Multimodal Dataset Distillation Made Simple by Prototype-Guided Data Synthesis
作者: Junhyeok Choi, Sangwoo Mo, Minwoo Chae
分类: cs.CV
发布日期: 2026-02-23
💡 一句话要点
提出原型引导数据合成的多模态数据集蒸馏方法,提升跨架构泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数据集蒸馏 跨架构泛化 原型学习 CLIP unCLIP 免学习
📋 核心要点
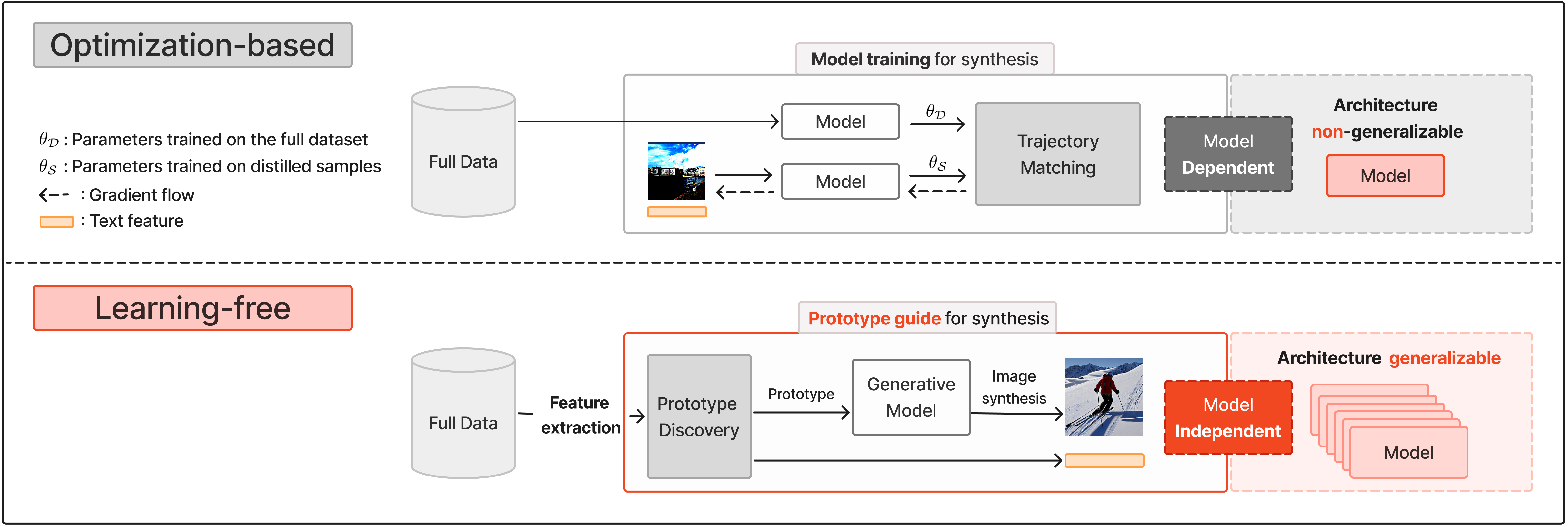
- 现有方法依赖大规模多模态数据集,训练成本高,且数据集蒸馏方法架构依赖性强,泛化能力受限。
- 利用CLIP提取对齐的图像-文本嵌入,获取原型,并使用unCLIP解码器合成图像,实现免学习的数据集蒸馏。
- 实验表明,该方法优于基于优化的数据集蒸馏和子集选择方法,实现了最先进的跨架构泛化。
📝 摘要(中文)
多模态学习在视觉-语言任务中取得了显著进展,但严重依赖大规模图像-文本数据集,导致训练成本高昂且效率低下。现有的数据集过滤和修剪方法试图缓解这个问题,但仍需要相对较大的子集来维持性能,并且在非常小的子集下失效。数据集蒸馏提供了一种有前景的替代方案,但现有的多模态数据集蒸馏方法需要全数据集训练以及图像像素和文本特征的联合优化,这使得它们依赖于特定架构并限制了跨架构的泛化能力。为了克服这些问题,我们提出了一种免学习的数据集蒸馏框架,该框架无需大规模训练和优化,同时增强了跨架构的泛化能力。我们的方法使用CLIP提取对齐的图像-文本嵌入,获取原型,并使用unCLIP解码器合成图像,从而实现高效且可扩展的多模态数据集蒸馏。大量实验表明,我们的方法始终优于基于优化的数据集蒸馏和子集选择方法,实现了最先进的跨架构泛化。
🔬 方法详解
问题定义:论文旨在解决多模态数据集蒸馏中存在的架构依赖性和泛化能力差的问题。现有方法通常需要全数据集训练和图像像素与文本特征的联合优化,这使得它们难以应用于不同的模型架构,并且在小数据集场景下性能下降。
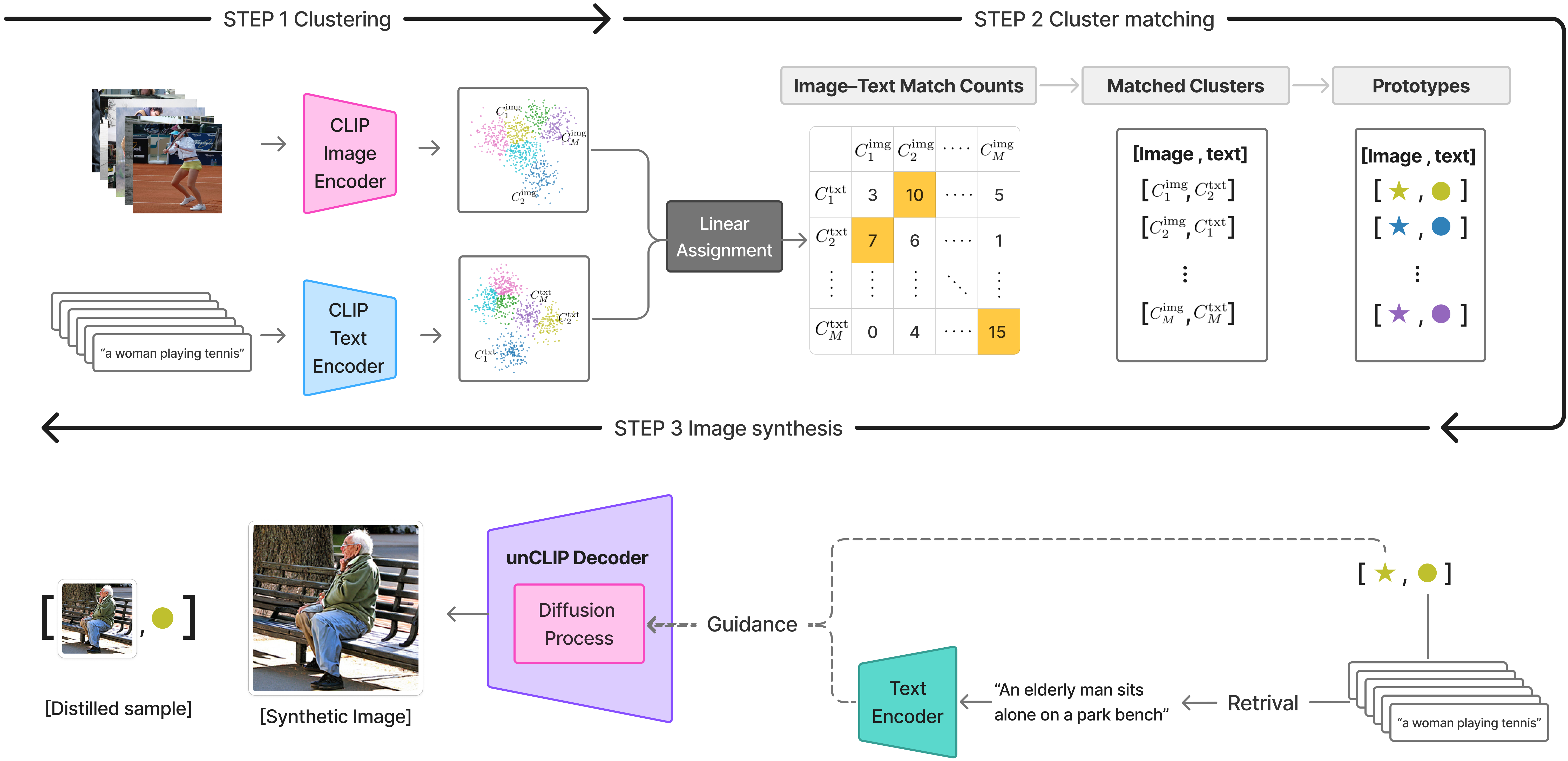
核心思路:论文的核心思路是利用预训练的CLIP模型提取图像和文本的对齐嵌入,然后通过聚类等方法获得具有代表性的原型。这些原型可以看作是原始数据集的压缩表示。接着,使用unCLIP模型将这些原型解码成合成图像,从而生成一个蒸馏数据集。由于该过程不需要针对特定架构进行训练,因此可以提高跨架构的泛化能力。
技术框架:该方法主要包含三个阶段:1) 使用CLIP模型提取原始图像-文本数据的对齐嵌入;2) 基于提取的嵌入,通过聚类算法(如K-means)获得图像-文本原型;3) 使用unCLIP模型将原型解码为合成图像,构建蒸馏数据集。整个流程无需训练,属于免学习方法。
关键创新:该方法最重要的创新点在于提出了一个免学习的多模态数据集蒸馏框架,避免了传统方法中耗时的训练和优化过程。通过利用预训练的CLIP和unCLIP模型,实现了高效且具有良好泛化能力的蒸馏数据集生成。这种方法摆脱了对特定架构的依赖,使得蒸馏数据集可以应用于不同的模型。
关键设计:在嵌入提取阶段,使用CLIP模型获得图像和文本的对齐嵌入。在原型选择阶段,可以使用K-means等聚类算法,选择每个簇的中心作为原型。在图像合成阶段,使用unCLIP模型将原型解码为图像。具体的参数设置包括CLIP和unCLIP模型的选择、聚类算法的参数(如簇的数量)等。损失函数方面,由于是免学习方法,因此不需要设计损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在跨架构泛化方面优于现有的数据集蒸馏和子集选择方法。具体而言,该方法在多个视觉-语言任务上取得了state-of-the-art的性能,并且在小数据集场景下表现出更强的鲁棒性。相较于基于优化的数据集蒸馏方法,该方法无需训练,大大降低了计算成本。
🎯 应用场景
该研究成果可应用于各种需要使用大规模多模态数据的场景,例如图像描述、视觉问答、跨模态检索等。通过数据集蒸馏,可以显著降低训练成本,提高训练效率,并增强模型的泛化能力。该方法尤其适用于资源受限的场景,例如移动设备或边缘计算环境。
📄 摘要(原文)
Recent advances in multimodal learning have achieved remarkable success across diverse vision-language tasks. However, such progress heavily relies on large-scale image-text datasets, making training costly and inefficient. Prior efforts in dataset filtering and pruning attempt to mitigate this issue, but still require relatively large subsets to maintain performance and fail under very small subsets. Dataset distillation offers a promising alternative, yet existing multimodal dataset distillation methods require full-dataset training and joint optimization of image pixels and text features, making them architecture-dependent and limiting cross-architecture generalization. To overcome this, we propose a learning-free dataset distillation framework that eliminates the need for large-scale training and optimization while enhancing generalization across architectures. Our method uses CLIP to extract aligned image-text embeddings, obtains prototypes, and employs an unCLIP decoder to synthesize images, enabling efficient and scalable multimodal dataset distillation. Extensive experiments demonstrate that our approach consistently outperforms optimization-based dataset distillation and subset selection methods, achieving state-of-the-art cross-architecture generalization.