Probing and Bridging Geometry-Interaction Cues for Affordance Reasoning in Vision Foundation Models
作者: Qing Zhang, Xuesong Li, Jing Zhang
分类: cs.CV
发布日期: 2026-02-24
备注: 11 pages, 12 figures, Accepted to CVPR 2026
💡 一句话要点
融合几何与交互线索,零样本提升视觉基础模型的可供性推理能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可供性推理 视觉基础模型 几何感知 交互感知 零样本学习
📋 核心要点
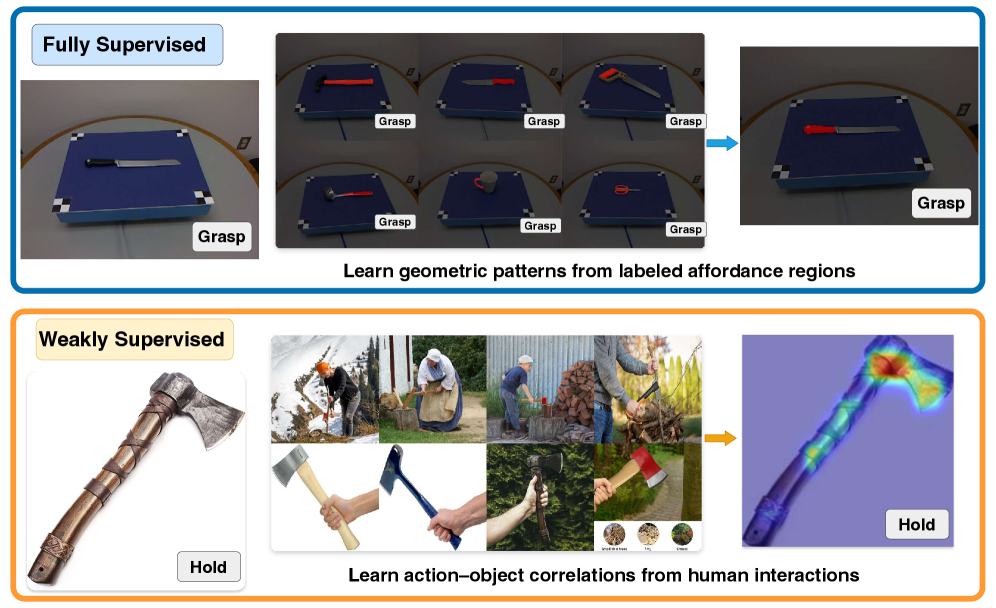
- 现有方法在可供性理解上不足,缺乏对几何结构和交互行为的有效结合。
- 论文提出融合几何感知和交互感知,利用视觉基础模型中已有的几何结构和交互先验。
- 通过零样本融合DINO和Flux的特征,实现了与弱监督方法相当的可供性估计性能。
📝 摘要(中文)
本文探讨了视觉系统理解可供性的关键要素:几何感知(识别物体中实现交互的结构部分)和交互感知(建模智能体的动作如何与这些部分交互)。通过对视觉基础模型(VFMs)的系统性探究,发现DINO等模型固有地编码了部件级别的几何结构,而Flux等生成模型包含丰富的、以动词为条件的空间注意力图,作为隐式的交互先验。研究表明,这两个维度不仅相关,而且是可组合的可供性元素。通过简单地将DINO的几何原型与Flux的交互图融合,无需训练即可实现与弱监督方法相媲美的可供性估计。该融合实验证实了几何和交互感知是VFMs中可供性理解的基本组成部分,为感知如何支撑动作提供了一种机制解释。
🔬 方法详解
问题定义:论文旨在解决视觉基础模型(VFMs)如何理解可供性的问题。现有的方法通常需要大量的标注数据进行训练,或者难以有效地结合几何结构和交互行为的信息。因此,如何利用VFMs中已有的知识,实现零样本或少样本的可供性推理是一个挑战。
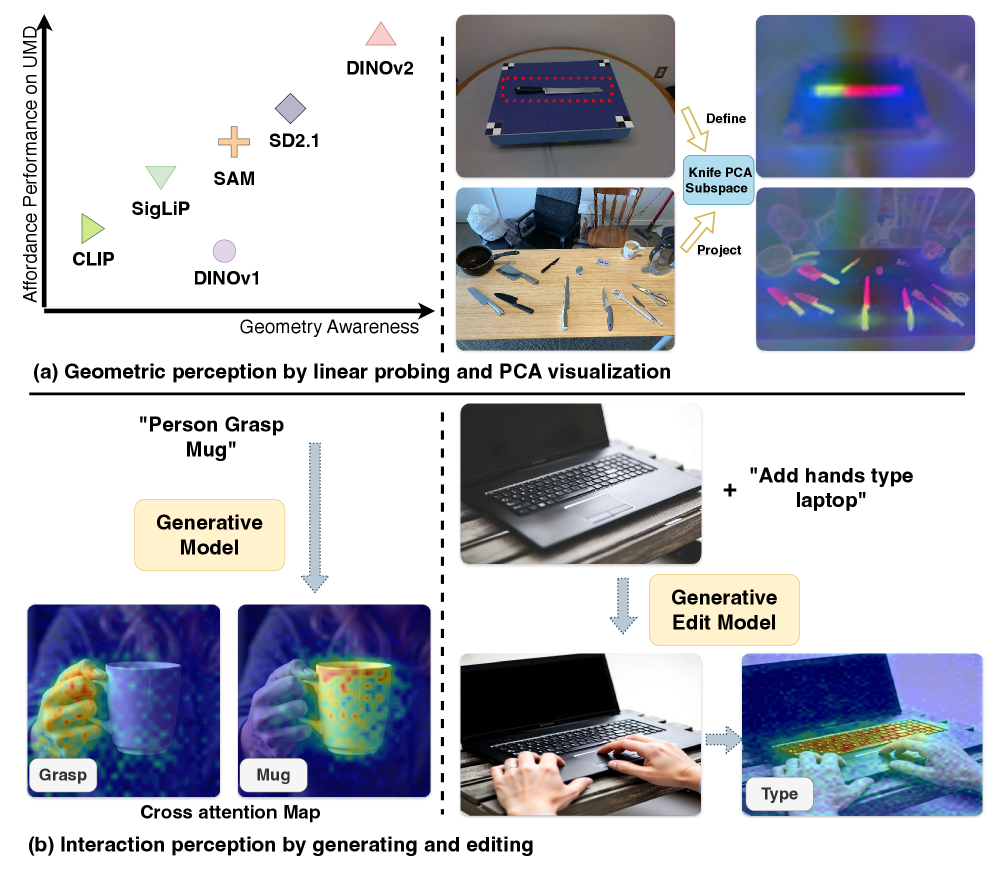
核心思路:论文的核心思路是将可供性理解分解为两个关键要素:几何感知和交互感知。几何感知负责识别物体中能够进行交互的结构部分,而交互感知则负责建模智能体的动作如何与这些部分进行交互。通过将这两个要素结合起来,可以更全面地理解可供性。
技术框架:论文的技术框架主要包括以下几个步骤:1) 使用DINO等模型提取图像的几何特征,这些特征能够反映物体部件的结构信息。2) 使用Flux等生成模型提取图像的交互特征,这些特征能够反映不同动作与物体之间的关系。3) 将DINO的几何特征与Flux的交互特征进行融合,得到最终的可供性估计。整个过程是零样本的,不需要额外的训练数据。
关键创新:论文最重要的技术创新点在于提出了将几何感知和交互感知相结合的可供性理解方法。与以往的方法相比,该方法能够更有效地利用VFMs中已有的知识,实现零样本的可供性推理。此外,论文还发现DINO和Flux等模型分别编码了几何结构和交互先验,为可供性理解提供了基础。
关键设计:论文的关键设计在于如何融合DINO的几何特征和Flux的交互特征。具体来说,论文采用了简单的特征融合方法,例如将DINO的几何原型与Flux的交互图进行加权平均。此外,论文还探索了不同的融合策略,例如使用注意力机制来动态地调整几何特征和交互特征的权重。论文没有详细说明具体的参数设置和损失函数,因为该方法是零样本的,不需要训练。
🖼️ 关键图片

📊 实验亮点
该研究通过零样本融合DINO的几何原型和Flux的交互图,实现了与弱监督方法相媲美的可供性估计性能。这一结果表明,视觉基础模型已经具备了理解可供性的基本能力,并且可以通过简单的特征融合来有效地利用这些能力。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于机器人操作、人机交互、虚拟现实等领域。例如,机器人可以利用可供性信息来规划抓取、放置等动作;人机交互系统可以根据用户的动作预测其意图;虚拟现实系统可以为用户提供更真实、更自然的交互体验。该研究有助于提升智能系统的自主性和适应性。
📄 摘要(原文)
What does it mean for a visual system to truly understand affordance? We argue that this understanding hinges on two complementary capacities: geometric perception, which identifies the structural parts of objects that enable interaction, and interaction perception, which models how an agent's actions engage with those parts. To test this hypothesis, we conduct a systematic probing of Visual Foundation Models (VFMs). We find that models like DINO inherently encode part-level geometric structures, while generative models like Flux contain rich, verb-conditioned spatial attention maps that serve as implicit interaction priors. Crucially, we demonstrate that these two dimensions are not merely correlated but are composable elements of affordance. By simply fusing DINO's geometric prototypes with Flux's interaction maps in a training-free and zero-shot manner, we achieve affordance estimation competitive with weakly-supervised methods. This final fusion experiment confirms that geometric and interaction perception are the fundamental building blocks of affordance understanding in VFMs, providing a mechanistic account of how perception grounds action.