DerMAE: Improving skin lesion classification through conditioned latent diffusion and MAE distillation
作者: Francisco Filho, Kelvin Cunha, Fábio Papais, Emanoel dos Santos, Rodrigo Mota, Thales Bezerra, Erico Medeiros, Paulo Borba, Tsang Ing Ren
分类: cs.CV
发布日期: 2026-02-23
备注: 4 pages, 2 figures, 1 table, isbi2026
💡 一句话要点
DerMAE:利用条件潜在扩散和MAE蒸馏提升皮肤病灶分类性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 皮肤病灶分类 类别不平衡 条件扩散模型 MAE预训练 知识蒸馏 ViT模型 医学图像分析
📋 核心要点
- 皮肤病灶分类任务中,类别不平衡问题严重影响深度学习模型的性能,尤其是在恶性病灶识别方面。
- 该论文提出了一种基于类别条件扩散模型生成合成数据,并结合MAE预训练和知识蒸馏的方法,以提升分类性能。
- 实验结果表明,该方法在提高分类性能的同时,实现了高效的设备端推理,适用于实际临床应用。
📝 摘要(中文)
皮肤病灶分类数据集通常面临严重的类别不平衡问题,其中恶性病例的代表性明显不足,导致深度学习训练过程中产生有偏的决策边界。为了解决这一挑战,我们使用类别条件扩散模型生成合成的皮肤图像,然后进行自监督MAE预训练,使大型ViT模型能够学习鲁棒的、领域相关的特征。为了支持在实际临床环境中的部署(需要轻量级模型),我们应用知识蒸馏将这些表示转移到更小的ViT学生模型,使其适合移动设备。结果表明,在合成数据上进行MAE预训练,结合知识蒸馏,可以提高分类性能,同时实现高效的设备端推理,从而满足实际临床应用的需求。
🔬 方法详解
问题定义:皮肤病灶分类任务中,数据集的类别不平衡问题,特别是恶性病灶样本数量不足,导致训练出的深度学习模型在恶性病灶的识别上表现不佳。现有方法难以有效解决数据不平衡问题,并且大型模型难以部署到移动设备等资源受限的临床环境中。
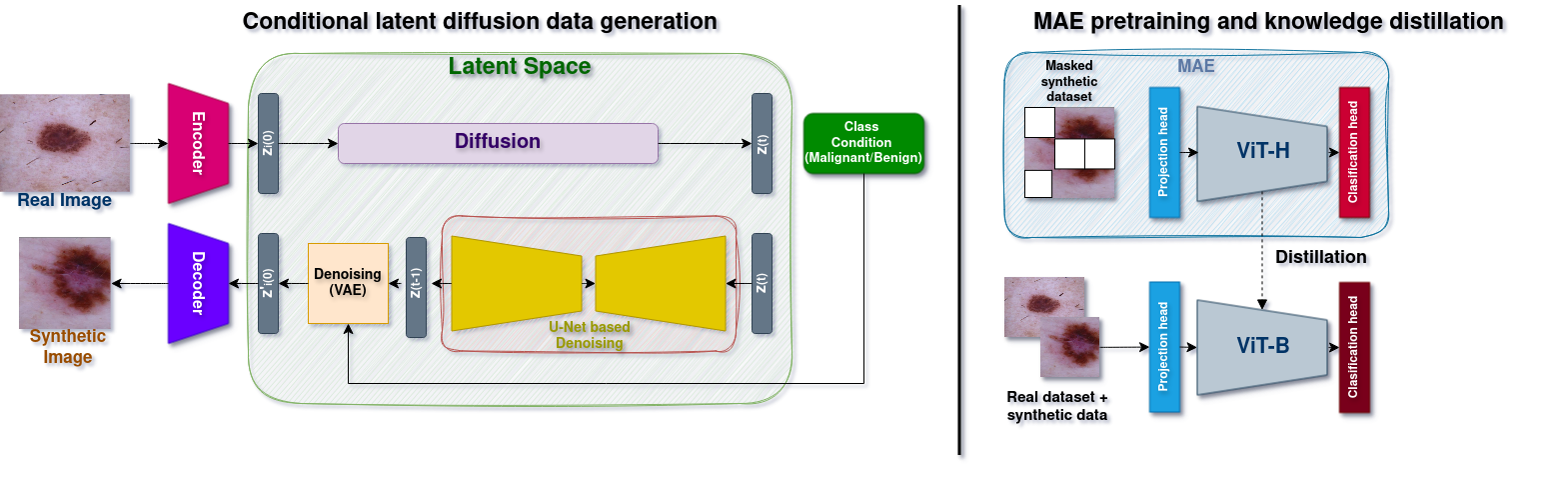
核心思路:该论文的核心思路是利用类别条件扩散模型生成高质量的合成皮肤病灶图像,从而缓解数据不平衡问题。然后,通过自监督MAE预训练,使大型ViT模型学习到鲁棒的、领域相关的特征。最后,利用知识蒸馏技术将这些特征迁移到小型ViT模型,以实现高效的设备端推理。这样设计的目的是为了在解决数据不平衡问题的同时,保证模型能够在实际临床环境中部署和应用。
技术框架:整体框架包含三个主要阶段:1) 数据增强阶段:使用类别条件扩散模型生成合成的皮肤病灶图像,以平衡数据集。2) 预训练阶段:使用Masked Autoencoder (MAE) 在真实和合成数据上对大型ViT模型进行自监督预训练,学习领域相关的特征。3) 知识蒸馏阶段:将预训练的大型ViT模型作为教师模型,训练一个小型ViT学生模型,并将教师模型的知识迁移到学生模型,以实现高效的设备端推理。
关键创新:该论文的关键创新在于:1) 将类别条件扩散模型应用于皮肤病灶图像生成,有效缓解了数据不平衡问题。2) 结合MAE预训练和知识蒸馏,实现了在提高分类性能的同时,保证模型能够在资源受限的设备上高效运行。3) 提出了一种将大型模型学习到的鲁棒特征迁移到小型模型的方法,使其适用于实际临床应用。
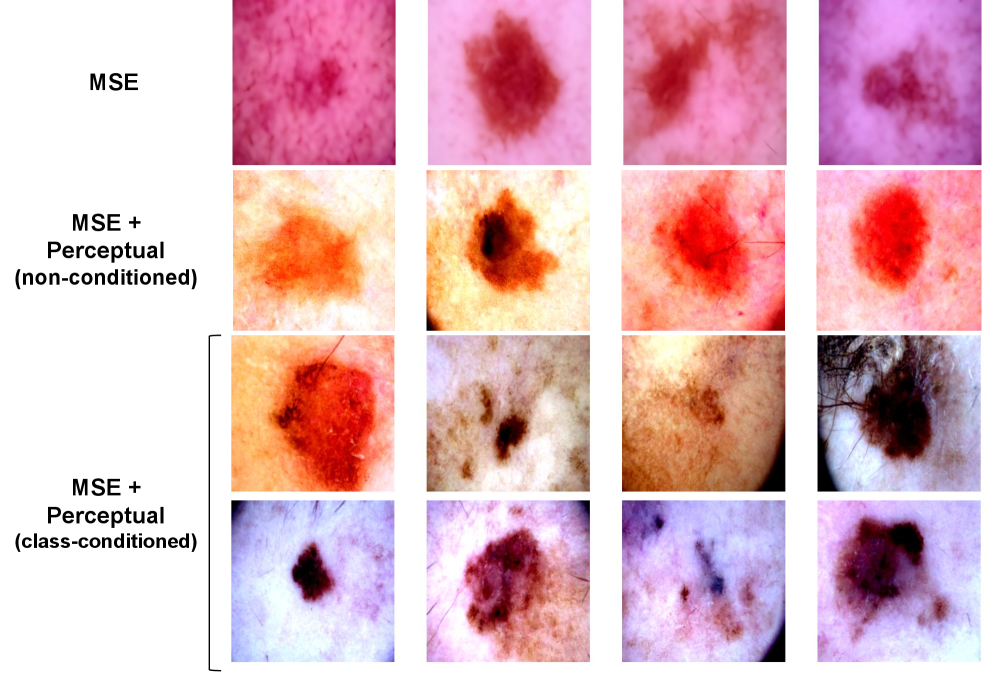
关键设计:在数据增强阶段,使用DDPM(Denoising Diffusion Probabilistic Models)作为扩散模型,并使用类别信息作为条件,控制生成图像的类别。在MAE预训练阶段,采用高比例的masking ratio(例如75%),迫使模型学习从可见部分重建被mask的部分,从而学习到更鲁棒的特征。在知识蒸馏阶段,使用KL散度损失函数来衡量教师模型和学生模型输出概率分布的差异,并使用交叉熵损失函数来衡量学生模型预测结果与真实标签的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在皮肤病灶分类任务中取得了显著的性能提升。与传统方法相比,该方法在多个数据集上均获得了更高的分类准确率和F1-score。特别是在恶性病灶的识别方面,该方法的提升尤为明显,有效解决了类别不平衡问题带来的挑战。同时,知识蒸馏使得模型能够在移动设备上高效运行,满足了实际临床应用的需求。
🎯 应用场景
该研究成果可应用于皮肤科疾病的辅助诊断,尤其是在资源有限的基层医疗机构。通过部署在移动设备上的轻量级模型,医生可以快速准确地识别皮肤病灶,提高诊断效率和准确性,从而改善患者的治疗效果。此外,该方法还可以推广到其他医学图像分类任务中,具有广阔的应用前景。
📄 摘要(原文)
Skin lesion classification datasets often suffer from severe class imbalance, with malignant cases significantly underrepresented, leading to biased decision boundaries during deep learning training. We address this challenge using class-conditioned diffusion models to generate synthetic dermatological images, followed by self-supervised MAE pretraining to enable huge ViT models to learn robust, domain-relevant features. To support deployment in practical clinical settings, where lightweight models are required, we apply knowledge distillation to transfer these representations to a smaller ViT student suitable for mobile devices. Our results show that MAE pretraining on synthetic data, combined with distillation, improves classification performance while enabling efficient on-device inference for practical clinical use.