Vinedresser3D: Agentic Text-guided 3D Editing
作者: Yankuan Chi, Xiang Li, Zixuan Huang, James M. Rehg
分类: cs.CV
发布日期: 2026-02-23
备注: CVPR 2026, Project website:https://vinedresser3d.github.io/
💡 一句话要点
Vinedresser3D:提出基于Agent的文本引导3D编辑框架,实现高质量、精确的3D资产修改。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本引导3D编辑 Agentic框架 多模态大语言模型 修正流 3D生成模型
📋 核心要点
- 现有文本引导的3D编辑方法难以理解复杂提示、自动定位3D编辑区域并保持未编辑内容不变。
- Vinedresser3D利用多模态大语言模型分解编辑任务,并结合图像编辑和3D生成模型,实现精确控制。
- 实验结果表明,Vinedresser3D在编辑质量和用户偏好上优于现有方法,实现了更精确和连贯的编辑效果。
📝 摘要(中文)
本文提出Vinedresser3D,一个基于Agent的高质量文本引导3D编辑框架,它直接在原生3D生成模型的潜在空间中运行。给定一个3D资产和编辑提示,Vinedresser3D利用多模态大型语言模型推断原始资产的丰富描述,识别编辑区域和编辑类型(添加、修改、删除),并生成分解的结构和外观级别的文本指导。然后,Agent选择信息量丰富的视图,并应用图像编辑模型以获得视觉指导。最后,一个基于反演的修正流(rectified-flow)修复(inpainting)管道,结合交错采样模块,在3D潜在空间中执行编辑,在保持3D一致性和未编辑区域的同时,强制提示对齐。在各种3D编辑上的实验表明,Vinedresser3D在自动指标和人类偏好研究中均优于先前的基线,同时实现了精确、连贯且无掩模的3D编辑。
🔬 方法详解
问题定义:现有文本引导的3D编辑方法在处理复杂指令时表现不佳,难以准确识别需要编辑的3D区域,并且容易破坏未编辑区域的内容一致性。这些方法通常缺乏对3D场景的深入理解和精细控制能力,导致编辑结果不够理想。
核心思路:Vinedresser3D的核心在于利用Agent的思想,将复杂的文本引导3D编辑任务分解为多个可控的子任务,并利用多模态大语言模型进行推理和决策。通过分解任务,可以更精确地控制编辑过程,并更好地保持3D场景的一致性。同时,结合图像编辑模型和3D生成模型,可以实现更精细的编辑效果。
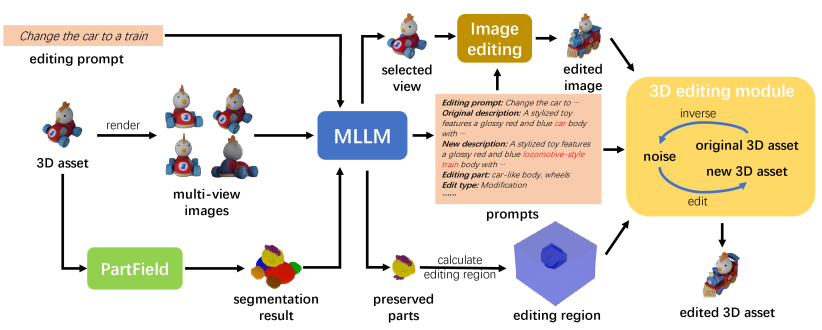
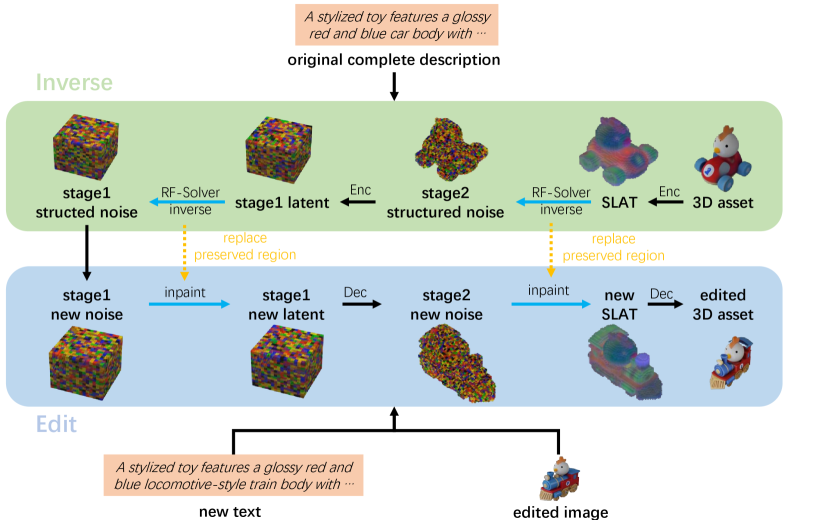
技术框架:Vinedresser3D框架主要包含以下几个模块:1) 多模态大语言模型:用于理解编辑提示,识别编辑区域和类型,并生成结构化和外观级别的文本指导。2) 图像编辑模型:用于根据文本指导生成视觉指导,提供更直观的编辑信息。3) 基于反演的修正流修复管道:在3D潜在空间中执行编辑,保持3D一致性和未编辑区域。4) 交错采样模块:用于提高编辑质量和效率。整体流程是,首先利用大语言模型分析输入,然后通过图像编辑模型生成视觉指导,最后在3D潜在空间中进行编辑。
关键创新:Vinedresser3D的关键创新在于其Agentic框架,它能够将复杂的文本引导3D编辑任务分解为多个可控的子任务,并利用多模态大语言模型进行推理和决策。这种分解任务的方式使得编辑过程更加可控,并能够更好地保持3D场景的一致性。此外,结合图像编辑模型和3D生成模型,可以实现更精细的编辑效果。与现有方法相比,Vinedresser3D能够更准确地理解复杂指令,更精确地定位编辑区域,并更好地保持未编辑区域的内容一致性。
关键设计:在多模态大语言模型方面,论文可能采用了预训练的大型语言模型,并针对3D编辑任务进行了微调。在图像编辑模型方面,论文可能采用了基于扩散模型的图像编辑方法。在基于反演的修正流修复管道方面,论文可能采用了预训练的3D生成模型,并利用反演技术将3D资产映射到潜在空间中。交错采样模块的具体实现细节未知,但其目的是提高编辑质量和效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Vinedresser3D在自动指标和人类偏好研究中均优于先前的基线。具体来说,Vinedresser3D在编辑质量、一致性和用户满意度方面均取得了显著提升。这些结果表明,Vinedresser3D能够实现更精确、连贯且无掩模的3D编辑。
🎯 应用场景
Vinedresser3D在游戏开发、虚拟现实、产品设计等领域具有广泛的应用前景。它可以帮助设计师快速修改和定制3D模型,提高设计效率和创作自由度。例如,游戏开发者可以使用该技术快速创建各种风格的游戏角色和场景,产品设计师可以使用该技术快速迭代产品设计方案。
📄 摘要(原文)
Text-guided 3D editing aims to modify existing 3D assets using natural-language instructions. Current methods struggle to jointly understand complex prompts, automatically localize edits in 3D, and preserve unedited content. We introduce Vinedresser3D, an agentic framework for high-quality text-guided 3D editing that operates directly in the latent space of a native 3D generative model. Given a 3D asset and an editing prompt, Vinedresser3D uses a multimodal large language model to infer rich descriptions of the original asset, identify the edit region and edit type (addition, modification, deletion), and generate decomposed structural and appearance-level text guidance. The agent then selects an informative view and applies an image editing model to obtain visual guidance. Finally, an inversion-based rectified-flow inpainting pipeline with an interleaved sampling module performs editing in the 3D latent space, enforcing prompt alignment while maintaining 3D coherence and unedited regions. Experiments on diverse 3D edits demonstrate that Vinedresser3D outperforms prior baselines in both automatic metrics and human preference studies, while enabling precise, coherent, and mask-free 3D editing.