TeHOR: Text-Guided 3D Human and Object Reconstruction with Textures
作者: Hyeongjin Nam, Daniel Sungho Jung, Kyoung Mu Lee
分类: cs.CV, cs.AI
发布日期: 2026-02-23
备注: Published at CVPR 2026, 20 pages including the supplementary material
💡 一句话要点
TeHOR:提出文本引导的3D人体与物体纹理重建框架,解决非接触交互建模难题。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 3D重建 人体建模 物体建模 纹理生成 文本引导 人机交互 非接触交互
📋 核心要点
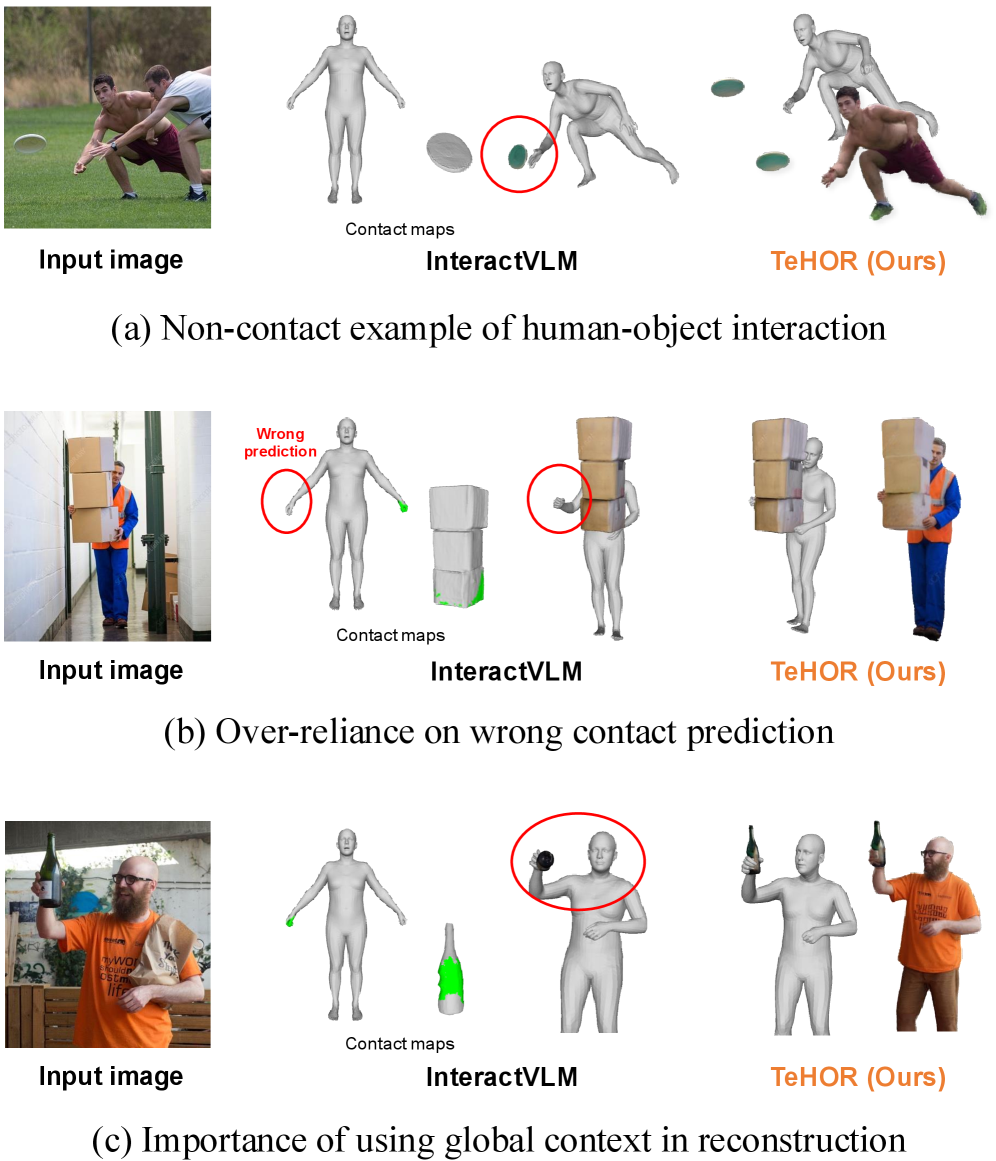
- 现有3D人体与物体联合重建方法依赖物理接触信息,无法处理非接触交互,限制了应用范围。
- TeHOR利用文本描述引导重建,实现语义对齐,并融入外观信息,捕捉整体上下文,提升重建质量。
- 实验表明,TeHOR在3D人体与物体联合重建任务上取得了state-of-the-art的性能,重建结果更准确、语义更连贯。
📝 摘要(中文)
本文提出了一种名为TeHOR的框架,用于从单张图像中联合重建3D人体和物体,并赋予纹理。现有方法主要依赖物理接触信息,无法捕捉非接触的人与物交互,且重建过程侧重局部几何邻近性,忽略了人体和物体的外观信息。TeHOR框架通过利用人与物交互的文本描述,强制3D重建与文本线索之间的语义对齐,从而能够推理更广泛的交互类型,包括非接触情况。此外,该框架还将3D人体和物体的外观信息纳入对齐过程,以捕捉整体上下文信息,确保视觉上合理的重建。实验结果表明,TeHOR能够生成准确且语义连贯的重建结果,达到目前最优的性能。
🔬 方法详解
问题定义:现有方法在3D人体与物体联合重建中,过度依赖物理接触信息,导致无法处理诸如注视、指向等非接触交互场景。此外,重建过程主要关注局部几何信息,忽略了全局上下文,使得重建结果在语义上可能不合理。因此,需要一种能够理解非接触交互,并能结合全局上下文信息的重建方法。
核心思路:TeHOR的核心思路是利用文本描述作为指导,将3D重建与文本描述进行语义对齐,从而能够理解更广泛的人与物交互关系,包括非接触情况。同时,融入人体和物体的外观信息,捕捉全局上下文,保证重建结果的视觉合理性。
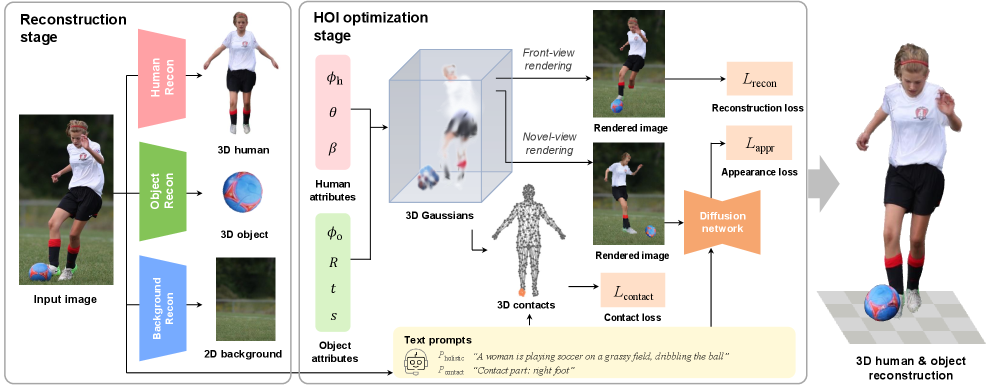
技术框架:TeHOR框架包含以下主要模块:首先,利用图像和文本信息提取特征。然后,通过一个3D人体和物体重建模块生成初始的3D模型。接着,利用文本描述和外观信息,设计语义对齐损失和外观一致性损失,优化3D模型,使其与文本描述和视觉信息保持一致。最后,渲染得到带有纹理的3D人体和物体模型。
关键创新:TeHOR的关键创新在于引入了文本引导的重建方法,将文本信息作为一种先验知识,指导3D重建过程,从而能够处理非接触交互场景。此外,将外观信息融入重建过程,增强了模型的上下文理解能力,使得重建结果更加合理。
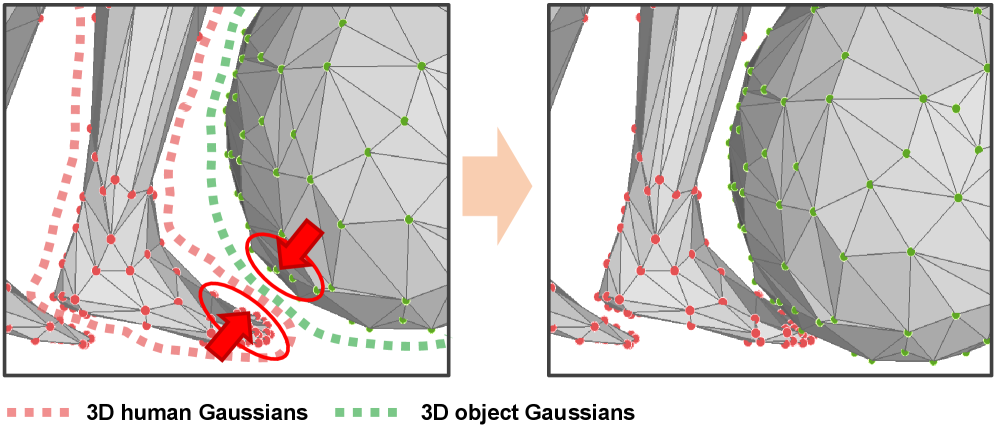
关键设计:在语义对齐方面,设计了对比学习损失,使得重建的3D场景与对应的文本描述在特征空间中更加接近。在外观一致性方面,使用了纹理损失,保证重建的3D模型的纹理与输入图像中的外观信息一致。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
TeHOR在3D人体与物体联合重建任务上取得了显著的性能提升,超越了现有的state-of-the-art方法。实验结果表明,TeHOR能够更准确地重建人体和物体的3D结构,并生成更逼真的纹理。此外,TeHOR在处理非接触交互场景时表现出更强的鲁棒性,能够生成语义上更合理的重建结果。
🎯 应用场景
TeHOR在机器人、虚拟现实、增强现实和数字内容创作等领域具有广泛的应用前景。例如,可以用于创建逼真的人机交互场景,设计更智能的机器人行为,以及生成高质量的3D动画和游戏角色。该研究有助于提升人机交互的自然性和真实感,并为数字内容创作提供更强大的工具。
📄 摘要(原文)
Joint reconstruction of 3D human and object from a single image is an active research area, with pivotal applications in robotics and digital content creation. Despite recent advances, existing approaches suffer from two fundamental limitations. First, their reconstructions rely heavily on physical contact information, which inherently cannot capture non-contact human-object interactions, such as gazing at or pointing toward an object. Second, the reconstruction process is primarily driven by local geometric proximity, neglecting the human and object appearances that provide global context crucial for understanding holistic interactions. To address these issues, we introduce TeHOR, a framework built upon two core designs. First, beyond contact information, our framework leverages text descriptions of human-object interactions to enforce semantic alignment between the 3D reconstruction and its textual cues, enabling reasoning over a wider spectrum of interactions, including non-contact cases. Second, we incorporate appearance cues of the 3D human and object into the alignment process to capture holistic contextual information, thereby ensuring visually plausible reconstructions. As a result, our framework produces accurate and semantically coherent reconstructions, achieving state-of-the-art performance.