Closing the gap in multimodal medical representation alignment
作者: Eleonora Grassucci, Giordano Cicchetti, Danilo Comminiello
分类: cs.CV, cs.LG
发布日期: 2026-02-23
备注: Accepted at MLSP2025
💡 一句话要点
提出一种模态无关框架,弥合医学多模态表征对齐中的模态差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 医学影像 自然语言处理 表征对齐 对比学习 模态差距 跨模态检索
📋 核心要点
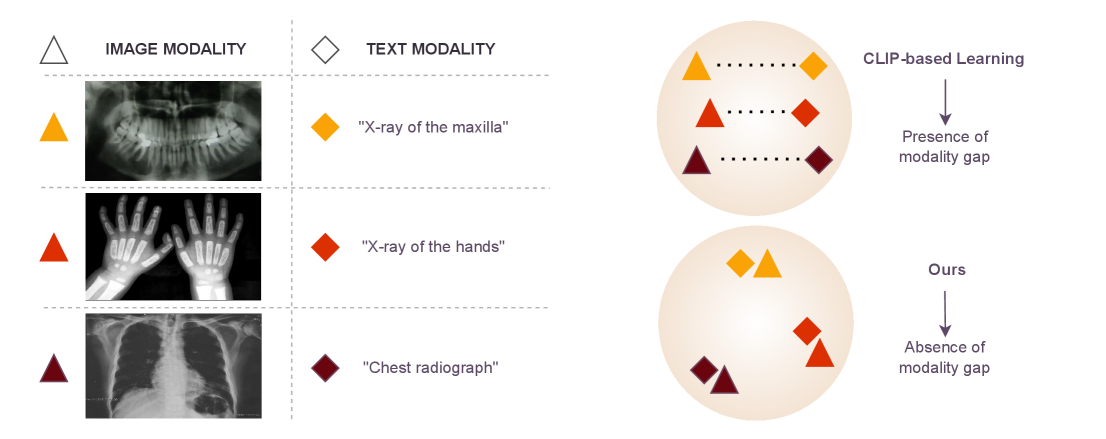
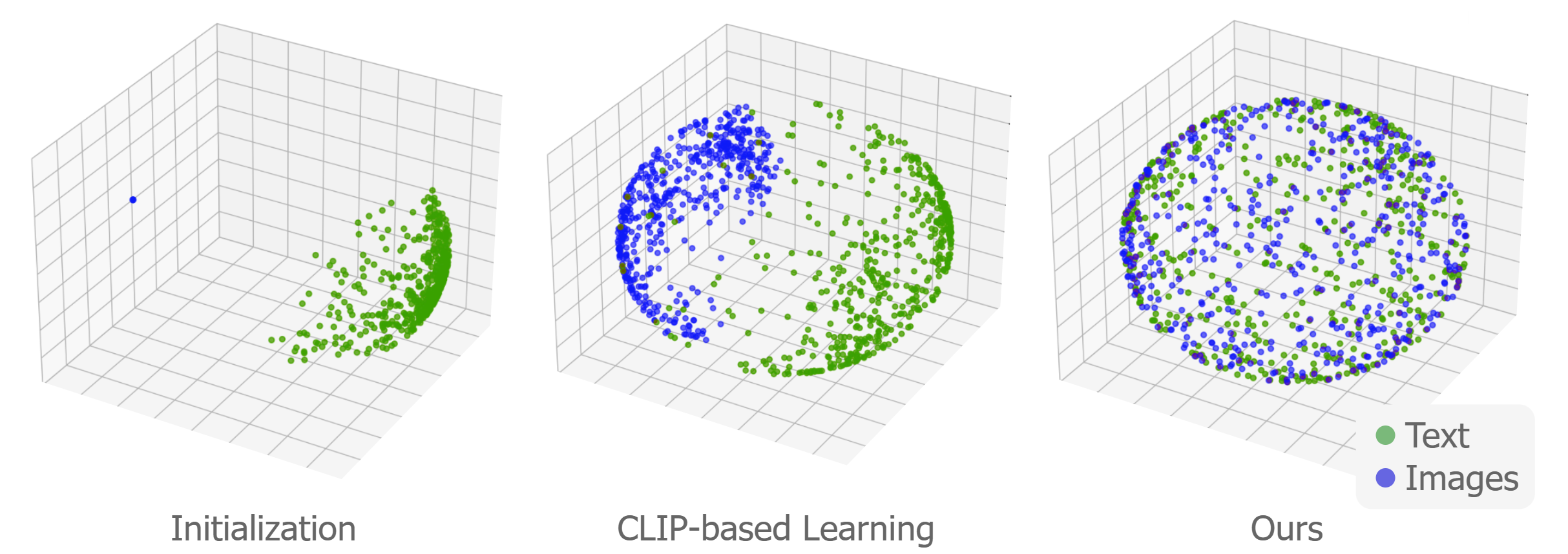
- CLIP在多模态学习中被广泛应用,但其对比损失会导致模态差距,影响语义对齐。
- 论文提出一种模态无关框架,旨在缩小医学多模态数据中的模态差距,提升表征对齐。
- 实验表明,该方法能够有效提升放射影像和临床文本的对齐效果,改善跨模态检索和图像描述性能。
📝 摘要(中文)
在多模态学习中,CLIP已成为将不同模态映射到共享潜在空间的常用方法,它通过拉近语义相似的表征,推开不相似的表征来实现这一目标。然而,基于CLIP的对比损失表现出一些非预期的行为,这些行为会对真实的语义对齐产生负面影响,导致潜在空间变得稀疏和碎片化。这种现象被称为模态差距,在标准的文本和图像对中已得到部分缓解,但在更复杂的多模态环境中,如医学领域,仍然未知且未解决。本文研究了医学领域中的这种现象,揭示了模态差距同样存在于医学对齐中。为此,我们提出了一种模态无关的框架来弥合这一差距,确保语义相关的表征能够更好地对齐,而无需考虑它们的来源模态。我们的方法增强了放射影像和临床文本之间的对齐,从而改进了跨模态检索和图像描述。
🔬 方法详解
问题定义:论文旨在解决医学多模态数据(如放射影像和临床文本)表征对齐中的模态差距问题。现有基于CLIP的方法在医学领域表现出语义对齐不佳,导致潜在空间稀疏和碎片化,阻碍了跨模态信息的有效利用。
核心思路:论文的核心思路是设计一个模态无关的框架,该框架能够促进语义相关的表征在潜在空间中更好地对齐,而无需考虑其来源模态。通过增强不同模态间表征的关联性,从而弥合模态差距。
技术框架:该框架包含以下主要模块:1) 多模态编码器:用于提取放射影像和临床文本的特征表示。2) 对比学习模块:利用对比损失函数,促使语义相似的表征靠近,不相似的表征远离。3) 模态对齐模块:该模块是核心创新,通过引入额外的约束或损失函数,显式地增强不同模态表征之间的对齐。具体实现细节未知。
关键创新:最重要的技术创新点在于模态对齐模块的设计,该模块能够有效地弥合模态差距,提升多模态表征的对齐效果。与现有方法相比,该方法更加关注不同模态之间的关联性,从而更好地利用多模态信息。
关键设计:论文中关键的设计细节包括:1) 模态对齐模块的具体实现方式(例如,采用何种约束或损失函数)。2) 对比学习损失函数的选择和参数设置。3) 多模态编码器的网络结构和预训练策略。这些细节将直接影响最终的对齐效果。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了所提出方法的有效性。实验结果表明,该方法能够显著提升放射影像和临床文本的对齐效果,从而改进跨模态检索和图像描述的性能。具体的性能数据和提升幅度未知,但摘要中明确指出该方法能够增强模态间的对齐。
🎯 应用场景
该研究成果可应用于多种医学领域,例如:辅助诊断、疾病预测、医学影像报告生成等。通过提升放射影像和临床文本的对齐效果,可以帮助医生更准确地理解病情,提高诊断效率。此外,该方法还可以应用于医学教育和研究,促进医学知识的传播和创新。
📄 摘要(原文)
In multimodal learning, CLIP has emerged as the de-facto approach for mapping different modalities into a shared latent space by bringing semantically similar representations closer while pushing apart dissimilar ones. However, CLIP-based contrastive losses exhibit unintended behaviors that negatively impact true semantic alignment, leading to sparse and fragmented latent spaces. This phenomenon, known as the modality gap, has been partially mitigated for standard text and image pairs but remains unknown and unresolved in more complex multimodal settings, such as the medical domain. In this work, we study this phenomenon in the latter case, revealing that the modality gap is present also in medical alignment, and we propose a modality-agnostic framework that closes this gap, ensuring that semantically related representations are more aligned, regardless of their source modality. Our method enhances alignment between radiology images and clinical text, improving cross-modal retrieval and image captioning.