Universal Pose Pretraining for Generalizable Vision-Language-Action Policies
作者: Haitao Lin, Hanyang Yu, Jingshun Huang, He Zhang, Yonggen Ling, Ping Tan, Xiangyang Xue, Yanwei Fu
分类: cs.CV, cs.LG, cs.RO
发布日期: 2026-02-23
💡 一句话要点
提出Pose-VLA,解耦视觉-语言-动作模型中的感知与动作对齐问题,提升泛化性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 姿态预训练 具身智能 机器人操作 3D空间表示
📋 核心要点
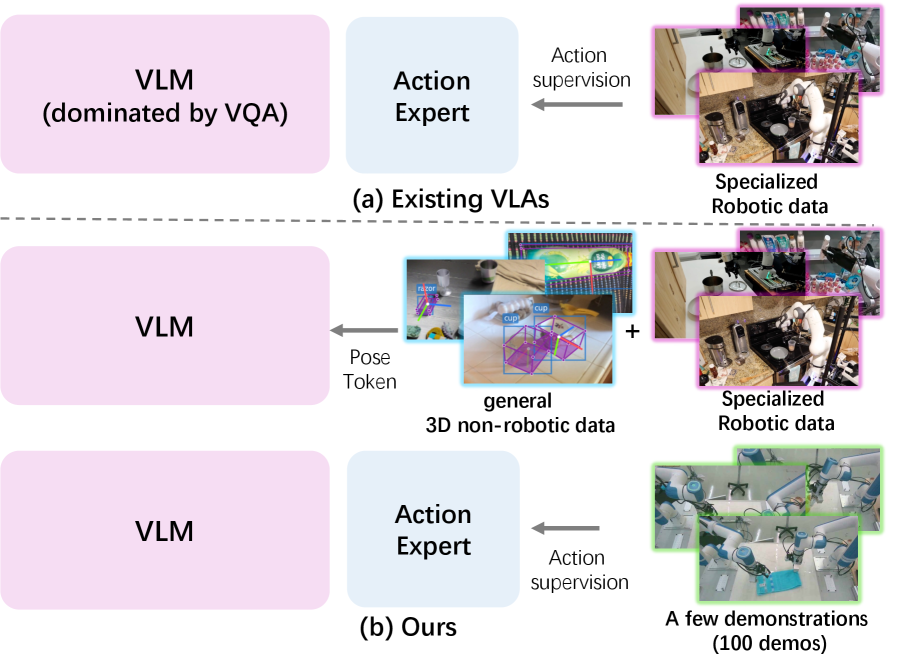
- 现有VLA模型将高级感知与具身动作监督纠缠,导致特征崩溃和泛化性差,难以捕捉细微的3D状态变化。
- Pose-VLA通过解耦感知和动作对齐,利用姿态token作为通用表示,实现跨数据集的空间 grounding 和运动对齐。
- 实验表明,Pose-VLA在RoboTwin 2.0和LIBERO上取得了SOTA或具有竞争力的结果,并展现了良好的真实世界泛化能力。
📝 摘要(中文)
现有的视觉-语言-动作(VLA)模型常因高级感知与稀疏、特定于具身智能的动作监督相纠缠,导致特征崩溃和训练效率低下。这些模型通常依赖于为视觉问答(VQA)优化的VLM骨干网络,擅长语义识别,但忽略了细微的3D状态变化,而这些变化决定了不同的动作模式。为了解决这些错位问题,我们提出了Pose-VLA,一种解耦范式,将VLA训练分为预训练阶段(用于在统一的相机中心空间中提取通用的3D空间先验)和后训练阶段(用于在机器人特定的动作空间内进行高效的具身智能对齐)。通过引入离散姿态token作为通用表示,Pose-VLA无缝地整合了来自不同3D数据集的空间 grounding 和来自机器人演示的几何级别轨迹。我们的框架遵循两阶段预训练流程,首先通过姿态建立基本的空间 grounding,然后通过轨迹监督进行运动对齐。大量评估表明,Pose-VLA在RoboTwin 2.0上取得了最先进的结果,平均成功率为79.5%,在LIBERO上取得了96.0%的竞争性表现。真实世界的实验进一步展示了在不同对象上的鲁棒泛化能力,每个任务仅使用100个演示,验证了我们预训练范式的效率。
🔬 方法详解
问题定义:现有VLA模型在处理视觉-语言-动作任务时,由于直接将视觉感知与特定机器人的动作空间进行耦合,导致模型难以泛化到新的环境和任务中。模型过度依赖视觉问答(VQA)任务的预训练,忽略了对动作至关重要的细微3D状态变化。这种耦合导致特征崩溃和训练效率低下。
核心思路:Pose-VLA的核心思路是将VLA模型的训练过程解耦为两个阶段:预训练阶段和后训练阶段。预训练阶段专注于学习通用的3D空间先验知识,不依赖于特定的机器人动作空间。后训练阶段则将预训练得到的空间先验知识与特定机器人的动作空间进行对齐。通过这种解耦,模型可以更好地泛化到新的环境和任务中。
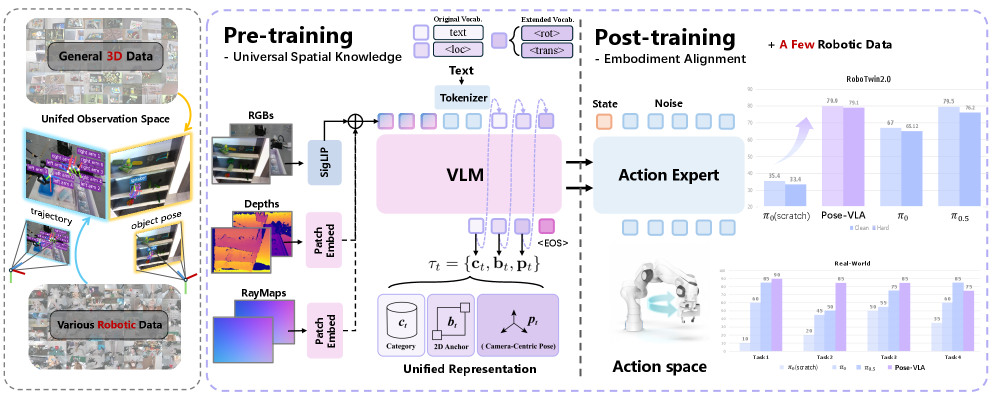
技术框架:Pose-VLA框架包含两个主要阶段:1) 预训练阶段:使用来自不同3D数据集的姿态信息进行预训练,学习通用的3D空间表示。该阶段使用离散姿态token作为通用表示,将不同数据集的空间信息统一到一个相机中心空间中。2) 后训练阶段:使用机器人演示数据,将预训练得到的空间表示与特定机器人的动作空间进行对齐。该阶段通过轨迹监督的方式,学习从空间表示到机器人动作的映射关系。
关键创新:Pose-VLA的关键创新在于:1) 解耦感知和动作对齐:将VLA模型的训练过程解耦为预训练和后训练两个阶段,分别学习通用的空间先验知识和特定机器人的动作空间。2) 使用离散姿态token作为通用表示:通过离散姿态token,将来自不同3D数据集的空间信息统一到一个相机中心空间中,实现跨数据集的空间 grounding。
关键设计:Pose-VLA使用两阶段预训练流程。第一阶段,通过姿态信息建立基本的空间 grounding。第二阶段,通过轨迹监督进行运动对齐。具体的技术细节包括:使用Transformer网络作为模型的主体结构;使用交叉熵损失函数进行姿态预测;使用均方误差损失函数进行轨迹预测;使用数据增强技术提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
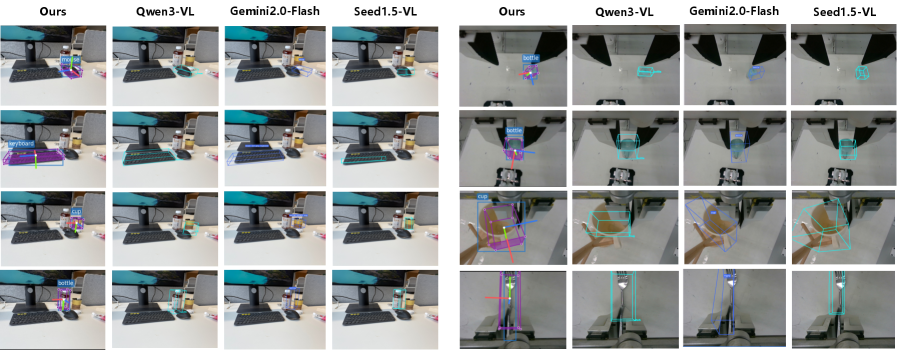
Pose-VLA在RoboTwin 2.0上取得了79.5%的平均成功率,超越了现有方法。在LIBERO数据集上,Pose-VLA的成功率达到96.0%,展现了强大的竞争力。更重要的是,在真实世界的实验中,Pose-VLA仅使用每个任务100个演示,就能在不同对象上实现鲁棒的泛化,验证了预训练范式的效率。
🎯 应用场景
Pose-VLA具有广泛的应用前景,可应用于机器人操作、自动驾驶、虚拟现实等领域。通过学习通用的3D空间先验知识,Pose-VLA可以帮助机器人更好地理解周围环境,从而实现更智能、更灵活的动作规划和控制。该研究成果有助于推动机器人技术的发展,使其能够更好地服务于人类。
📄 摘要(原文)
Existing Vision-Language-Action (VLA) models often suffer from feature collapse and low training efficiency because they entangle high-level perception with sparse, embodiment-specific action supervision. Since these models typically rely on VLM backbones optimized for Visual Question Answering (VQA), they excel at semantic identification but often overlook subtle 3D state variations that dictate distinct action patterns. To resolve these misalignments, we propose Pose-VLA, a decoupled paradigm that separates VLA training into a pre-training phase for extracting universal 3D spatial priors in a unified camera-centric space, and a post-training phase for efficient embodiment alignment within robot-specific action space. By introducing discrete pose tokens as a universal representation, Pose-VLA seamlessly integrates spatial grounding from diverse 3D datasets with geometry-level trajectories from robotic demonstrations. Our framework follows a two-stage pre-training pipeline, establishing fundamental spatial grounding via poses followed by motion alignment through trajectory supervision. Extensive evaluations demonstrate that Pose-VLA achieves state-of-the-art results on RoboTwin 2.0 with a 79.5% average success rate and competitive performance on LIBERO at 96.0%. Real-world experiments further showcase robust generalization across diverse objects using only 100 demonstrations per task, validating the efficiency of our pre-training paradigm.