ApET: Approximation-Error Guided Token Compression for Efficient VLMs
作者: Qiankun Ma, Ziyao Zhang, Haofei Wang, Jie Chen, Zhen Song, Hairong Zheng
分类: cs.CV
发布日期: 2026-02-23
备注: CVPR2026
🔗 代码/项目: GITHUB
💡 一句话要点
ApET:通过近似误差引导的token压缩,提升视觉语言模型效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 token压缩 近似误差 高效推理 FlashAttention 图像理解 视频理解
📋 核心要点
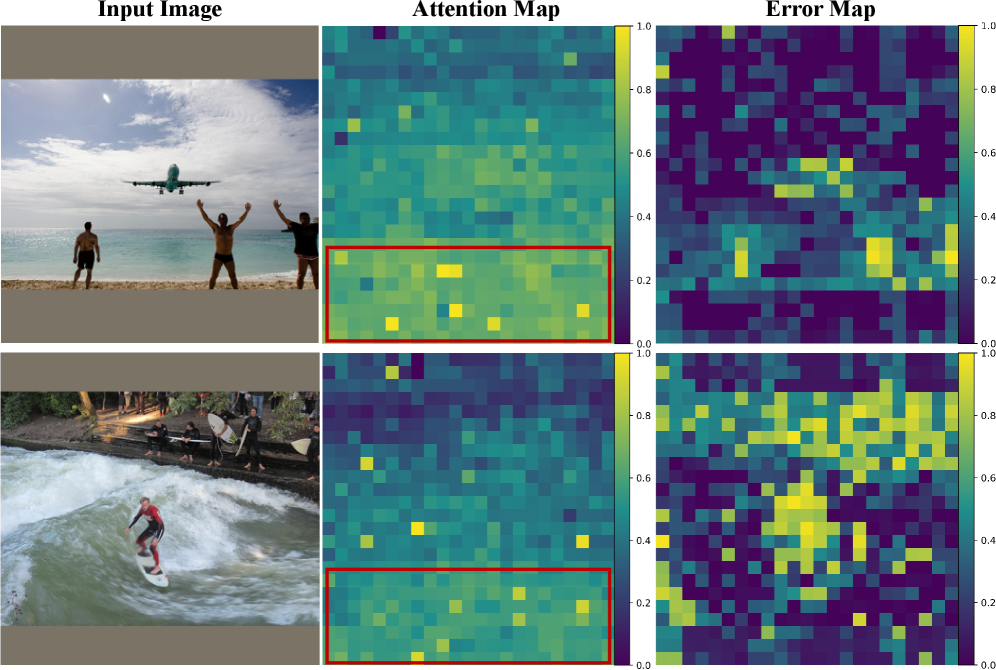
- 现有VLM依赖注意力机制进行token压缩,存在位置偏差,且与FlashAttention等高效内核不兼容,限制了实际部署。
- ApET框架通过线性近似重建视觉token,并利用近似误差指导token压缩,无需注意力机制,保留关键信息。
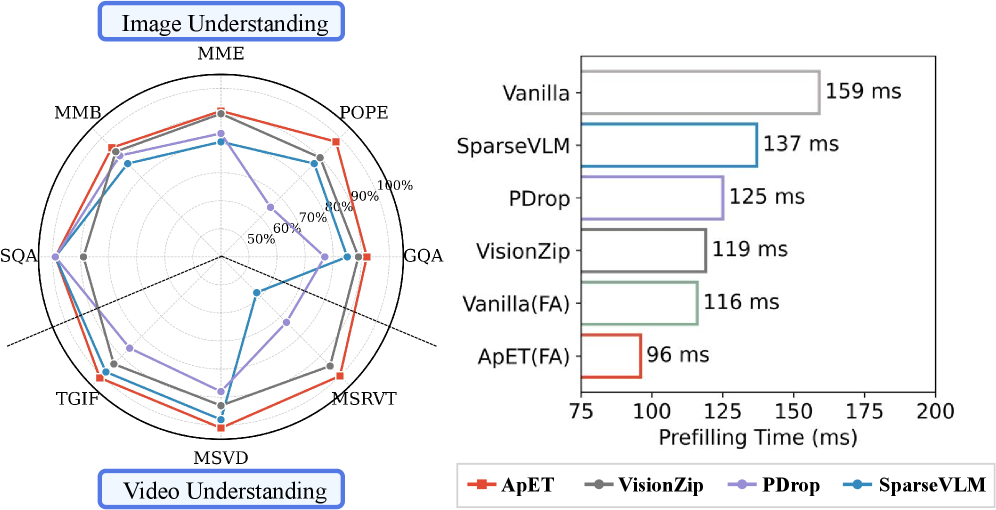
- 实验表明,ApET在大幅压缩token数量的同时,保持甚至提升了VLM在图像和视频理解任务上的性能。
📝 摘要(中文)
现有的视觉语言模型(VLMs)展示了卓越的多模态理解能力,但冗余的视觉token导致了过高的计算开销并降低了推理效率。以往的研究通常依赖于[CLS]注意力或文本-视觉交叉注意力来识别和丢弃冗余的视觉token。尽管取得了一些成果,但这些解决方案容易引入位置偏差,更重要的是,它们与诸如FlashAttention等高效注意力内核不兼容,限制了它们在VLM加速中的实际部署。本文从信息论的角度重新审视视觉token压缩,旨在最大限度地保留视觉信息而不涉及任何注意力机制。我们提出了ApET,一个近似误差引导的token压缩框架。ApET首先通过线性近似用一小组基token重建原始视觉token,然后利用近似误差来识别和丢弃信息量最少的token。在多个VLM和基准测试上的大量实验表明,ApET在图像理解任务上保留了95.2%的原始性能,甚至在视频理解任务上达到了100.4%,同时分别压缩了88.9%和87.5%的token预算。由于其无注意力的设计,ApET可以无缝地与FlashAttention集成,从而进一步加速推理并使VLM部署更具实用性。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)中,视觉token数量庞大,导致计算开销高昂,推理效率低下。以往方法依赖注意力机制(如[CLS]注意力或交叉注意力)进行token选择,但这些方法存在位置偏差,且与FlashAttention等高效注意力内核不兼容,难以在实际部署中加速VLM推理。
核心思路:ApET的核心思路是从信息论角度出发,通过线性近似重建视觉token,并利用重建误差(即近似误差)来衡量token的重要性。近似误差越大,表示该token包含的信息越少,越应该被丢弃。这种方法避免了对注意力机制的依赖,从而消除了位置偏差,并能与FlashAttention等高效内核兼容。
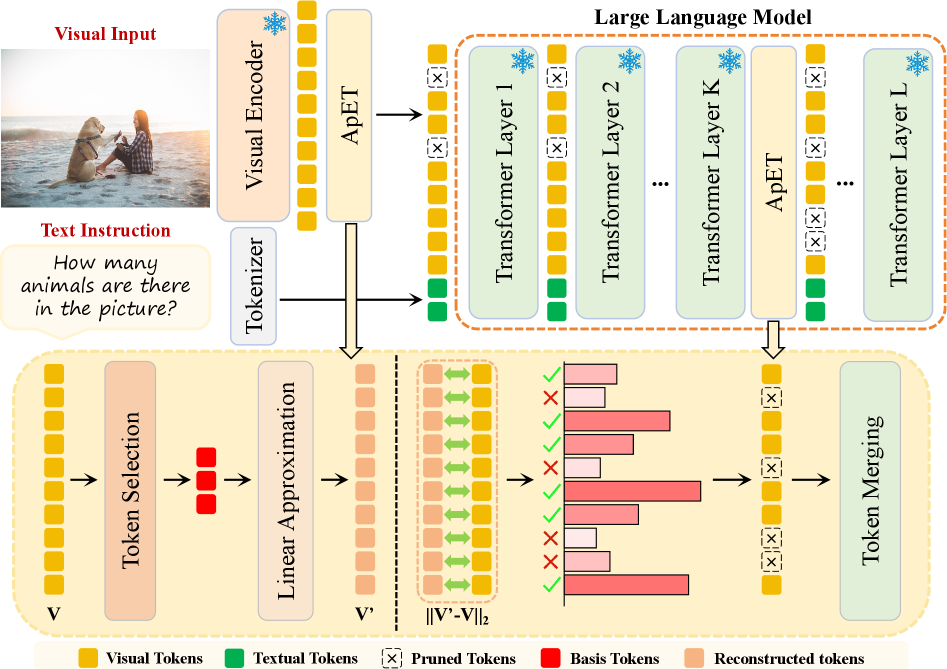
技术框架:ApET框架主要包含两个阶段:1) Token重建阶段:使用一组基token通过线性组合来近似原始视觉token。具体来说,对输入视觉token进行线性变换,得到一组基token,然后通过线性回归等方法,学习每个原始token由哪些基token以何种权重组合而成。2) Token压缩阶段:计算每个原始token的重建误差,并根据误差大小对token进行排序。选择误差最小的token保留,其余token丢弃。
关键创新:ApET最重要的创新在于其无注意力机制的token压缩方法。与以往依赖注意力机制的方法不同,ApET直接基于信息论的近似误差来指导token选择,避免了位置偏差,并且能够与FlashAttention等高效注意力内核无缝集成,从而实现更快的推理速度。
关键设计:ApET的关键设计包括:1) 基token的数量:基token的数量决定了重建的精度和计算复杂度。需要根据实际情况进行调整。2) 重建误差的计算方法:可以使用均方误差(MSE)等指标来衡量重建误差。3) Token丢弃的比例:需要根据实际情况进行调整,以在性能和效率之间取得平衡。4) 线性近似方法:可以使用线性回归、主成分分析(PCA)等方法进行线性近似。
🖼️ 关键图片
📊 实验亮点
ApET在多个VLM和基准测试上表现出色。在图像理解任务上,ApET保留了95.2%的原始性能,同时压缩了88.9%的token。更令人惊讶的是,在视频理解任务上,ApET甚至达到了100.4%的原始性能,同时压缩了87.5%的token。这些结果表明,ApET能够在大幅降低计算开销的同时,保持甚至提升VLM的性能。
🎯 应用场景
ApET可应用于各种需要高效视觉语言理解的场景,例如移动设备上的图像/视频搜索、智能助手、自动驾驶等。通过降低计算开销和提高推理速度,ApET使得VLM能够在资源受限的环境中部署,并为用户提供更快速、更流畅的体验。未来,ApET可以进一步扩展到其他模态,例如音频和文本,以实现更高效的多模态理解。
📄 摘要(原文)
Recent Vision-Language Models (VLMs) have demonstrated remarkable multimodal understanding capabilities, yet the redundant visual tokens incur prohibitive computational overhead and degrade inference efficiency. Prior studies typically relies on [CLS] attention or text-vision cross-attention to identify and discard redundant visual tokens. Despite promising results, such solutions are prone to introduce positional bias and, more critically, are incompatible with efficient attention kernels such as FlashAttention, limiting their practical deployment for VLM acceleration. In this paper, we step away from attention dependencies and revisit visual token compression from an information-theoretic perspective, aiming to maximally preserve visual information without any attention involvement. We present ApET, an Approximation-Error guided Token compression framework. ApET first reconstructs the original visual tokens with a small set of basis tokens via linear approximation, then leverages the approximation error to identify and drop the least informative tokens. Extensive experiments across multiple VLMs and benchmarks demonstrate that ApET retains 95.2% of the original performance on image-understanding tasks and even attains 100.4% on video-understanding tasks, while compressing the token budgets by 88.9% and 87.5%, respectively. Thanks to its attention-free design, ApET seamlessly integrates with FlashAttention, enabling further inference acceleration and making VLM deployment more practical. Code is available at https://github.com/MaQianKun0/ApET.