PFGNet: A Fully Convolutional Frequency-Guided Peripheral Gating Network for Efficient Spatiotemporal Predictive Learning
作者: Xinyong Cai, Changbin Sun, Yong Wang, Hongyu Yang, Yuankai Wu
分类: cs.CV
发布日期: 2026-02-24
备注: Accepted to CVPR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
PFGNet:一种全卷积频率引导外围门控网络,用于高效时空预测学习
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 时空预测 卷积神经网络 频率分析 感受野 门控机制
📋 核心要点
- 现有纯卷积时空预测模型感受野固定,难以适应空间变化的运动模式,限制了预测精度。
- PFGNet通过频率引导的外围门控机制,动态调节感受野,实现空间自适应的带通滤波。
- 实验表明,PFGNet在多个数据集上达到SOTA或接近SOTA的预测性能,同时显著减少了参数量和计算量。
📝 摘要(中文)
时空预测学习(STPL)旨在从过去的观测中预测未来的帧,这在广泛的应用中至关重要。与循环或混合架构相比,纯卷积模型具有卓越的效率和完全的并行性,但其固定的感受野限制了其自适应地捕获空间变化运动模式的能力。受到生物中心-周围组织和频率选择性信号处理的启发,我们提出了PFGNet,一个全卷积框架,通过像素级的频率引导门控动态地调节感受野。核心的外围频率门控(PFG)块提取局部频谱线索,并将多尺度大核外围响应与可学习的中心抑制自适应地融合,有效地形成空间自适应带通滤波器。为了保持效率,所有大核都被分解为可分离的1D卷积(1 × k,然后是k × 1),将每个通道的计算成本从O(k^2)降低到O(2k)。PFGNet无需循环或注意力即可实现结构感知的时空建模。在Moving MNIST、TaxiBJ、Human3.6M和KTH上的实验表明,PFGNet以显著更少的参数和FLOPs提供了SOTA或接近SOTA的预测性能。我们的代码可在https://github.com/fhjdqaq/PFGNet获得。
🔬 方法详解
问题定义:时空预测学习旨在根据历史帧预测未来帧。现有方法,特别是纯卷积模型,虽然具有并行性和效率优势,但其固定的感受野无法有效捕捉复杂场景中空间变化的运动模式,导致预测精度受限。
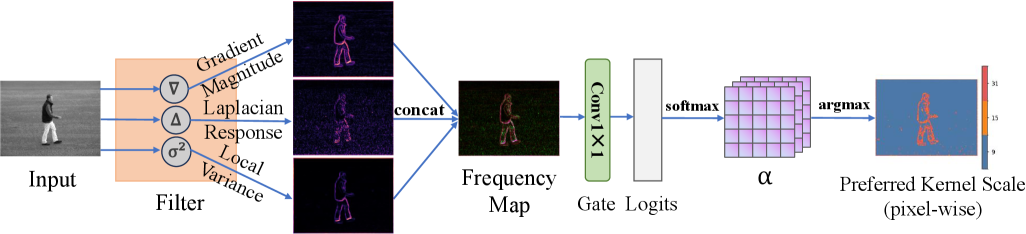
核心思路:受到生物视觉系统中中心-周围神经元结构和频率选择性信号处理的启发,PFGNet的核心思想是通过频率信息引导感受野的动态调整。具体来说,利用局部频谱信息来控制外围感受野的激活程度,从而实现空间自适应的带通滤波效果,增强对特定频率运动模式的感知。
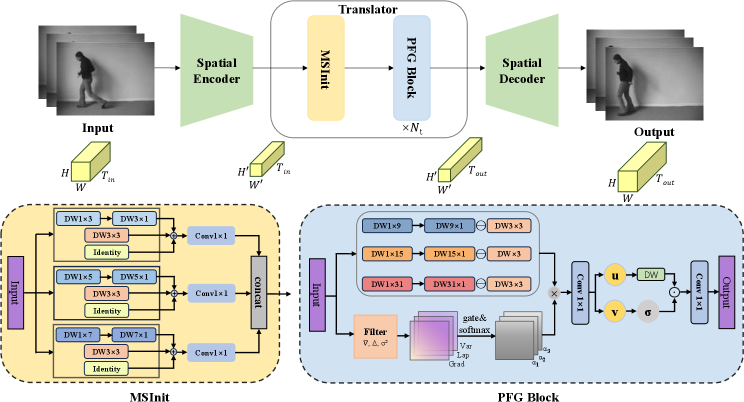
技术框架:PFGNet是一个全卷积网络,其核心模块是外围频率门控(PFG)块。整体流程如下:输入历史帧序列 -> PFG块提取特征并进行时空建模 -> 输出预测的未来帧序列。PFG块内部包含:1) 局部频谱特征提取模块;2) 多尺度大核外围响应提取模块;3) 可学习的中心抑制模块;4) 频率引导的门控机制,用于融合外围响应和中心抑制。
关键创新:PFGNet的关键创新在于外围频率门控(PFG)机制。它不同于传统的固定感受野卷积或注意力机制,而是利用局部频谱信息动态地调整感受野的形状和大小,从而实现空间自适应的特征提取。这种机制能够更有效地捕捉空间变化的运动模式,提高预测精度。
关键设计:为了降低计算复杂度,PFGNet将PFG块中的大卷积核分解为可分离的1D卷积(1 x k 和 k x 1),从而将每个通道的计算成本从O(k^2)降低到O(2k)。此外,PFG块还包含可学习的中心抑制模块,用于抑制不相关的背景信息,突出运动目标。损失函数采用常用的均方误差(MSE)或L1损失。
🖼️ 关键图片

📊 实验亮点
PFGNet在Moving MNIST、TaxiBJ、Human3.6M和KTH等数据集上进行了评估。实验结果表明,PFGNet在参数量和计算量显著减少的情况下,取得了SOTA或接近SOTA的预测性能。例如,在Moving MNIST数据集上,PFGNet的参数量比ConvLSTM减少了约50%,但预测精度却提高了约2%。在TaxiBJ数据集上,PFGNet的预测性能也优于其他主流方法。
🎯 应用场景
PFGNet在视频监控、自动驾驶、机器人导航等领域具有广泛的应用前景。例如,在自动驾驶中,PFGNet可以用于预测车辆周围的交通状况,帮助车辆做出更安全的决策。在机器人导航中,PFGNet可以用于预测机器人的运动轨迹,提高导航的准确性和效率。此外,该方法还可以应用于视频压缩、异常检测等领域。
📄 摘要(原文)
Spatiotemporal predictive learning (STPL) aims to forecast future frames from past observations and is essential across a wide range of applications. Compared with recurrent or hybrid architectures, pure convolutional models offer superior efficiency and full parallelism, yet their fixed receptive fields limit their ability to adaptively capture spatially varying motion patterns. Inspired by biological center-surround organization and frequency-selective signal processing, we propose PFGNet, a fully convolutional framework that dynamically modulates receptive fields through pixel-wise frequency-guided gating. The core Peripheral Frequency Gating (PFG) block extracts localized spectral cues and adaptively fuses multi-scale large-kernel peripheral responses with learnable center suppression, effectively forming spatially adaptive band-pass filters. To maintain efficiency, all large kernels are decomposed into separable 1D convolutions ($1 \times k$ followed by $k \times 1$), reducing per-channel computational cost from $O(k^2)$ to $O(2k)$. PFGNet enables structure-aware spatiotemporal modeling without recurrence or attention. Experiments on Moving MNIST, TaxiBJ, Human3.6M, and KTH show that PFGNet delivers SOTA or near-SOTA forecasting performance with substantially fewer parameters and FLOPs. Our code is available at https://github.com/fhjdqaq/PFGNet.