Fore-Mamba3D: Mamba-based Foreground-Enhanced Encoding for 3D Object Detection
作者: Zhiwei Ning, Xuanang Gao, Jiaxi Cao, Runze Yang, Huiying Xu, Xinzhong Zhu, Jie Yang, Wei Liu
分类: cs.CV, cs.AI
发布日期: 2026-02-23
💡 一句话要点
Fore-Mamba3D:基于Mamba的前景增强编码用于3D目标检测
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D目标检测 Mamba 前景增强 体素编码 区域滑动窗口
📋 核心要点
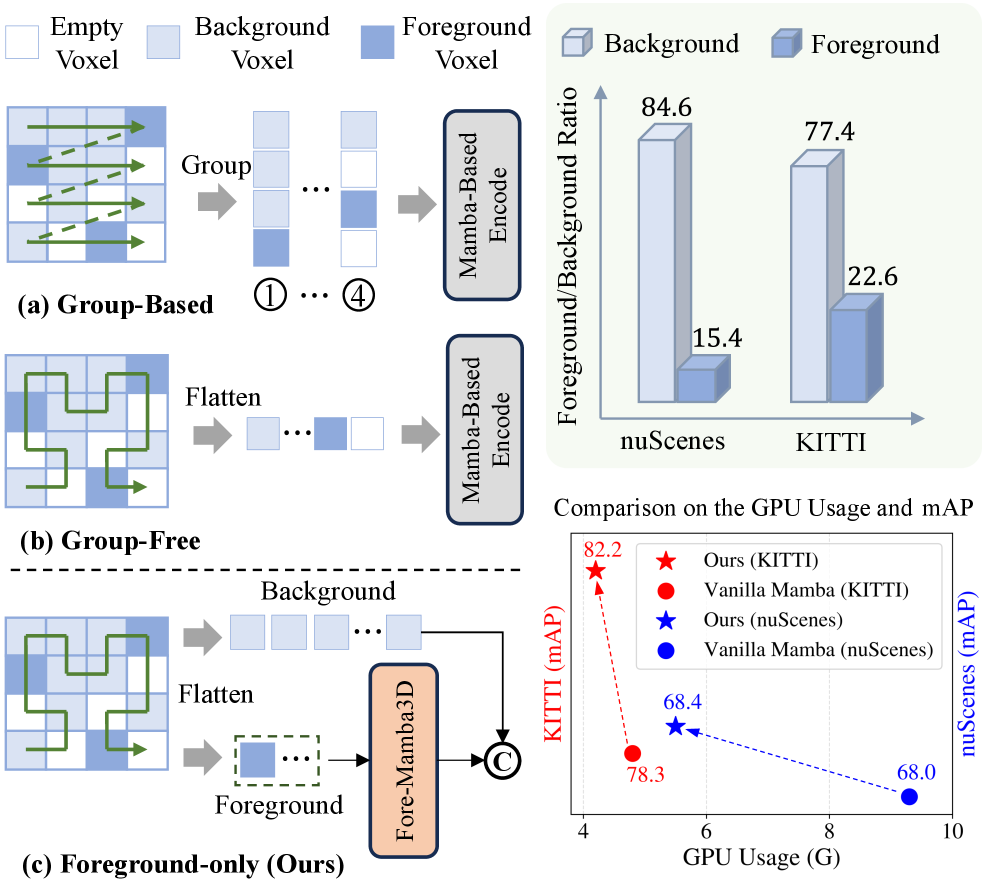
- 现有基于Mamba的3D目标检测方法对包含大量背景信息的体素序列进行编码,效率较低。
- Fore-Mamba3D通过采样前景体素并设计区域到全局滑动窗口(RGSW)和语义辅助融合模块(SASFMamba)来增强前景信息。
- 实验结果表明,Fore-Mamba3D在多个基准测试中表现出卓越的性能,验证了其在3D目标检测任务中的有效性。
📝 摘要(中文)
本文提出了一种名为Fore-Mamba3D的新型骨干网络,旨在改进基于Mamba的3D目标检测方法。现有方法通常对包含大量无用背景信息的完整非空体素序列进行双向编码。虽然直接编码前景体素看似可行,但往往会降低检测性能。我们认为这是由于仅前景序列在线性建模中存在响应衰减和受限的上下文表示。为了解决这个问题,Fore-Mamba3D通过修改基于Mamba的编码器来关注前景增强。首先根据预测分数对前景体素进行采样。考虑到不同实例之间前景体素交互中存在的响应衰减,我们设计了一个区域到全局滑动窗口(RGSW),以将信息从区域分割传播到整个序列。此外,还提出了一种语义辅助和状态空间融合模块(SASFMamba),通过增强Mamba模型中的语义和几何感知来丰富上下文表示。我们的方法强调仅前景编码,并减轻线性自回归模型中基于距离和因果关系的依赖性。在各种基准测试中表现出的卓越性能证明了Fore-Mamba3D在3D目标检测任务中的有效性。
🔬 方法详解
问题定义:现有基于Mamba的3D目标检测方法通常直接对包含大量背景信息的完整体素序列进行编码,导致计算效率低下,并且背景信息会干扰前景目标的检测。简单地只编码前景体素会导致性能下降,因为前景体素之间的交互存在响应衰减,并且上下文信息受限。
核心思路:Fore-Mamba3D的核心思路是通过聚焦于前景体素的编码来提高3D目标检测的效率和准确性。通过采样前景体素,并设计专门的模块来增强前景体素之间的信息交互和上下文表示,从而克服直接编码前景体素带来的性能下降问题。
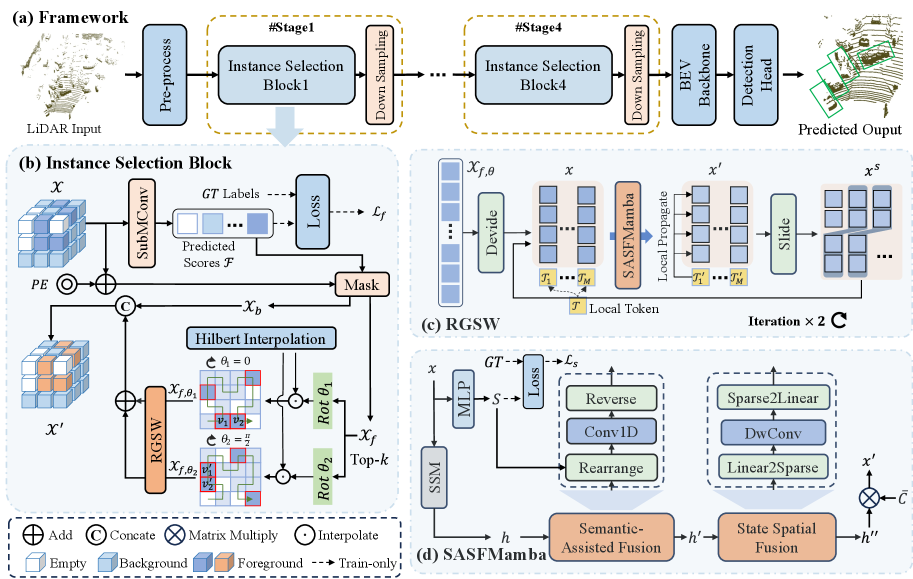
技术框架:Fore-Mamba3D的整体框架包括以下几个主要步骤:1) 首先,根据预测分数对前景体素进行采样。2) 接着,利用区域到全局滑动窗口(RGSW)来增强前景体素之间的信息交互,缓解响应衰减问题。3) 然后,通过语义辅助和状态空间融合模块(SASFMamba)来丰富上下文表示,增强语义和几何感知。4) 最后,利用增强后的特征进行3D目标检测。
关键创新:Fore-Mamba3D的关键创新在于以下几个方面:1) 提出了一种前景增强的编码策略,只关注前景体素的编码,提高了计算效率。2) 设计了区域到全局滑动窗口(RGSW),用于增强前景体素之间的信息交互,缓解响应衰减问题。3) 提出了语义辅助和状态空间融合模块(SASFMamba),用于丰富上下文表示,增强语义和几何感知。
关键设计:RGSW的具体实现方式是:将前景体素序列分割成多个区域,然后在每个区域内进行局部信息交互,最后将各个区域的信息聚合到全局序列中。SASFMamba模块通过引入语义信息和几何信息来增强Mamba模型的状态空间表示,从而提高模型对上下文信息的理解能力。具体的损失函数和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
论文在多个3D目标检测基准测试中验证了Fore-Mamba3D的有效性。实验结果表明,Fore-Mamba3D在检测精度和效率方面均优于现有的基于Mamba的方法。具体的性能提升数据在论文的实验部分进行了详细展示,包括与多个基线模型的对比结果。
🎯 应用场景
Fore-Mamba3D在自动驾驶、机器人导航、智能监控等领域具有广泛的应用前景。它可以用于提高3D场景理解的效率和准确性,从而提升相关系统的性能。例如,在自动驾驶中,Fore-Mamba3D可以帮助车辆更准确地检测和识别周围的障碍物,从而提高驾驶安全性。
📄 摘要(原文)
Linear modeling methods like Mamba have been merged as the effective backbone for the 3D object detection task. However, previous Mamba-based methods utilize the bidirectional encoding for the whole non-empty voxel sequence, which contains abundant useless background information in the scenes. Though directly encoding foreground voxels appears to be a plausible solution, it tends to degrade detection performance. We attribute this to the response attenuation and restricted context representation in the linear modeling for fore-only sequences. To address this problem, we propose a novel backbone, termed Fore-Mamba3D, to focus on the foreground enhancement by modifying Mamba-based encoder. The foreground voxels are first sampled according to the predicted scores. Considering the response attenuation existing in the interaction of foreground voxels across different instances, we design a regional-to-global slide window (RGSW) to propagate the information from regional split to the entire sequence. Furthermore, a semantic-assisted and state spatial fusion module (SASFMamba) is proposed to enrich contextual representation by enhancing semantic and geometric awareness within the Mamba model. Our method emphasizes foreground-only encoding and alleviates the distance-based and causal dependencies in the linear autoregression model. The superior performance across various benchmarks demonstrates the effectiveness of Fore-Mamba3D in the 3D object detection task.