Multi-Modal Representation Learning via Semi-Supervised Rate Reduction for Generalized Category Discovery
作者: Wei He, Xianghan Meng, Zhiyuan Huang, Xianbiao Qi, Rong Xiao, Chun-Guang Li
分类: cs.CV
发布日期: 2026-02-23
备注: 15 pages, accepted by CVPR 2026
💡 一句话要点
提出SSR²-GCD框架,通过半监督速率降低实现多模态表征学习,用于广义类别发现。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 广义类别发现 多模态学习 半监督学习 速率降低 视觉语言模型 Prompt学习 开放集识别
📋 核心要点
- 广义类别发现(GCD)旨在识别已知和未知类别,仅为已知类别提供部分标签,这是一个具有挑战性的开放集识别问题。
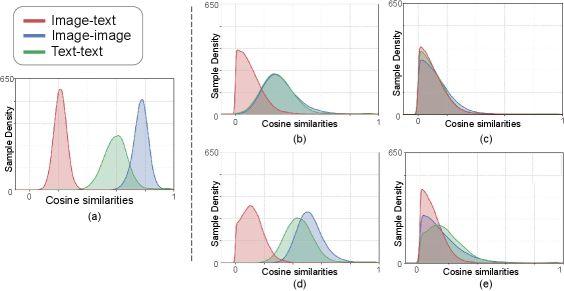
- SSR²-GCD框架通过半监督速率降低,学习具有所需结构属性的跨模态表征,强调模态内关系的对齐。
- 通过集成prompt候选,利用视觉语言模型提供的模态间对齐,促进知识迁移,并在多个数据集上取得了优越的性能。
📝 摘要(中文)
本文提出了一种新颖有效的多模态表征学习框架,用于广义类别发现(GCD),称为SSR²-GCD,该框架通过半监督速率降低来学习具有所需结构属性的跨模态表征,重点在于适当地对齐模态内关系。此外,为了促进知识迁移,我们利用视觉语言模型提供的模态间对齐,集成了prompt候选。在通用和细粒度基准数据集上进行了大量实验,证明了我们方法的优越性能。
🔬 方法详解
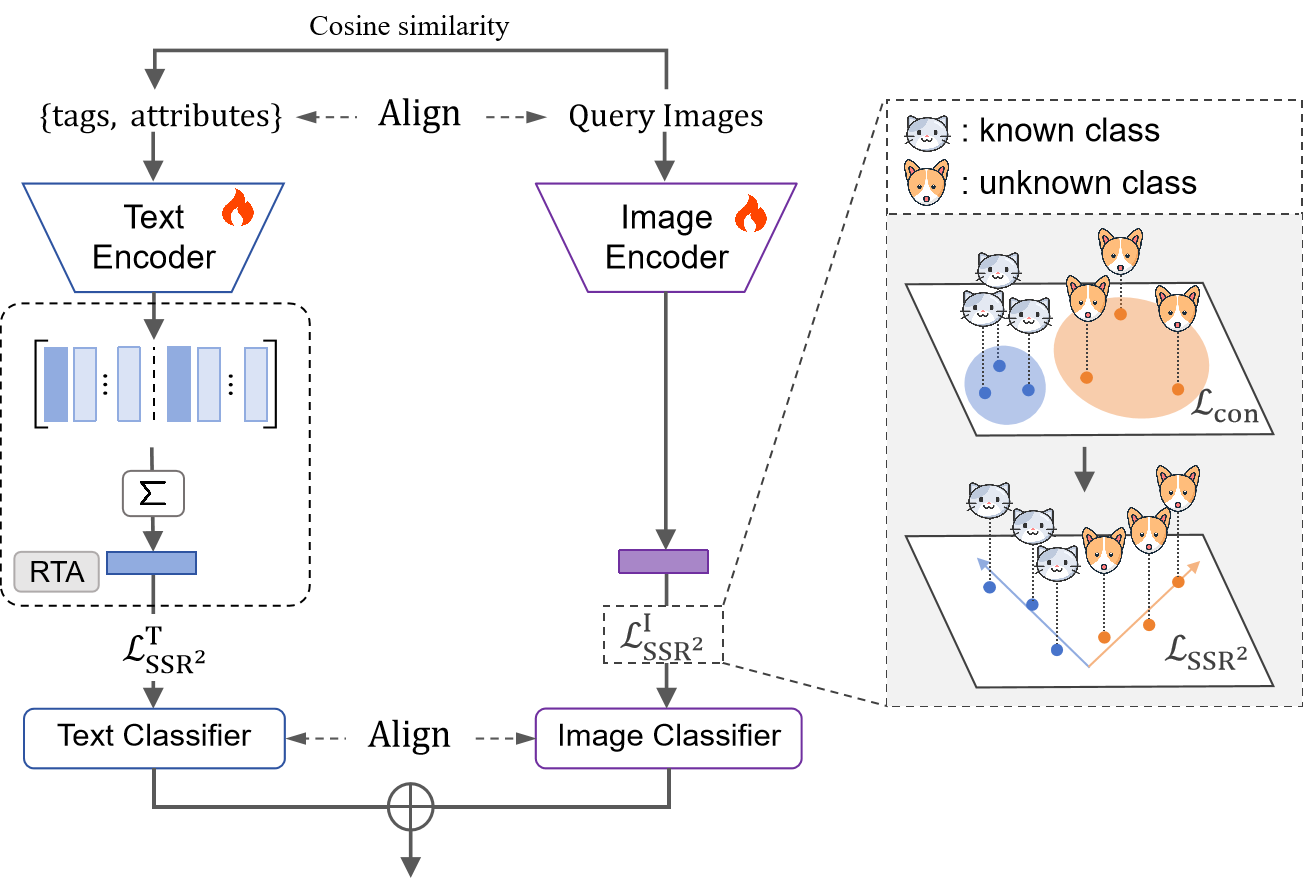
问题定义:广义类别发现(GCD)任务旨在同时识别已知和未知类别,但仅有部分已知类别的标签可用。现有的多模态GCD方法严重依赖于模态间的对齐,而忽略了模态内部的结构信息,导致表征分布不理想。
核心思路:本文的核心思路是通过半监督速率降低(Semi-Supervised Rate Reduction)来学习多模态表征,从而在模态内部实现更好的对齐,生成期望的表征分布结构。同时,利用视觉语言模型(VLM)的模态间对齐能力,通过prompt学习促进知识迁移。
技术框架:SSR²-GCD框架主要包含以下几个模块:1) 多模态特征提取模块,用于提取图像和文本等不同模态的特征;2) 半监督速率降低模块,通过最小化表征的互信息,学习紧凑且具有良好结构的表征;3) Prompt学习模块,利用VLM的模态间对齐能力,生成prompt候选,并选择合适的prompt来指导表征学习;4) 分类模块,基于学习到的表征进行已知和未知类别的分类。
关键创新:该论文的关键创新在于:1) 提出了半监督速率降低方法,用于在模态内部实现更好的表征对齐,从而生成期望的表征分布结构;2) 利用视觉语言模型(VLM)的模态间对齐能力,通过prompt学习促进知识迁移。与现有方法相比,该方法更加注重模态内部的结构信息,并能够有效地利用VLM的知识。
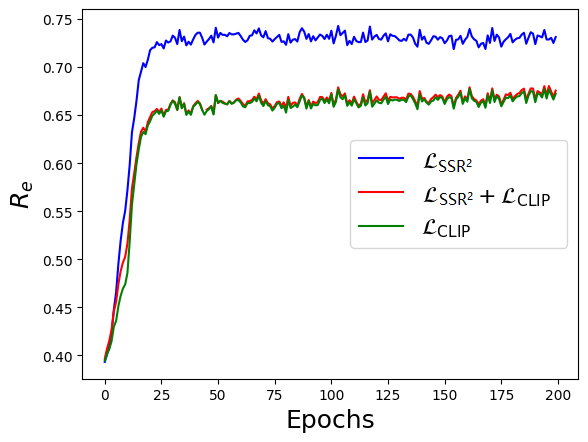
关键设计:在半监督速率降低模块中,使用了互信息最小化作为损失函数,以学习紧凑且具有良好结构的表征。Prompt学习模块中,通过计算prompt候选与图像/文本特征之间的相似度,选择合适的prompt来指导表征学习。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
该论文在通用和细粒度基准数据集上进行了大量实验,结果表明,所提出的SSR²-GCD框架在GCD任务上取得了优越的性能。具体而言,在多个数据集上,该方法相比于现有方法,在准确率和召回率等指标上均有显著提升,证明了其有效性和优越性。
🎯 应用场景
该研究成果可应用于图像分类、目标检测、自然语言处理等领域,尤其是在开放集识别和零样本学习等场景下具有重要价值。例如,可以用于识别监控视频中的异常行为、电商平台上的新型商品,以及社交媒体上的新兴话题等。该研究有助于提升人工智能系统的鲁棒性和泛化能力。
📄 摘要(原文)
Generalized Category Discovery (GCD) aims to identify both known and unknown categories, with only partial labels given for the known categories, posing a challenging open-set recognition problem. State-of-the-art approaches for GCD task are usually built on multi-modality representation learning, which is heavily dependent upon inter-modality alignment. However, few of them cast a proper intra-modality alignment to generate a desired underlying structure of representation distributions. In this paper, we propose a novel and effective multi-modal representation learning framework for GCD via Semi-Supervised Rate Reduction, called SSR$^2$-GCD, to learn cross-modality representations with desired structural properties based on emphasizing to properly align intra-modality relationships. Moreover, to boost knowledge transfer, we integrate prompt candidates by leveraging the inter-modal alignment offered by Vision Language Models. We conduct extensive experiments on generic and fine-grained benchmark datasets demonstrating superior performance of our approach.