TraceVision: Trajectory-Aware Vision-Language Model for Human-Like Spatial Understanding
作者: Fan Yang, Shurong Zheng, Hongyin Zhao, Yufei Zhan, Xin Li, Yousong Zhu, Chaoyang Zhao Ming Tang, Jinqiao Wang
分类: cs.CV
发布日期: 2026-02-23
💡 一句话要点
TraceVision:提出轨迹感知的视觉-语言模型,实现类人空间理解
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉-语言模型 轨迹感知 空间理解 人机交互 视觉注意力 图像描述生成 轨迹预测
📋 核心要点
- 现有视觉-语言模型侧重于全局图像理解,难以模拟人类视觉注意力轨迹,以及解释描述与特定区域的关联。
- TraceVision通过轨迹感知视觉感知(TVP)模块,双向融合视觉特征和轨迹信息,并设计几何简化方法提取轨迹关键点。
- TraceVision在轨迹引导的图像描述生成、轨迹预测等任务上取得了SOTA性能,并构建了RILN数据集以增强逻辑推理能力。
📝 摘要(中文)
本文提出TraceVision,一个统一的视觉-语言模型,它在端到端框架中集成了轨迹感知的空间理解能力。TraceVision采用轨迹感知视觉感知(TVP)模块,用于视觉特征和轨迹信息的双向融合。设计了几何简化方法,从原始轨迹中提取语义关键点,并提出了一个三阶段训练流程,其中轨迹引导描述生成和区域定位。TraceVision被扩展到轨迹引导的分割和视频场景理解,从而实现跨帧跟踪和时间注意力分析。构建了基于推理的交互式局部叙事(RILN)数据集,以增强逻辑推理和可解释性。在轨迹引导的图像描述生成、文本引导的轨迹预测、理解和分割等任务上的大量实验表明,TraceVision实现了最先进的性能,为直观的空间交互和可解释的视觉理解奠定了基础。
🔬 方法详解
问题定义:现有的大型视觉-语言模型(LVLMs)在图像理解和自然语言生成方面表现出色,但它们主要关注全局图像理解,缺乏对人类视觉注意轨迹的模拟能力,以及对描述和特定区域之间关联的解释能力。这限制了模型在需要精细空间推理和交互的场景中的应用。
核心思路:TraceVision的核心思路是将人类的视觉轨迹信息融入到视觉-语言模型中,通过轨迹引导模型关注图像中的关键区域,从而提高模型对图像内容的理解和推理能力。通过显式地建模视觉轨迹,模型可以更好地理解图像中不同区域之间的关系,并生成更准确、更具解释性的描述。
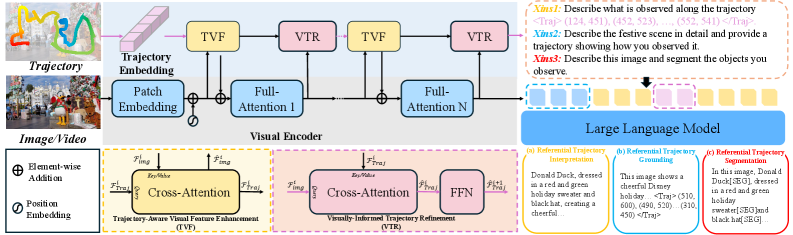
技术框架:TraceVision的整体框架包含以下几个主要模块:1) 轨迹感知视觉感知(TVP)模块:用于融合视觉特征和轨迹信息。2) 几何简化模块:从原始轨迹中提取语义关键点。3) 三阶段训练流程:包括轨迹引导的描述生成、区域定位和微调。此外,TraceVision还扩展到轨迹引导的分割和视频场景理解,以实现跨帧跟踪和时间注意力分析。
关键创新:TraceVision的关键创新在于:1) 提出了轨迹感知视觉感知(TVP)模块,实现了视觉特征和轨迹信息的双向融合。2) 设计了几何简化方法,从原始轨迹中提取语义关键点,降低了计算复杂度。3) 提出了一个三阶段训练流程,有效地利用轨迹信息来引导描述生成和区域定位。
关键设计:TVP模块的具体实现细节(例如,使用的注意力机制类型、特征融合方式等)未知。几何简化方法的具体算法细节未知。三阶段训练流程中,各个阶段使用的损失函数和训练策略未知。RILN数据集的构建细节(例如,数据规模、标注方式等)未知。
🖼️ 关键图片


📊 实验亮点
TraceVision在多个任务上取得了SOTA性能。在轨迹引导的图像描述生成任务上,TraceVision生成的描述更加准确和具有解释性。在文本引导的轨迹预测任务上,TraceVision能够更准确地预测人类的视觉轨迹。此外,TraceVision在轨迹引导的分割和视频场景理解任务上也表现出色,证明了其在空间理解方面的强大能力。具体性能数据和提升幅度在论文中给出。
🎯 应用场景
TraceVision具有广泛的应用前景,例如人机交互、机器人导航、智能监控、自动驾驶等领域。它可以帮助机器人更好地理解人类的意图,并根据人类的指示进行操作。在智能监控领域,它可以用于分析人员的行动轨迹,从而检测异常行为。在自动驾驶领域,它可以用于理解驾驶员的注意力焦点,从而提高驾驶安全性。
📄 摘要(原文)
Recent Large Vision-Language Models (LVLMs) demonstrate remarkable capabilities in image understanding and natural language generation. However, current approaches focus predominantly on global image understanding, struggling to simulate human visual attention trajectories and explain associations between descriptions and specific regions. We propose TraceVision, a unified vision-language model integrating trajectory-aware spatial understanding in an end-to-end framework. TraceVision employs a Trajectory-aware Visual Perception (TVP) module for bidirectional fusion of visual features and trajectory information. We design geometric simplification to extract semantic keypoints from raw trajectories and propose a three-stage training pipeline where trajectories guide description generation and region localization. We extend TraceVision to trajectory-guided segmentation and video scene understanding, enabling cross-frame tracking and temporal attention analysis. We construct the Reasoning-based Interactive Localized Narratives (RILN) dataset to enhance logical reasoning and interpretability. Extensive experiments on trajectory-guided captioning, text-guided trajectory prediction, understanding, and segmentation demonstrate that TraceVision achieves state-of-the-art performance, establishing a foundation for intuitive spatial interaction and interpretable visual understanding.