Seeing Clearly, Reasoning Confidently: Plug-and-Play Remedies for Vision Language Model Blindness
作者: Xin Hu, Haomiao Ni, Yunbei Zhang, Jihun Hamm, Zechen Li, Zhengming Ding
分类: cs.CV
发布日期: 2026-02-23
备注: Accepted by CVPR 2026
💡 一句话要点
提出即插即用模块,提升视觉语言模型在罕见物体上的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 罕见物体识别 多模态学习 即插即用模块 视觉推理
📋 核心要点
- 现有视觉语言模型在罕见物体推理上表现不佳,主要原因是预训练数据中相关样本稀少。
- 论文提出一种即插即用模块,通过学习多模态类嵌入来增强视觉tokens和文本提示,无需微调。
- 实验表明,该方法在罕见物体识别和推理任务上取得了显著提升,增强了模型对罕见物体的关注能力。
📝 摘要(中文)
视觉语言模型(VLMs)在广泛的视觉理解方面取得了显著成功,但由于预训练数据中此类实例的稀缺性,它们在罕见物体的以物体为中心的推理方面仍然面临挑战。先前的研究通过检索额外数据或引入更强的视觉编码器来缓解这个问题,但这些方法在微调VLMs期间仍然计算密集,并且没有充分利用原始训练数据。本文介绍了一种高效的即插即用模块,通过细化视觉tokens和丰富输入文本提示,显著提高了VLMs对罕见物体的推理能力,而无需VLMs微调。具体来说,我们建议利用视觉基础模型的先验知识和同义词增强的文本描述,为罕见物体学习多模态类嵌入,以弥补有限的训练样本。这些嵌入通过一个轻量级的基于注意力的增强模块来细化VLMs中的视觉tokens,从而改善细粒度的物体细节。此外,我们使用学习到的嵌入作为物体感知检测器来生成信息提示,这些提示被注入到文本提示中,以帮助引导VLMs的注意力集中到相关的图像区域。在两个基准测试上的实验表明,预训练的VLMs在罕见物体识别和推理方面取得了持续且显著的收益。进一步的分析揭示了我们的方法如何加强VLMs关注和推理罕见物体的能力。
🔬 方法详解
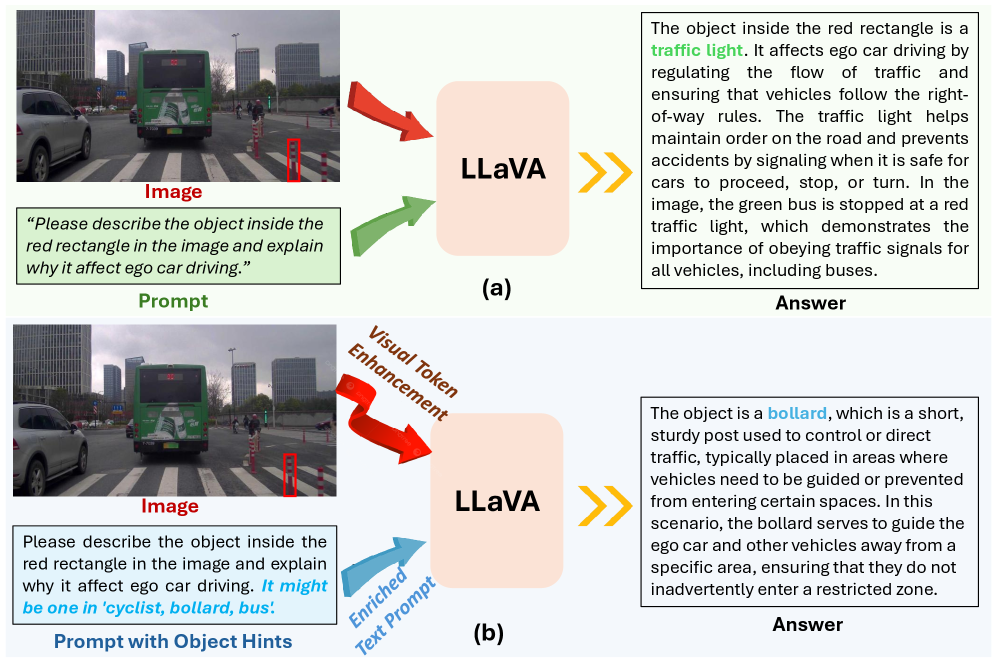
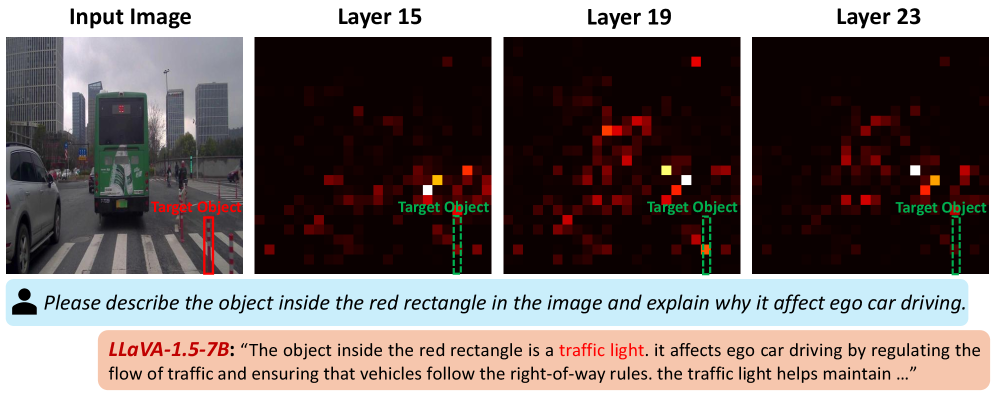
问题定义:视觉语言模型在处理罕见物体相关的推理任务时,由于训练数据中罕见物体样本的匮乏,表现出明显的“视觉盲区”。现有方法通常依赖于增加额外数据或增强视觉编码器,但这增加了计算成本,且未能充分利用原始训练数据。
核心思路:该论文的核心思路是通过学习罕见物体的多模态类嵌入,来增强视觉tokens和文本提示,从而提升视觉语言模型对罕见物体的感知和推理能力。这种方法无需对整个视觉语言模型进行微调,具有即插即用的特性。
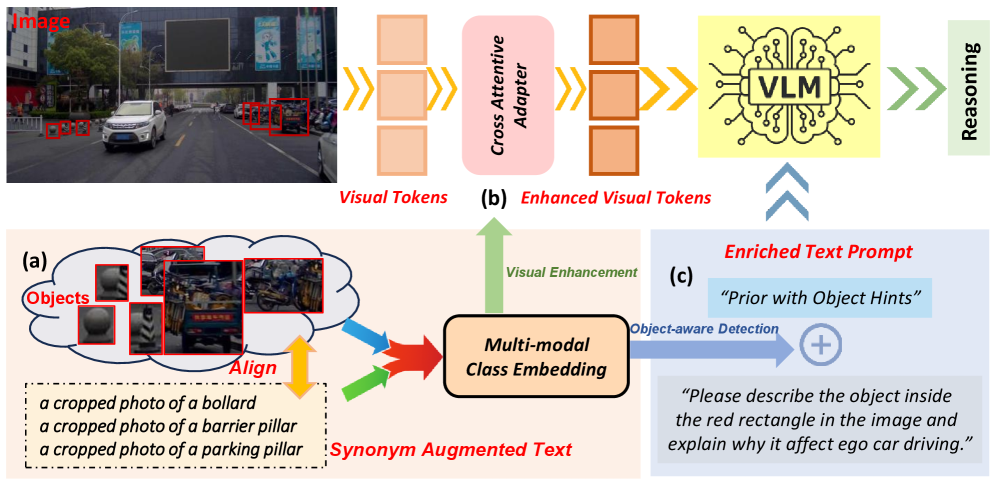
技术框架:该方法主要包含两个模块:视觉tokens增强模块和文本提示增强模块。首先,利用视觉基础模型和同义词增强的文本描述,为罕见物体学习多模态类嵌入。然后,视觉tokens增强模块利用这些嵌入来细化视觉tokens,提升对细粒度物体细节的感知。同时,文本提示增强模块将这些嵌入作为物体感知检测器,生成信息提示并注入到文本提示中,引导视觉语言模型关注相关图像区域。
关键创新:该方法的关键创新在于提出了一种轻量级的即插即用模块,可以在不微调整个视觉语言模型的情况下,显著提升其在罕见物体上的推理能力。通过学习多模态类嵌入,有效地弥补了训练数据中罕见物体样本的不足。
关键设计:视觉tokens增强模块采用基于注意力的机制,利用学习到的多模态类嵌入来细化视觉tokens。文本提示增强模块则将这些嵌入作为物体感知检测器,生成包含物体信息的提示,并将其添加到原始文本提示中。具体的参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在两个基准测试上均取得了显著的性能提升。具体而言,在罕见物体识别和推理任务上,预训练的视觉语言模型在使用该方法后,性能得到了持续且大幅度的提升。具体的性能数据和对比基线在论文中进行了详细展示(未知)。
🎯 应用场景
该研究成果可应用于各种需要识别和推理罕见物体的场景,例如:自动驾驶(识别罕见的交通标志或行人)、医疗诊断(识别罕见的疾病症状)、工业质检(检测罕见的缺陷产品)等。该方法能够提升视觉语言模型在这些场景下的可靠性和准确性,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Vision language models (VLMs) have achieved remarkable success in broad visual understanding, yet they remain challenged by object-centric reasoning on rare objects due to the scarcity of such instances in pretraining data. While prior efforts alleviate this issue by retrieving additional data or introducing stronger vision encoders, these methods are still computationally intensive during finetuning VLMs and don't fully exploit the original training data. In this paper, we introduce an efficient plug-and-play module that substantially improves VLMs' reasoning over rare objects by refining visual tokens and enriching input text prompts, without VLMs finetuning. Specifically, we propose to learn multi-modal class embeddings for rare objects by leveraging prior knowledge from vision foundation models and synonym-augmented text descriptions, compensating for limited training examples. These embeddings refine the visual tokens in VLMs through a lightweight attention-based enhancement module that improves fine-grained object details. In addition, we use the learned embeddings as object-aware detectors to generate informative hints, which are injected into the text prompts to help guide the VLM's attention toward relevant image regions. Experiments on two benchmarks show consistent and substantial gains for pretrained VLMs in rare object recognition and reasoning. Further analysis reveals how our method strengthens the VLM's ability to focus on and reason about rare objects.