RL-RIG: A Generative Spatial Reasoner via Intrinsic Reflection
作者: Tianyu Wang, Zhiyuan Ma, Qian Wang, Xinyi Zhang, Xinwei Long, Bowen Zhou
分类: cs.CV
发布日期: 2026-02-23
💡 一句话要点
提出RL-RIG以解决图像生成中的空间推理问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像生成 空间推理 强化学习 反射机制 结构合理性 深度学习 计算机视觉
📋 核心要点
- 现有图像生成模型在捕捉空间关系和生成结构合理场景方面存在明显不足,导致生成内容缺乏空间一致性。
- RL-RIG通过生成-反射-编辑的框架,结合强化学习和反射机制,提升了模型对生成过程的理解和空间推理能力。
- 实验结果表明,RL-RIG在空间推理的可控性和精确性上,相较于现有最先进的开源模型提升了11%。
📝 摘要(中文)
近年来,图像生成技术取得了显著进展,但现有模型在空间推理方面仍面临挑战,难以准确捕捉细粒度的空间关系。为此,本文提出了RL-RIG,一个基于反射的图像生成强化学习框架。该架构包含四个主要组件:Diffuser、Checker、Actor和Inverse Diffuser,采用生成-反射-编辑的范式,旨在提升图像生成中的思维链推理能力。通过引入Reflection-GRPO,模型在编辑提示和图像质量方面得到了进一步优化。与传统方法不同,RL-RIG在评估生成图像的空间一致性时,优先考虑空间准确性,实验结果显示其在可控和精确的空间推理方面比现有开源模型提升了多达11%。
🔬 方法详解
问题定义:本文旨在解决现有图像生成模型在空间推理方面的不足,尤其是在生成结构合理且空间关系准确的图像时的挑战。现有方法往往只关注视觉效果,忽视了空间一致性的问题。
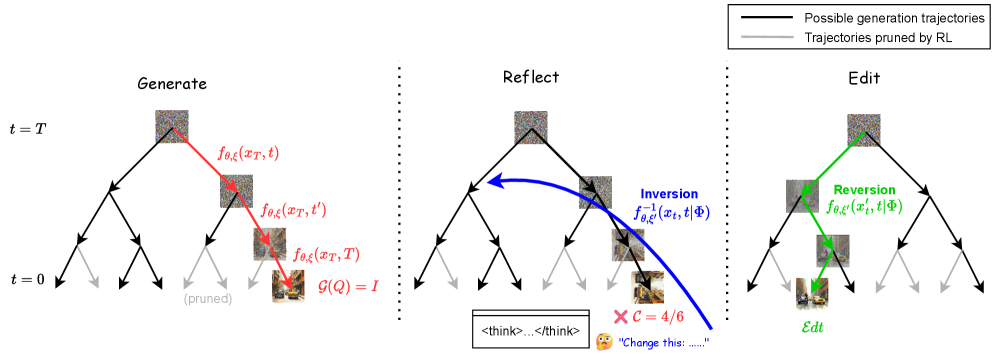
核心思路:RL-RIG的核心思路是通过生成-反射-编辑的范式,结合强化学习来提升模型的空间推理能力。通过反射机制,模型能够更好地理解生成过程中的空间关系,从而生成更具结构合理性的图像。
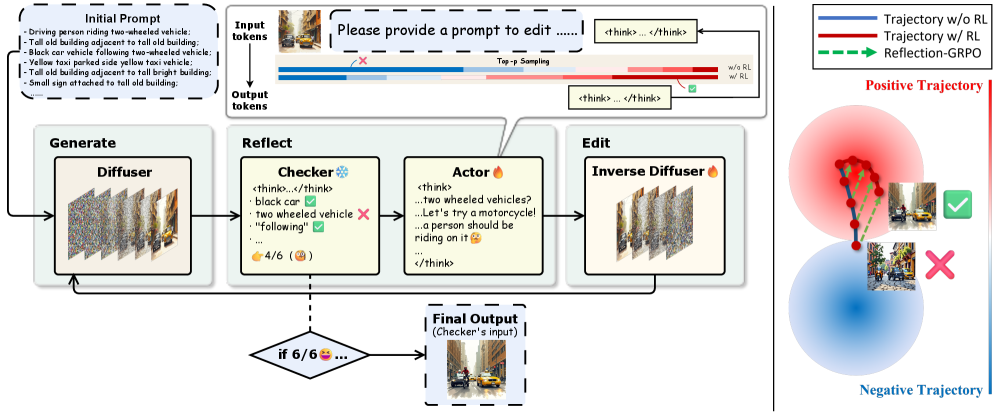
技术框架:RL-RIG的整体架构包括四个主要模块:Diffuser负责初步图像生成,Checker用于验证生成的空间一致性,Actor基于反射机制进行编辑,Inverse Diffuser则用于优化最终图像质量。
关键创新:RL-RIG的主要创新在于引入了反射机制和强化学习相结合的框架,使得模型不仅能生成视觉上吸引人的图像,还能确保其空间关系的准确性。这与传统方法的单一视觉优化形成了鲜明对比。
关键设计:在模型设计中,采用了Reflection-GRPO来训练VLM Actor以处理编辑提示,并优化图像编辑器以提高图像质量。此外,评估指标采用了Scene Graph IoU和VLM-as-a-Judge策略,确保生成图像的空间一致性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,RL-RIG在空间推理的可控性和精确性方面,相较于现有的最先进开源模型提升了多达11%。通过采用Scene Graph IoU和VLM-as-a-Judge策略,RL-RIG在空间一致性评估中表现优异,展现了其在图像生成领域的显著优势。
🎯 应用场景
RL-RIG的研究成果具有广泛的应用潜力,特别是在需要高质量图像生成的领域,如虚拟现实、游戏设计和自动化内容创作等。通过提升图像生成的空间推理能力,该技术能够为用户提供更加真实和结构合理的视觉体验,未来可能推动相关行业的创新发展。
📄 摘要(原文)
Recent advancements in image generation have achieved impressive results in producing high-quality images. However, existing image generation models still generally struggle with a spatial reasoning dilemma, lacking the ability to accurately capture fine-grained spatial relationships from the prompt and correctly generate scenes with structural integrity. To mitigate this dilemma, we propose RL-RIG, a Reinforcement Learning framework for Reflection-based Image Generation. Our architecture comprises four primary components: Diffuser, Checker, Actor, and Inverse Diffuser, following a Generate-Reflect-Edit paradigm to spark the Chain of Thought reasoning ability in image generation for addressing the dilemma. To equip the model with better intuition over generation trajectories, we further develop Reflection-GRPO to train the VLM Actor for edit prompts and the Image Editor for better image quality under a given prompt, respectively. Unlike traditional approaches that solely produce visually stunning yet structurally unreasonable content, our evaluation metrics prioritize spatial accuracy, utilizing Scene Graph IoU and employing a VLM-as-a-Judge strategy to assess the spatial consistency of generated images on LAION-SG dataset. Experimental results show that RL-RIG outperforms existing state-of-the-art open-source models by up to 11% in terms of controllable and precise spatial reasoning in image generation.