Do Large Language Models Understand Data Visualization Rules?
作者: Martin Sinnona, Valentin Bonas, Emmanuel Iarussi, Viviana Siless
分类: cs.CV
发布日期: 2026-02-23
💡 一句话要点
评估大型语言模型理解数据可视化规则的能力,并探索其作为规则验证器的潜力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据可视化 规则验证 自然语言处理 Answer Set Programming
📋 核心要点
- 现有方法难以维护数据可视化规则的符号编码,需要专家投入大量精力。
- 将数据可视化规则转化为自然语言,利用LLM进行规则验证,提高灵活性。
- 实验表明,LLM在检测常见违规方面表现良好,但在处理微妙规则时性能下降。
📝 摘要(中文)
本文首次系统性地评估了大型语言模型(LLMs)在数据可视化规则理解方面的能力。这些规则源于设计和感知领域数十年的研究,旨在确保图表传达的可信度。研究使用从Answer Set Programming (ASP) 推导出的硬验证真值,针对LLMs进行了评估。研究人员将Draco约束的一个子集翻译成自然语言语句,并生成了一个包含2000个Vega-Lite规范的受控数据集,这些规范带有明确的规则违反注释。评估指标包括检测违规的准确性和提示遵循度。结果表明,前沿模型实现了高提示遵循度(Gemma 3 4B / 27B: 100%, GPT-oss 20B: 98%),并能可靠地检测常见违规(F1高达0.82),但对于更微妙的感知规则(某些类别的F1 < 0.15)以及从技术性ASP公式生成的输出,性能有所下降。将约束翻译成自然语言使较小模型的性能提高了高达150%。这些发现证明了LLMs作为灵活的、语言驱动的验证器的潜力,同时也突出了它们与符号求解器相比的当前局限性。
🔬 方法详解
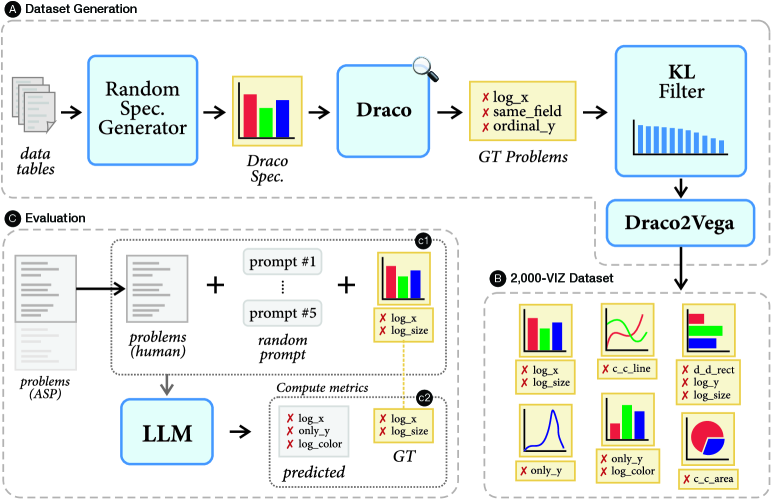
问题定义:论文旨在解决大型语言模型(LLMs)是否能够理解并执行数据可视化规则的问题。现有方法,如基于约束的系统(例如Draco),虽然可以精确地进行自动化检查,但维护符号编码需要大量的专家知识和努力,缺乏灵活性。因此,需要探索一种更灵活的规则验证方法。
核心思路:论文的核心思路是将数据可视化规则从符号编码(Draco约束)转换为自然语言描述,然后利用LLMs的自然语言理解能力来检测图表中是否存在违反这些规则的情况。这种方法旨在利用LLMs的灵活性和易用性,降低规则验证的维护成本。
技术框架:整体框架包括以下几个主要步骤:1) 将Draco的约束子集翻译成自然语言语句;2) 生成一个包含2000个Vega-Lite规范的受控数据集,其中包含明确的规则违反注释;3) 使用LLMs对数据集中的图表进行规则验证,并评估其准确性和提示遵循度;4) 分析LLMs在不同类型规则上的表现,并与符号求解器进行比较。
关键创新:论文的关键创新在于首次系统性地评估了LLMs在数据可视化规则理解方面的能力,并探索了LLMs作为灵活的、语言驱动的规则验证器的潜力。与传统的基于符号编码的方法相比,该方法具有更高的灵活性和易用性,可以降低规则验证的维护成本。
关键设计:论文的关键设计包括:1) 将Draco约束翻译成自然语言语句,以便LLMs能够理解;2) 生成一个包含明确规则违反注释的Vega-Lite规范数据集,用于评估LLMs的性能;3) 使用不同的LLMs(例如Gemma 3 4B / 27B, GPT-oss 20B)进行实验,并比较它们在不同类型规则上的表现;4) 评估指标包括检测违规的准确性(F1 score)和提示遵循度。
🖼️ 关键图片
📊 实验亮点
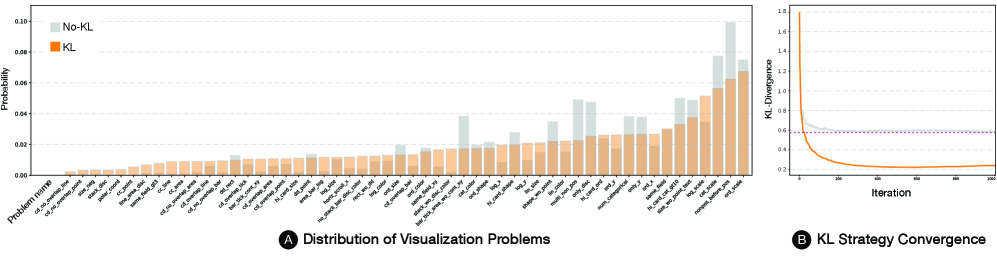
实验结果表明,前沿LLM模型(Gemma 3 4B / 27B, GPT-oss 20B)在检测常见可视化违规方面表现良好,F1值高达0.82。然而,对于更微妙的感知规则,性能显著下降(某些类别F1 < 0.15)。将约束翻译成自然语言后,较小模型的性能提升高达150%。
🎯 应用场景
该研究成果可应用于自动化数据可视化质量控制、辅助数据分析师进行图表设计、以及开发智能数据可视化教学工具。通过利用LLM理解和执行可视化规则,可以提高数据可视化的准确性和可信度,并降低人工审核的成本。
📄 摘要(原文)
Data visualization rules-derived from decades of research in design and perception-ensure trustworthy chart communication. While prior work has shown that large language models (LLMs) can generate charts or flag misleading figures, it remains unclear whether they can reason about and enforce visualization rules directly. Constraint-based systems such as Draco encode these rules as logical constraints for precise automated checks, but maintaining symbolic encodings requires expert effort, motivating the use of LLMs as flexible rule validators. In this paper, we present the first systematic evaluation of LLMs against visualization rules using hard-verification ground truth derived from Answer Set Programming (ASP). We translated a subset of Draco's constraints into natural-language statements and generated a controlled dataset of 2,000 Vega-Lite specifications annotated with explicit rule violations. LLMs were evaluated on both accuracy in detecting violations and prompt adherence, which measures whether outputs follow the required structured format. Results show that frontier models achieve high adherence (Gemma 3 4B / 27B: 100%, GPT-oss 20B: 98%) and reliably detect common violations (F1 up to 0.82),yet performance drops for subtler perceptual rules (F1 < 0.15 for some categories) and for outputs generated from technical ASP formulations.Translating constraints into natural language improved performance by up to 150% for smaller models. These findings demonstrate the potential of LLMs as flexible, language-driven validators while highlighting their current limitations compared to symbolic solvers.