驾驶的有希望的候选者。然而,这些模型通常面临推理延迟、动作精度和可解释性方面的挑战。现有的自回归方法在逐token生成方面速度较慢,而先前的基于扩散的规划器通常依赖于冗长、通用的语言token,缺乏明确的几何结构。本文提出了用于自动驾驶的掩码视觉-语言-动作扩散(MVLAD-AD),这是一个新颖的框架,旨在通过掩码视觉-语言-动作扩散模型来弥合高效规划和语义可解释性之间的差距。与将动作强制纳入语言空间的方法不同,我们引入了一种离散动作token化策略,该策略从真实驾驶分布中构建运动学上可行的航路点紧凑码本。此外,我们提出了几何感知嵌入学习,以确保潜在空间中的嵌入近似于物理几何度量。最后,引入了一种动作优先级解码策略来优先生成轨迹。在nuScenes和派生基准上的大量实验表明,MVLAD-AD实现了卓越的效率,并在规划精度方面优于最先进的自回归和扩散基线,同时提供了高保真和可解释的推理。
🔬 方法详解
问题定义:现有端到端自动驾驶方法,特别是基于自回归模型和扩散模型的方案,在推理速度、动作控制精度以及可解释性方面存在不足。自回归模型逐token生成速度慢,而传统扩散模型依赖于通用语言token,缺乏对几何结构的显式建模,导致规划效率和精度受限。
核心思路:MVLAD-AD的核心在于利用掩码扩散模型,并结合离散动作token化策略和几何感知嵌入学习,从而在效率、精度和可解释性之间取得平衡。通过将动作空间离散化为运动学可行的航路点,并利用几何信息指导嵌入学习,模型能够更有效地生成高质量的驾驶轨迹。
技术框架:MVLAD-AD框架包含以下几个主要模块:1) 视觉-语言编码器:用于提取场景的视觉和语言特征。2) 离散动作token化:将连续的动作空间离散化为一组运动学可行的航路点,构建紧凑的码本。3) 几何感知嵌入学习:学习潜在空间中的嵌入,使其近似于物理几何度量。4) 掩码扩散模型:基于编码后的视觉-语言特征和离散动作token,通过扩散过程生成驾驶轨迹。5) 动作优先级解码:优先生成重要的轨迹点,提高生成效率。
关键创新:该论文的关键创新在于:1) 提出了一种离散动作token化策略,将连续动作空间映射到运动学可行的航路点码本,避免了直接在语言空间中生成动作,提高了动作精度。2) 引入了几何感知嵌入学习,利用几何信息指导嵌入学习,使得潜在空间中的嵌入能够更好地反映物理世界的几何关系。3) 提出了动作优先级解码策略,加速了轨迹生成过程。
关键设计:离散动作token化策略通过对真实驾驶数据进行聚类分析,得到一组具有代表性的航路点,作为动作码本。几何感知嵌入学习通过引入几何约束损失函数,使得嵌入空间中的距离能够近似于物理空间中的距离。掩码扩散模型采用Transformer架构,并使用掩码策略进行训练,从而学习到动作之间的依赖关系。动作优先级解码策略根据轨迹点的重要性,动态调整采样概率,优先生成关键轨迹点。
🖼️ 关键图片


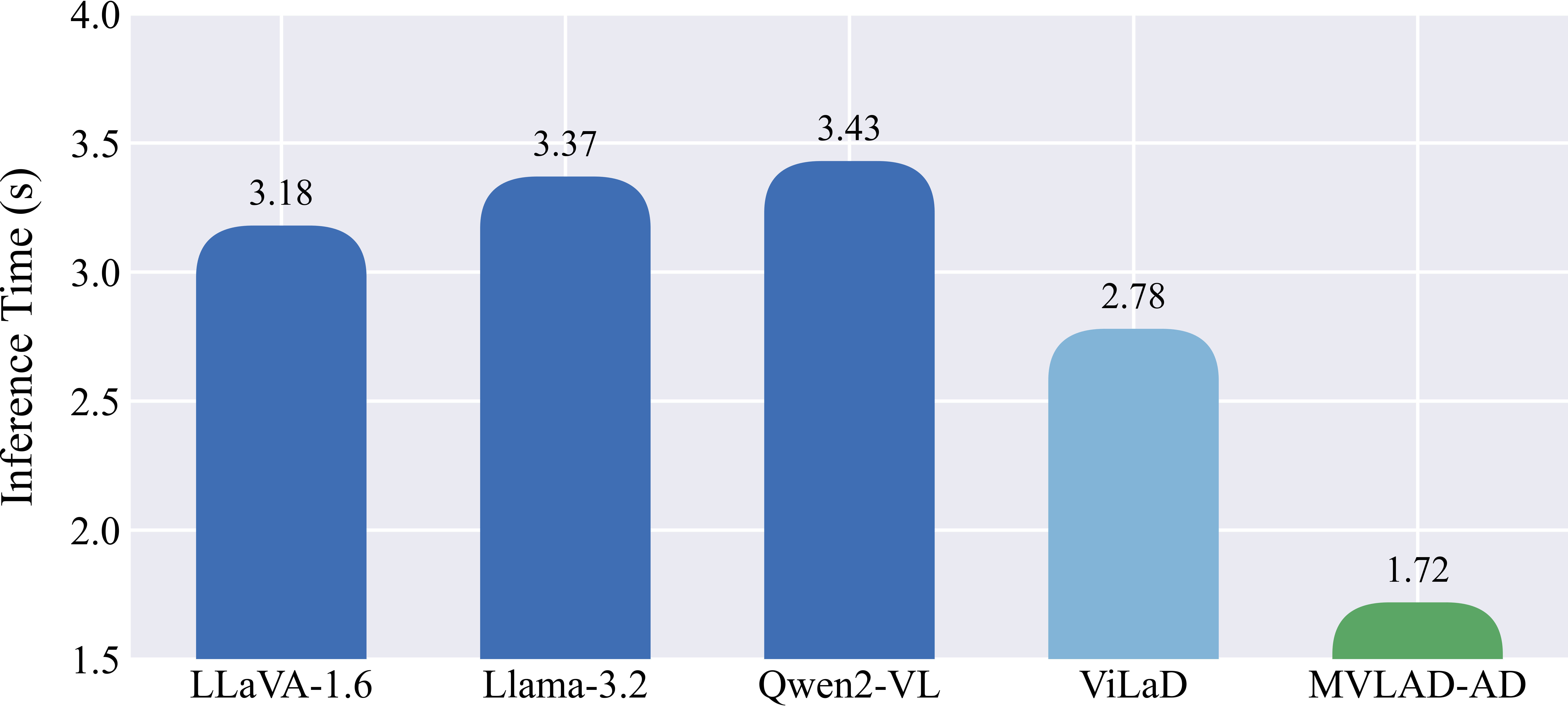
📊 实验亮点
实验结果表明,MVLAD-AD在nuScenes数据集上取得了显著的性能提升。在规划精度方面,MVLAD-AD优于现有的自回归和扩散模型。此外,MVLAD-AD还具有更高的推理效率,能够满足实时自动驾驶的需求。论文还展示了MVLAD-AD生成的可解释性推理过程,为自动驾驶系统的安全性和可靠性提供了保障。
🎯 应用场景
该研究成果可应用于各种自动驾驶场景,包括城市道路、高速公路和停车场等。通过提高自动驾驶系统的效率、精度和可解释性,可以增强驾驶安全性,提升用户体验,并加速自动驾驶技术的商业化落地。此外,该方法还可以扩展到其他机器人领域,例如无人机和移动机器人等。
📄 摘要(原文)
Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged as promising candidates for end-to-end autonomous driving. However, these models typically face challenges in inference latency, action precision, and explainability. Existing autoregressive approaches struggle with slow token-by-token generation, while prior diffusion-based planners often rely on verbose, general-purpose language tokens that lack explicit geometric structure. In this work, we propose Masked Vision-Language-Action Diffusion for Autonomous Driving (MVLAD-AD), a novel framework designed to bridge the gap between efficient planning and semantic explainability via a masked vision-language-action diffusion model. Unlike methods that force actions into the language space, we introduce a discrete action tokenization strategy that constructs a compact codebook of kinematically feasible waypoints from real-world driving distributions. Moreover, we propose geometry-aware embedding learning to ensure that embeddings in the latent space approximate physical geometric metrics. Finally, an action-priority decoding strategy is introduced to prioritize trajectory generation. Extensive experiments on nuScenes and derived benchmarks demonstrate that MVLAD-AD achieves superior efficiency and outperforms state-of-the-art autoregressive and diffusion baselines in planning precision, while providing high-fidelity and explainable reasoning.