Test-Time Computing for Referring Multimodal Large Language Models
作者: Mingrui Wu, Hao Chen, Jiayi Ji, Xiaoshuai Sun, Zhiyuan Liu, Liujuan Cao, Ming-Ming Cheng, Rongrong Ji
分类: cs.CV
发布日期: 2026-02-23
备注: arXiv admin note: substantial text overlap with arXiv:2407.21534
🔗 代码/项目: GITHUB
💡 一句话要点
提出ControlMLLM++,通过测试时计算实现Referring MLLM的区域级视觉推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉推理 测试时计算 区域级理解 视觉提示
📋 核心要点
- 现有MLLM在细粒度视觉推理方面存在不足,难以精确关注用户指定的图像区域。
- ControlMLLM++通过优化视觉提示,引导模型关注特定区域,实现无需训练的区域级视觉推理。
- 该方法支持多种视觉提示类型,并在域外数据上表现出良好的泛化能力和可解释性。
📝 摘要(中文)
我们提出了ControlMLLM++,这是一个新颖的测试时自适应框架,它将可学习的视觉提示注入到冻结的多模态大型语言模型(MLLM)中,从而实现细粒度的基于区域的视觉推理,而无需任何模型再训练或微调。ControlMLLM++利用跨模态注意力图内在编码文本标记和视觉区域之间的语义对应关系的洞察力,通过任务特定的能量函数在推理期间优化潜在的视觉标记修饰符,以引导模型注意力转向用户指定的区域。为了增强优化稳定性和减轻语言提示偏差,ControlMLLM++结合了改进的优化策略(Optim++)和提示去偏机制(PromptDebias)。我们的方法支持包括边界框、掩码、涂鸦和点在内的各种视觉提示类型,并展示了强大的域外泛化能力和可解释性。代码可在https://github.com/mrwu-mac/ControlMLLM 获取。
🔬 方法详解
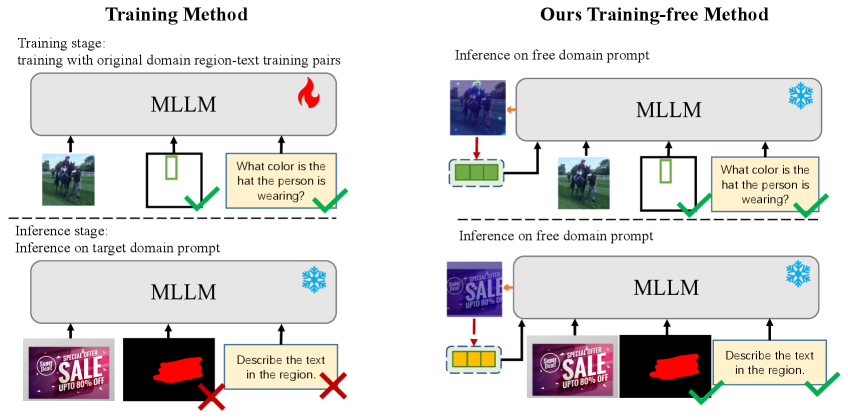
问题定义:现有的多模态大型语言模型(MLLMs)在处理需要细粒度视觉推理的任务时,往往难以精确地关注用户指定的图像区域。这些模型通常缺乏在推理阶段灵活调整视觉关注的能力,导致无法准确理解和响应基于特定区域的查询。现有方法通常需要模型微调或重新训练,计算成本高昂,且泛化能力受限。
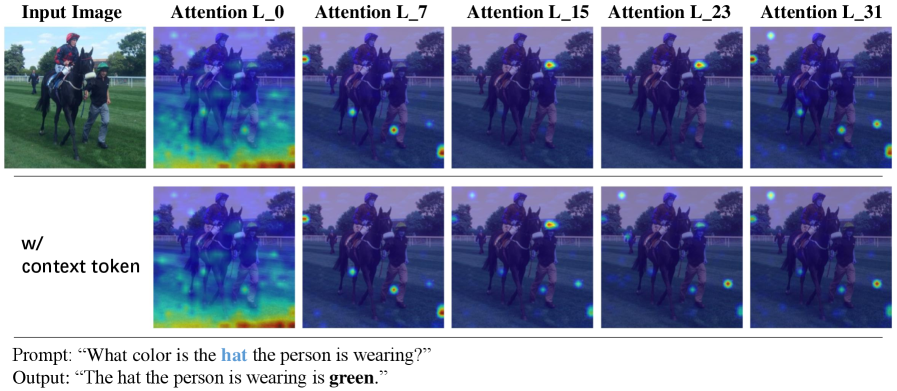
核心思路:ControlMLLM++的核心思路是在推理阶段,通过优化可学习的视觉提示(visual prompts)来引导MLLM的注意力机制,使其关注用户指定的图像区域。这种方法无需对模型进行任何训练或微调,即可实现细粒度的区域级视觉推理。通过优化一个潜在的视觉标记修饰符,模型能够更好地理解文本标记和视觉区域之间的语义对应关系。
技术框架:ControlMLLM++的整体框架包括以下几个主要模块:1) 冻结的MLLM:使用预训练好的MLLM作为基础模型。2) 可学习的视觉提示:引入可学习的视觉提示,例如边界框、掩码、涂鸦或点,用于指定用户感兴趣的区域。3) 任务特定的能量函数:定义一个能量函数,用于衡量模型对指定区域的关注程度。4) 优化策略(Optim++):采用改进的优化策略,以提高优化稳定性和收敛速度。5) 提示去偏机制(PromptDebias):引入提示去偏机制,以减轻语言提示偏差对结果的影响。
关键创新:ControlMLLM++的关键创新在于其测试时计算(test-time computing)的自适应框架,该框架允许在推理阶段动态调整模型的视觉注意力,而无需任何模型训练或微调。此外,该方法还引入了改进的优化策略和提示去偏机制,以提高优化稳定性和减轻语言提示偏差。
关键设计:ControlMLLM++的关键设计包括:1) 视觉提示的类型:支持多种视觉提示类型,包括边界框、掩码、涂鸦和点。2) 能量函数的定义:能量函数的设计需要能够准确衡量模型对指定区域的关注程度。3) 优化策略(Optim++):Optim++可能包含自适应学习率调整、动量等技术,以提高优化效率。4) 提示去偏机制(PromptDebias):PromptDebias可能通过引入额外的损失函数或正则化项,来减轻语言提示偏差的影响。
🖼️ 关键图片

📊 实验亮点
ControlMLLM++在多个基准测试中表现出强大的性能,尤其是在域外数据上。实验结果表明,该方法能够有效地引导模型关注用户指定的区域,并提高视觉推理的准确性。相较于现有方法,ControlMLLM++在无需模型训练或微调的情况下,实现了显著的性能提升,并具有更好的泛化能力和可解释性。
🎯 应用场景
ControlMLLM++具有广泛的应用前景,例如图像编辑、视觉问答、机器人导航和医学图像分析等领域。该方法可以帮助用户更精确地控制MLLM的行为,使其能够更好地理解和响应基于特定区域的查询。此外,ControlMLLM++的测试时自适应特性使其能够快速适应新的任务和领域,降低了模型部署和维护的成本。未来,该方法有望在人机交互、智能助手等领域发挥重要作用。
📄 摘要(原文)
We propose ControlMLLM++, a novel test-time adaptation framework that injects learnable visual prompts into frozen multimodal large language models (MLLMs) to enable fine-grained region-based visual reasoning without any model retraining or fine-tuning. Leveraging the insight that cross-modal attention maps intrinsically encode semantic correspondences between textual tokens and visual regions, ControlMLLM++ optimizes a latent visual token modifier during inference via a task-specific energy function to steer model attention towards user-specified areas. To enhance optimization stability and mitigate language prompt biases, ControlMLLM++ incorporates an improved optimization strategy (Optim++) and a prompt debiasing mechanism (PromptDebias). Supporting diverse visual prompt types including bounding boxes, masks, scribbles, and points, our method demonstrates strong out-of-domain generalization and interpretability. The code is available at https://github.com/mrwu-mac/ControlMLLM.