HOCA-Bench: Beyond Semantic Perception to Predictive World Modeling via Hegelian Ontological-Causal Anomalies
作者: Chang Liu, Yunfan Ye, Qingyang Zhou, Xichen Tan, Mengxuan Luo, Zhenyu Qiu, Wei Peng, Zhiping Cai
分类: cs.CV
发布日期: 2026-02-23
💡 一句话要点
提出HOCA-Bench基准测试,评估视频LLM在本体因果异常预测世界建模能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频大语言模型 物理世界建模 异常检测 因果推理 本体异常 基准测试 视频理解
📋 核心要点
- 现有视频LLM在语义感知上有所提升,但在物理世界建模和预测方面存在不足,无法很好地理解物理规律。
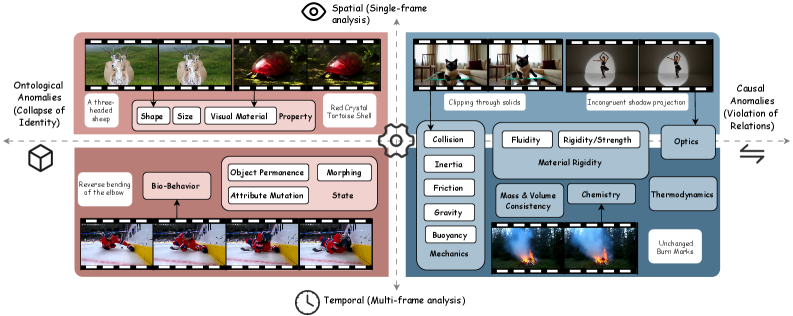
- HOCA-Bench基准测试从本体和因果两个角度定义物理异常,用于评估模型对物理世界规律的理解和预测能力。
- 实验表明,现有视频LLM在处理因果异常时性能显著下降,表明模型更擅长识别视觉模式而非应用物理定律。
📝 摘要(中文)
视频大语言模型(Video-LLMs)在语义感知方面取得了稳步进展,但在预测世界建模方面仍然不足,而预测世界建模对于物理基础智能至关重要。我们引入了HOCA-Bench,一个通过黑格尔视角构建物理异常的基准测试。HOCA-Bench将异常分为两种类型:本体异常,其中实体违反了自身的定义或持久性;因果异常,其中交互违反了物理关系。我们使用最先进的生成视频模型作为对抗模拟器,构建了一个包含1,439个视频(3,470个问答对)的测试平台。对17个Video-LLM的评估表明存在明显的认知滞后:模型通常可以识别静态的本体违反(例如,形状突变),但在因果机制(例如,重力或摩擦力)方面表现不佳,因果任务的性能下降超过20%。系统2“思考”模式提高了推理能力,但并未消除差距,这表明当前的架构更容易识别视觉模式,而不是应用基本的物理定律。
🔬 方法详解
问题定义:现有视频大语言模型虽然在语义感知方面取得了进展,但缺乏对物理世界的理解和预测能力,尤其是在处理违反物理规律的异常情况时表现不佳。现有的评估方法难以全面衡量模型在物理世界建模方面的能力。
核心思路:论文的核心思路是通过构建一个包含本体异常和因果异常的基准测试集,来评估视频LLM对物理世界规律的理解和预测能力。本体异常指实体违反自身定义或持久性的情况,因果异常指交互违反物理关系的情况。通过这种方式,可以更全面地考察模型是否真正理解了物理世界的运作方式。
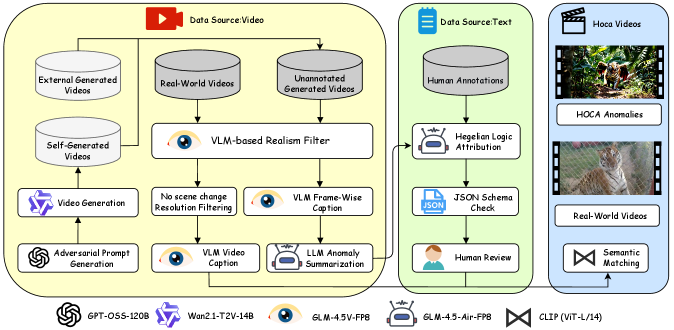
技术框架:HOCA-Bench基准测试的构建流程如下:首先,定义本体异常和因果异常的类型;然后,使用生成视频模型作为对抗模拟器,生成包含这些异常的视频;最后,为每个视频创建相应的问答对,用于评估视频LLM的性能。整个框架旨在创建一个具有挑战性的测试平台,能够有效区分不同模型在物理世界建模方面的能力差异。
关键创新:该论文的关键创新在于提出了基于黑格尔哲学的本体因果异常(HOCA)概念,并将其应用于视频LLM的评估。这种分类方法能够更细致地刻画物理异常的类型,从而更准确地评估模型对物理世界规律的理解程度。此外,使用生成视频模型作为对抗模拟器,可以高效地生成大量包含各种异常的视频数据。
关键设计:HOCA-Bench包含1,439个视频和3,470个问答对。视频由生成模型生成,确保了数据的多样性和可控性。问答对的设计涵盖了对本体异常和因果异常的识别和推理。论文评估了17个视频LLM,并分析了它们在不同类型异常上的表现。实验中还考察了系统2“思考”模式对推理能力的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有视频LLM在处理因果异常时性能显著下降,下降幅度超过20%,表明模型更擅长识别视觉模式而非应用物理定律。即使采用系统2“思考”模式,也无法完全弥补这一差距。HOCA-Bench能够有效区分不同模型在物理世界建模方面的能力差异。
🎯 应用场景
该研究成果可应用于提升机器人、自动驾驶等领域中智能体的环境感知和决策能力。通过提高模型对物理世界规律的理解,可以使智能体在复杂环境中做出更安全、更合理的行为。此外,HOCA-Bench可以作为评估和改进视频LLM物理推理能力的有效工具。
📄 摘要(原文)
Video-LLMs have improved steadily on semantic perception, but they still fall short on predictive world modeling, which is central to physically grounded intelligence. We introduce HOCA-Bench, a benchmark that frames physical anomalies through a Hegelian lens. HOCA-Bench separates anomalies into two types: ontological anomalies, where an entity violates its own definition or persistence, and causal anomalies, where interactions violate physical relations. Using state-of-the-art generative video models as adversarial simulators, we build a testbed of 1,439 videos (3,470 QA pairs). Evaluations on 17 Video-LLMs show a clear cognitive lag: models often identify static ontological violations (e.g., shape mutations) but struggle with causal mechanisms (e.g., gravity or friction), with performance dropping by more than 20% on causal tasks. System-2 "Thinking" modes improve reasoning, but they do not close the gap, suggesting that current architectures recognize visual patterns more readily than they apply basic physical laws.