Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
作者: Abdelrahman Shaker, Ahmed Heakl, Jaseel Muhammad, Ritesh Thawkar, Omkar Thawakar, Senmao Li, Hisham Cholakkal, Ian Reid, Eric P. Xing, Salman Khan, Fahad Shahbaz Khan
分类: cs.CV
发布日期: 2026-02-23
备注: Project page: https://amshaker.github.io/Mobile-O/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Mobile-O,一种在移动设备上实现统一多模态理解和生成的紧凑型模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 扩散模型 移动设备 边缘计算
📋 核心要点
- 现有统一多模态模型计算量大,难以在算力受限的移动设备上部署。
- Mobile-O通过Mobile Conditioning Projector (MCP) 模块,高效融合视觉-语言特征与扩散模型,实现跨模态条件控制。
- 实验表明,Mobile-O在移动设备上实现了优异的生成和理解性能,且速度显著提升。
📝 摘要(中文)
统一多模态模型可以在单个架构中理解和生成视觉内容。然而,现有模型对数据需求量大,且过于庞大,难以部署在边缘设备上。本文提出了Mobile-O,一个紧凑的视觉-语言-扩散模型,将统一的多模态智能带到移动设备上。其核心模块Mobile Conditioning Projector (MCP) 使用深度可分离卷积和逐层对齐将视觉-语言特征与扩散生成器融合。这种设计以最小的计算成本实现了高效的跨模态条件控制。Mobile-O仅在数百万个样本上进行训练,并以一种新颖的四元组格式(生成提示、图像、问题、答案)进行后训练,从而共同增强了视觉理解和生成能力。尽管效率很高,但Mobile-O与其他统一模型相比,获得了有竞争力或更优越的性能,在GenEval上达到74%,并且比Show-O和JanusFlow分别高出5%和11%,同时运行速度分别快6倍和11倍。对于视觉理解,Mobile-O在七个基准测试中平均超过它们15.3%和5.1%。Mobile-O在iPhone上每张512x512图像仅需约3秒即可运行,从而为边缘设备上实时统一多模态理解和生成建立了第一个实用的框架。我们希望Mobile-O能够促进未来完全在设备上运行且无需云依赖的实时统一多模态智能的研究。我们的代码、模型、数据集和移动应用程序可在https://amshaker.github.io/Mobile-O/公开获取。
🔬 方法详解
问题定义:论文旨在解决统一多模态模型在移动设备上部署的问题。现有模型通常参数量巨大,计算复杂度高,无法满足移动设备实时性和低功耗的需求。因此,如何在资源受限的边缘设备上实现高效的多模态理解和生成是本文要解决的核心问题。
核心思路:Mobile-O的核心思路是设计一个轻量级的视觉-语言-扩散模型,通过高效的跨模态融合机制,在保证性能的同时,显著降低计算成本。该模型采用Mobile Conditioning Projector (MCP) 模块,利用深度可分离卷积和逐层对齐技术,实现视觉和语言特征与扩散模型的有效融合。
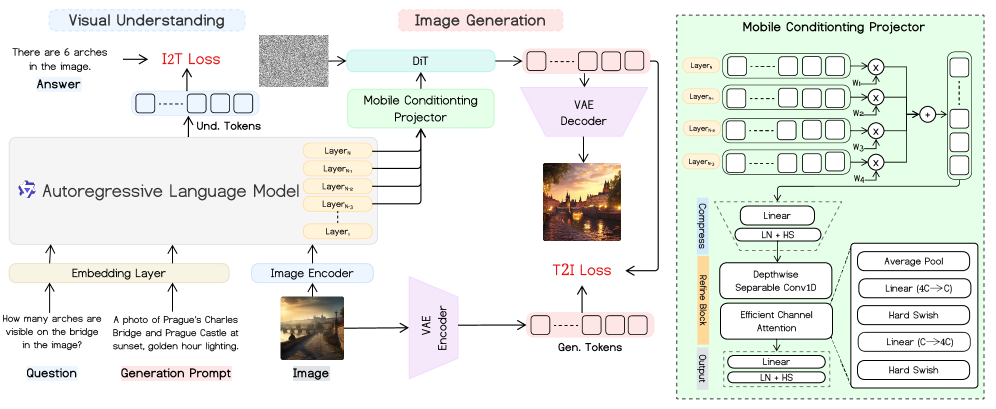
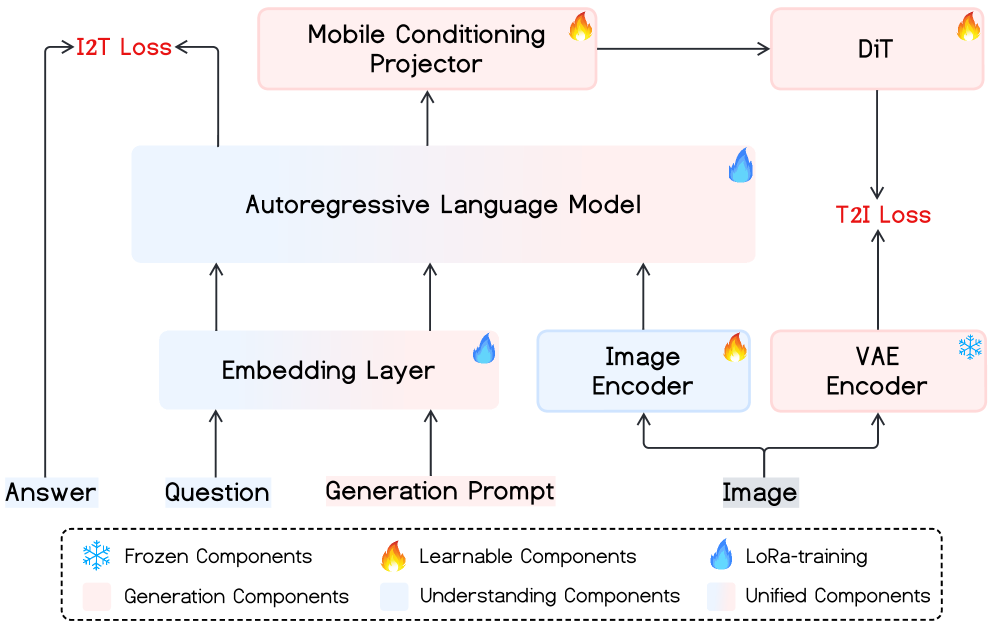
技术框架:Mobile-O的整体架构包含视觉编码器、语言编码器、Mobile Conditioning Projector (MCP) 和扩散模型。首先,视觉编码器和语言编码器分别提取图像和文本的特征。然后,MCP模块将这些特征融合,并将其作为条件输入到扩散模型中。扩散模型根据给定的条件生成图像。整个流程实现了从文本到图像的生成,以及图像和文本的联合理解。
关键创新:Mobile-O最重要的技术创新点在于MCP模块的设计。MCP模块使用深度可分离卷积来降低计算复杂度,并采用逐层对齐技术来更好地融合不同模态的特征。与传统的跨模态融合方法相比,MCP模块在计算效率和特征融合效果上都具有优势。此外,论文还提出了一个新颖的四元组训练格式,进一步提升了模型的性能。
关键设计:MCP模块的关键设计包括:1) 深度可分离卷积的使用,显著减少了参数量和计算量;2) 逐层对齐技术,通过学习不同层之间的对齐关系,更好地融合视觉和语言特征;3) 四元组训练格式(生成提示、图像、问题、答案),增强了模型在视觉理解和生成方面的能力。具体的损失函数和网络结构细节在论文中有详细描述,此处不再赘述。
🖼️ 关键图片
📊 实验亮点
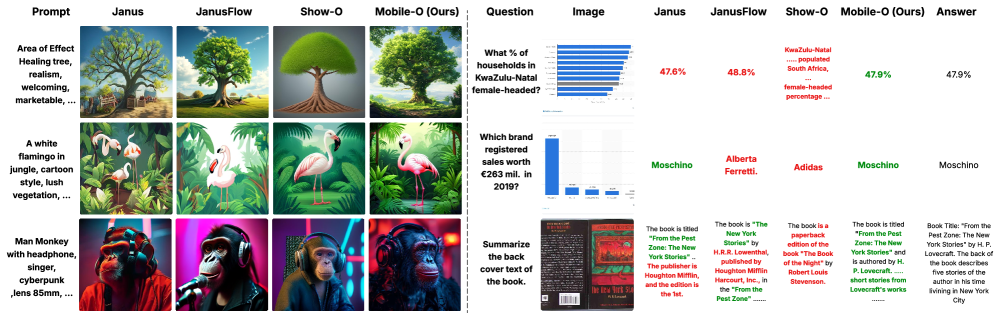
Mobile-O在GenEval上达到了74%的性能,超越了Show-O和JanusFlow,分别提升了5%和11%,同时运行速度分别快6倍和11倍。在七个视觉理解基准测试中,Mobile-O平均超过它们15.3%和5.1%。该模型在iPhone上生成一张512x512的图像仅需约3秒,证明了其在移动设备上实时运行的可行性。
🎯 应用场景
Mobile-O在移动设备上具有广泛的应用前景,例如:智能手机上的图像生成、编辑和增强;移动机器人中的视觉导航和场景理解;辅助驾驶系统中的环境感知和决策;以及AR/VR应用中的沉浸式体验。该研究为边缘计算设备上的多模态人工智能应用开辟了新的可能性。
📄 摘要(原文)
Unified multimodal models can both understand and generate visual content within a single architecture. Existing models, however, remain data-hungry and too heavy for deployment on edge devices. We present Mobile-O, a compact vision-language-diffusion model that brings unified multimodal intelligence to a mobile device. Its core module, the Mobile Conditioning Projector (MCP), fuses vision-language features with a diffusion generator using depthwise-separable convolutions and layerwise alignment. This design enables efficient cross-modal conditioning with minimal computational cost. Trained on only a few million samples and post-trained in a novel quadruplet format (generation prompt, image, question, answer), Mobile-O jointly enhances both visual understanding and generation capabilities. Despite its efficiency, Mobile-O attains competitive or superior performance compared to other unified models, achieving 74% on GenEval and outperforming Show-O and JanusFlow by 5% and 11%, while running 6x and 11x faster, respectively. For visual understanding, Mobile-O surpasses them by 15.3% and 5.1% averaged across seven benchmarks. Running in only ~3s per 512x512 image on an iPhone, Mobile-O establishes the first practical framework for real-time unified multimodal understanding and generation on edge devices. We hope Mobile-O will ease future research in real-time unified multimodal intelligence running entirely on-device with no cloud dependency. Our code, models, datasets, and mobile application are publicly available at https://amshaker.github.io/Mobile-O/