VGGT-MPR: VGGT-Enhanced Multimodal Place Recognition in Autonomous Driving Environments
作者: Jingyi Xu, Zhangshuo Qi, Zhongmiao Yan, Xuyu Gao, Qianyun Jiao, Songpengcheng Xia, Xieyuanli Chen, Ling Pei
分类: cs.CV
发布日期: 2026-02-23
💡 一句话要点
提出VGGT-MPR,利用视觉几何Transformer增强多模态地点识别,提升自动驾驶定位精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 地点识别 自动驾驶 视觉几何Transformer 深度学习
📋 核心要点
- 现有MPR方法依赖手工融合策略和重参数化骨干网络,缺乏效率和泛化性。
- VGGT-MPR利用视觉几何Transformer,融合视觉和LiDAR数据,提升地点识别的鲁棒性和准确性。
- 实验表明,VGGT-MPR在各种环境变化下均表现出色,达到state-of-the-art水平。
📝 摘要(中文)
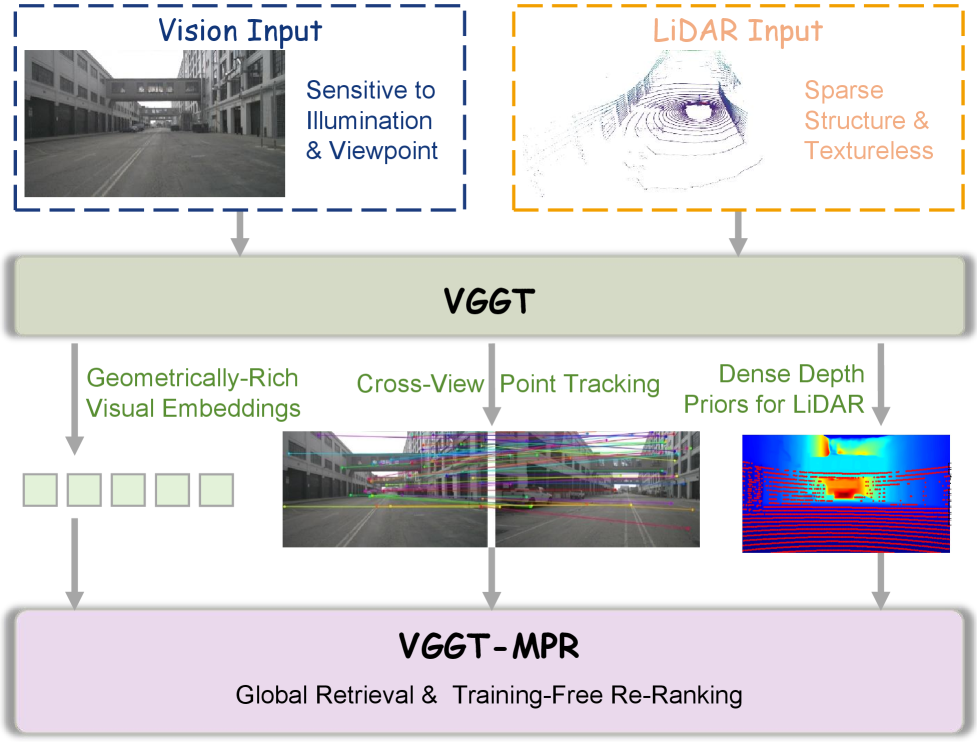
在自动驾驶中,稳健的地点识别对于全局定位和闭环检测至关重要。多模态地点识别(MPR)中相机和激光雷达数据的跨模态融合,在克服单模态局限性方面显示出潜力,但现有MPR方法主要依赖于手工设计的融合策略和需要昂贵重新训练的重参数化骨干网络。为了解决这个问题,我们提出了VGGT-MPR,一个多模态地点识别框架,它采用视觉几何基础Transformer(VGGT)作为统一的几何引擎,用于全局检索和重排序。在全局检索阶段,VGGT通过先验的深度感知和点云图监督提取几何信息丰富的视觉嵌入,并利用预测的深度图来稠密化稀疏的激光雷达点云,从而改善结构表示。这增强了融合多模态特征的区分能力,并生成用于快速检索的全局描述符。在全局检索之外,我们设计了一种无需训练的重排序机制,该机制利用VGGT的跨视图关键点跟踪能力。通过将mask引导的关键点提取与置信度感知的对应关系评分相结合,我们提出的重排序机制有效地细化了检索结果,而无需额外的参数优化。在大型自动驾驶基准和我们自己收集的数据上进行的大量实验表明,VGGT-MPR实现了最先进的性能,对严重的环境变化、视点变化和遮挡表现出强大的鲁棒性。我们的代码和数据将公开提供。
🔬 方法详解
问题定义:现有的多模态地点识别方法依赖于手工设计的融合策略,并且使用参数量巨大的骨干网络,导致模型训练成本高昂,泛化能力受限。尤其是在环境变化剧烈、视点偏移和遮挡等情况下,性能会显著下降。
核心思路:本文的核心思路是利用Visual Geometry Grounded Transformer (VGGT) 作为统一的几何引擎,同时处理视觉和LiDAR数据,提取几何信息丰富的特征表示。通过深度感知和点云图监督,VGGT能够更好地理解场景的几何结构,从而提升地点识别的准确性和鲁棒性。此外,还设计了一种无需训练的重排序机制,进一步优化检索结果。
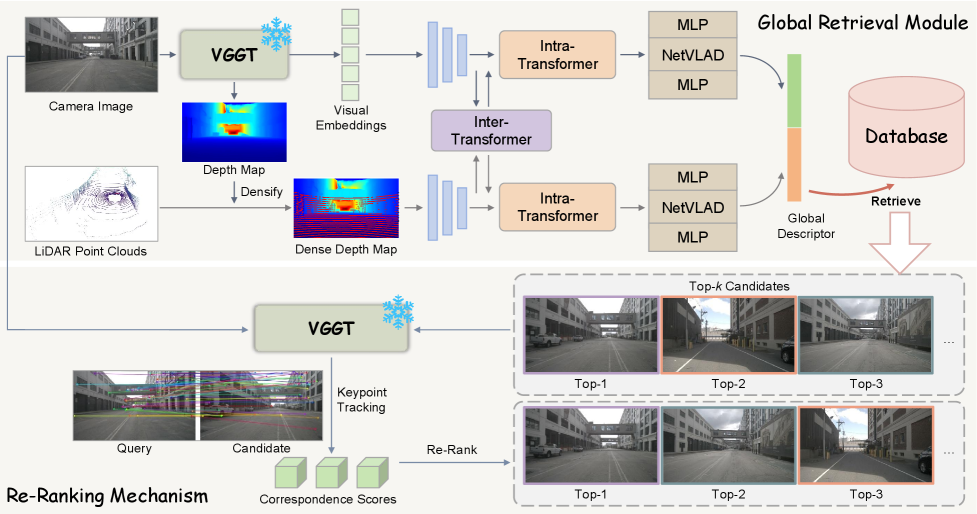
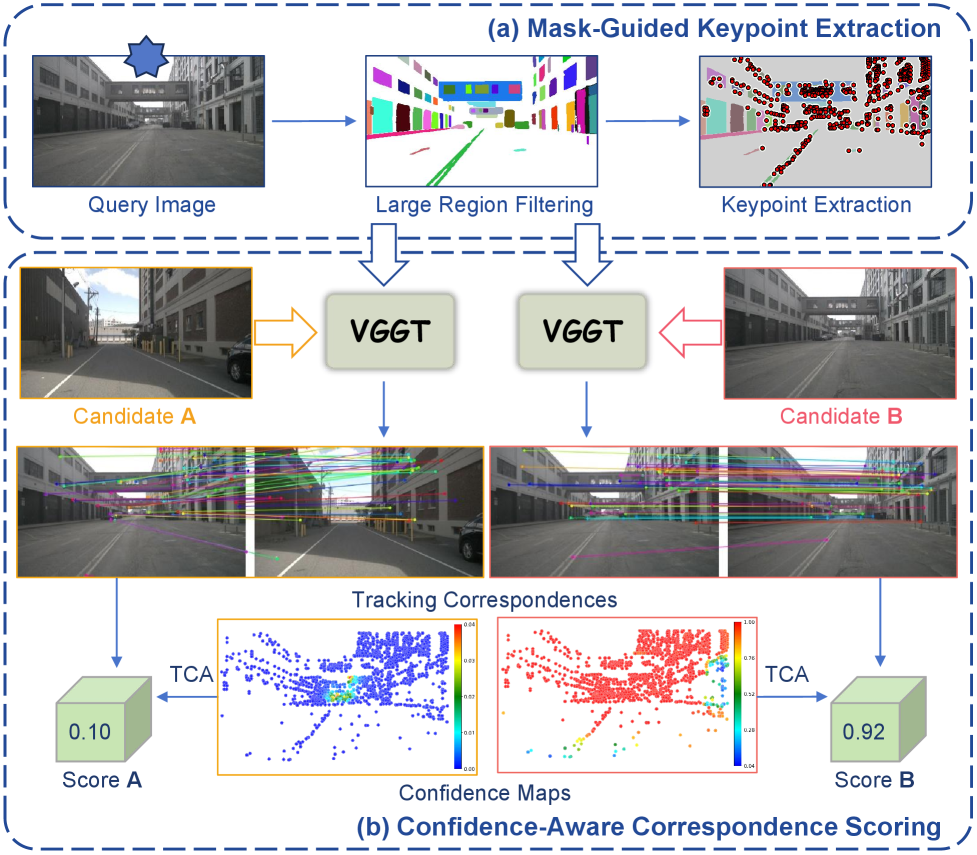
技术框架:VGGT-MPR框架包含两个主要阶段:全局检索和重排序。在全局检索阶段,首先使用VGGT提取视觉特征,并利用预测的深度图稠密化LiDAR点云。然后,将融合后的多模态特征用于生成全局描述符,进行快速检索。在重排序阶段,利用VGGT的跨视图关键点跟踪能力,结合mask引导的关键点提取和置信度感知的对应关系评分,对检索结果进行优化。
关键创新:该论文的关键创新在于将VGGT引入多模态地点识别任务,并将其作为统一的几何引擎。VGGT能够有效地融合视觉和LiDAR数据,提取几何信息丰富的特征表示,从而提升地点识别的准确性和鲁棒性。此外,无需训练的重排序机制也是一个重要的创新点,它能够在不增加额外参数的情况下,进一步优化检索结果。
关键设计:在全局检索阶段,使用了深度感知和点云图监督来训练VGGT,使其能够更好地理解场景的几何结构。在重排序阶段,使用了mask引导的关键点提取,以减少噪声的影响。同时,使用了置信度感知的对应关系评分,以提高匹配的准确性。具体的损失函数和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
VGGT-MPR在多个大规模自动驾驶数据集上取得了state-of-the-art的性能。实验结果表明,该方法对严重的环境变化、视点偏移和遮挡具有很强的鲁棒性。具体性能数据和对比基线在论文中有详细描述(未知)。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、增强现实等领域。通过提高地点识别的准确性和鲁棒性,可以提升自动驾驶系统的安全性和可靠性,实现更精确的定位和导航。此外,该技术还可以应用于机器人室内导航、AR/VR场景构建等领域,具有广阔的应用前景。
📄 摘要(原文)
In autonomous driving, robust place recognition is critical for global localization and loop closure detection. While inter-modality fusion of camera and LiDAR data in multimodal place recognition (MPR) has shown promise in overcoming the limitations of unimodal counterparts, existing MPR methods basically attend to hand-crafted fusion strategies and heavily parameterized backbones that require costly retraining. To address this, we propose VGGT-MPR, a multimodal place recognition framework that adopts the Visual Geometry Grounded Transformer (VGGT) as a unified geometric engine for both global retrieval and re-ranking. In the global retrieval stage, VGGT extracts geometrically-rich visual embeddings through prior depth-aware and point map supervision, and densifies sparse LiDAR point clouds with predicted depth maps to improve structural representation. This enhances the discriminative ability of fused multimodal features and produces global descriptors for fast retrieval. Beyond global retrieval, we design a training-free re-ranking mechanism that exploits VGGT's cross-view keypoint-tracking capability. By combining mask-guided keypoint extraction with confidence-aware correspondence scoring, our proposed re-ranking mechanism effectively refines retrieval results without additional parameter optimization. Extensive experiments on large-scale autonomous driving benchmarks and our self-collected data demonstrate that VGGT-MPR achieves state-of-the-art performance, exhibiting strong robustness to severe environmental changes, viewpoint shifts, and occlusions. Our code and data will be made publicly available.