TextShield-R1: Reinforced Reasoning for Tampered Text Detection
作者: Chenfan Qu, Yiwu Zhong, Jian Liu, Xuekang Zhu, Bohan Yu, Lianwen Jin
分类: cs.CV
发布日期: 2026-02-23
备注: AAAI 2026
💡 一句话要点
提出TextShield-R1,基于强化学习的多模态大语言模型用于篡改文本检测与推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 篡改文本检测 多模态大语言模型 强化学习 取证分析 OCR校正
📋 核心要点
- 现有方法难以识别图像篡改中的微观伪影,篡改文本区域定位精度低,且依赖昂贵的标注数据。
- TextShield-R1利用强化学习训练MLLM,结合取证持续预训练、组相对策略优化和OCR校正,提升检测和推理能力。
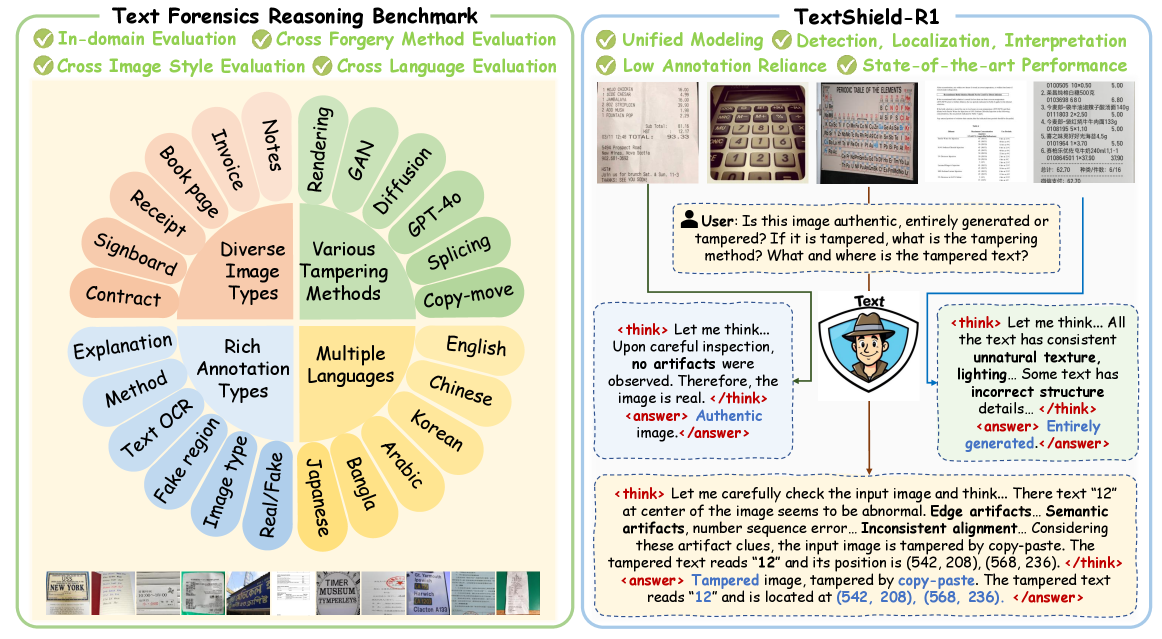
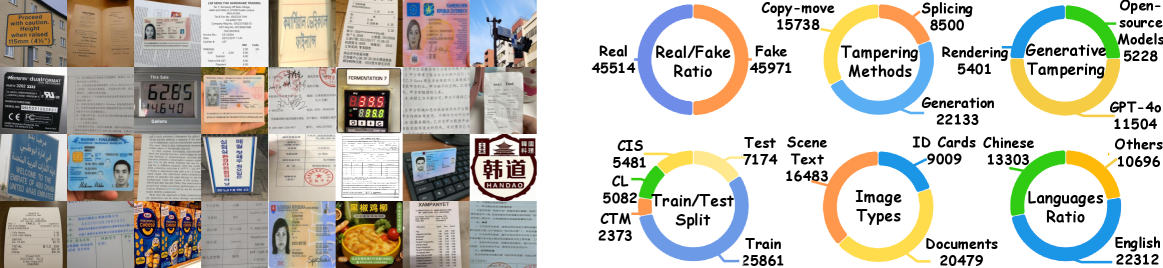
- 提出的TFR基准包含4.5万张图像,覆盖多种语言和篡改技术,实验表明TextShield-R1显著提升了篡改文本检测性能。
📝 摘要(中文)
图像篡改日益普遍,对安全构成严重威胁,亟需可靠的检测方法。多模态大语言模型(MLLM)在分析篡改图像和生成解释方面表现出强大的潜力。然而,它们在识别微观伪影方面仍然存在困难,在定位篡改文本区域方面准确率较低,并且严重依赖昂贵的伪造解释标注。为此,我们推出了TextShield-R1,这是第一个基于强化学习的MLLM解决方案,用于篡改文本检测和推理。具体来说,我们的方法引入了取证持续预训练,这是一种由易到难的课程,通过利用来自自然图像取证和OCR任务的大规模廉价数据,使MLLM为篡改文本检测做好充分准备。在微调期间,我们使用新颖的奖励函数执行组相对策略优化,以减少对标注的依赖并提高推理能力。在推理时,我们通过OCR校正来提高定位精度,这是一种利用MLLM强大的文本识别能力来改进其预测的方法。此外,为了支持严格的评估,我们引入了文本取证推理(TFR)基准,该基准包含超过4.5万张跨16种语言、10种篡改技术和不同领域的真实和篡改图像。其中包含丰富的推理式标注,可以进行全面评估。我们的TFR基准同时解决了现有基准的七个主要局限性,并能够在跨风格、跨方法和跨语言条件下进行稳健的评估。大量的实验表明,TextShield-R1显著提高了可解释的篡改文本检测的最新水平。
🔬 方法详解
问题定义:论文旨在解决篡改图像中篡改文本的检测与定位问题。现有方法,特别是基于多模态大语言模型的方法,在处理微小篡改痕迹、精确定位篡改区域以及减少对大量标注数据的依赖方面存在不足。这些痛点限制了篡改文本检测技术在实际安全场景中的应用。
核心思路:TextShield-R1的核心思路是利用强化学习来训练多模态大语言模型,使其能够更好地理解和推理篡改文本。通过取证持续预训练,模型能够从大规模的自然图像取证和OCR数据中学习到通用的图像和文本特征。然后,通过组相对策略优化,模型可以在较少的标注数据下学习到更有效的篡改检测策略。最后,OCR校正利用模型强大的文本识别能力来提高篡改区域的定位精度。
技术框架:TextShield-R1的整体框架包含三个主要阶段:1) 取证持续预训练:使用大规模的自然图像取证和OCR数据预训练MLLM,使其具备初步的篡改检测能力。2) 组相对策略优化:使用强化学习微调MLLM,通过奖励函数引导模型学习更有效的篡改检测策略,并减少对标注数据的依赖。3) OCR校正:在推理阶段,利用MLLM的文本识别能力对检测到的篡改区域进行校正,提高定位精度。
关键创新:TextShield-R1的关键创新在于将强化学习引入到多模态大语言模型的篡改文本检测任务中。通过设计合适的奖励函数,模型可以在较少的标注数据下学习到更有效的篡改检测策略。此外,OCR校正方法也有效地提高了篡改区域的定位精度。提出的TFR基准也为该领域的研究提供了更全面和严格的评估平台。
关键设计:在取证持续预训练阶段,采用由易到难的课程学习策略,逐步提高训练难度。在组相对策略优化阶段,设计了新颖的奖励函数,鼓励模型生成更准确的篡改检测结果。OCR校正阶段,利用MLLM的文本识别置信度来调整篡改区域的边界框。
🖼️ 关键图片

📊 实验亮点
TextShield-R1在提出的TFR基准上取得了显著的性能提升,超越了现有的最先进方法。实验结果表明,该方法在跨风格、跨方法和跨语言的篡改文本检测任务中均表现出强大的鲁棒性和泛化能力。具体性能数据在论文中详细展示,证明了TextShield-R1的有效性。
🎯 应用场景
TextShield-R1可应用于网络安全、新闻媒体、知识产权保护等领域,用于检测和识别篡改图像中的文本信息,防止虚假信息的传播和恶意攻击。该技术有助于维护网络空间的真实性和安全性,具有重要的社会价值和商业潜力。未来可扩展到视频篡改检测等更广泛的应用场景。
📄 摘要(原文)
The growing prevalence of tampered images poses serious security threats, highlighting the urgent need for reliable detection methods. Multimodal large language models (MLLMs) demonstrate strong potential in analyzing tampered images and generating interpretations. However, they still struggle with identifying micro-level artifacts, exhibit low accuracy in localizing tampered text regions, and heavily rely on expensive annotations for forgery interpretation. To this end, we introduce TextShield-R1, the first reinforcement learning based MLLM solution for tampered text detection and reasoning. Specifically, our approach introduces Forensic Continual Pre-training, an easy-to-hard curriculum that well prepares the MLLM for tampered text detection by harnessing the large-scale cheap data from natural image forensic and OCR tasks. During fine-tuning, we perform Group Relative Policy Optimization with novel reward functions to reduce annotation dependency and improve reasoning capabilities. At inference time, we enhance localization accuracy via OCR Rectification, a method that leverages the MLLM's strong text recognition abilities to refine its predictions. Furthermore, to support rigorous evaluation, we introduce the Text Forensics Reasoning (TFR) benchmark, comprising over 45k real and tampered images across 16 languages, 10 tampering techniques, and diverse domains. Rich reasoning-style annotations are included, allowing for comprehensive assessment. Our TFR benchmark simultaneously addresses seven major limitations of existing benchmarks and enables robust evaluation under cross-style, cross-method, and cross-language conditions. Extensive experiments demonstrate that TextShield-R1 significantly advances the state of the art in interpretable tampered text detection.