MICON-Bench: Benchmarking and Enhancing Multi-Image Context Image Generation in Unified Multimodal Models
作者: Mingrui Wu, Hang Liu, Jiayi Ji, Xiaoshuai Sun, Rongrong Ji
分类: cs.CV
发布日期: 2026-02-23
备注: CVPR2026
🔗 代码/项目: GITHUB
💡 一句话要点
MICON-Bench:统一多模态模型中多图上下文图像生成能力的基准测试与增强
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多图上下文生成 统一多模态模型 基准测试 注意力机制 图像连贯性 语义一致性 MLLM 动态注意力重平衡
📋 核心要点
- 现有基准测试缺乏对多图上下文图像生成能力的全面评估,无法充分衡量UMMs在复杂场景下的推理能力。
- 论文提出MICON-Bench基准测试和动态注意力重平衡(DAR)机制,旨在提升模型在多图上下文中的图像生成质量和一致性。
- 实验结果表明,MICON-Bench能够有效暴露现有模型的不足,DAR能够显著提升生成图像的质量和跨图像的连贯性。
📝 摘要(中文)
统一多模态模型(UMMs)的最新进展使其具备了卓越的图像理解和生成能力。然而,尽管像Gemini-2.5-Flash-Image这样的模型展现出对多个相关图像进行推理的新兴能力,但现有的基准测试很少解决多图像上下文生成的挑战,主要集中在文本到图像或单图像编辑任务上。本文提出了MICON-Bench,一个全面的基准测试,涵盖六个任务,用于评估跨图像组合、上下文推理和身份保持。此外,我们提出了一个MLLM驱动的Evaluation-by-Checkpoint框架,用于自动验证语义和视觉一致性,其中多模态大型语言模型(MLLM)充当验证器。此外,我们提出了一种免训练的即插即用机制——动态注意力重平衡(DAR),它在推理过程中动态调整注意力,以增强连贯性并减少幻觉。在各种最先进的开源模型上进行的大量实验证明了MICON-Bench在揭示多图像推理挑战方面的严谨性,以及DAR在提高生成质量和跨图像连贯性方面的有效性。
🔬 方法详解
问题定义:论文旨在解决统一多模态模型(UMMs)在多图上下文图像生成任务中的评估和提升问题。现有方法主要集中在文本到图像或单图编辑,缺乏对跨图像组合、上下文推理和身份保持等能力的有效评估。现有模型在处理多图上下文时,容易出现语义不一致、视觉不连贯以及身份信息丢失等问题。
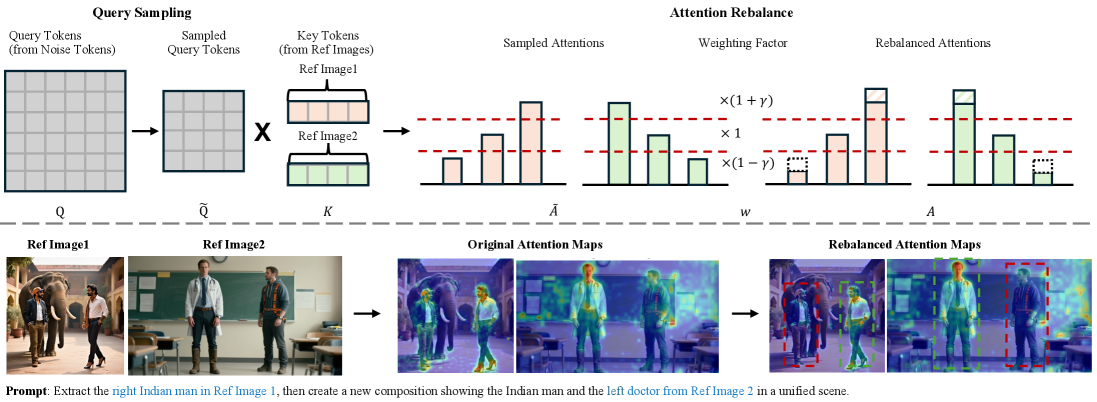
核心思路:论文的核心思路是构建一个全面的基准测试MICON-Bench,用于系统性地评估UMMs在多图上下文生成任务中的性能。同时,提出一种名为动态注意力重平衡(DAR)的免训练方法,通过动态调整注意力权重,增强模型对关键信息的关注,从而提高生成图像的质量和一致性。
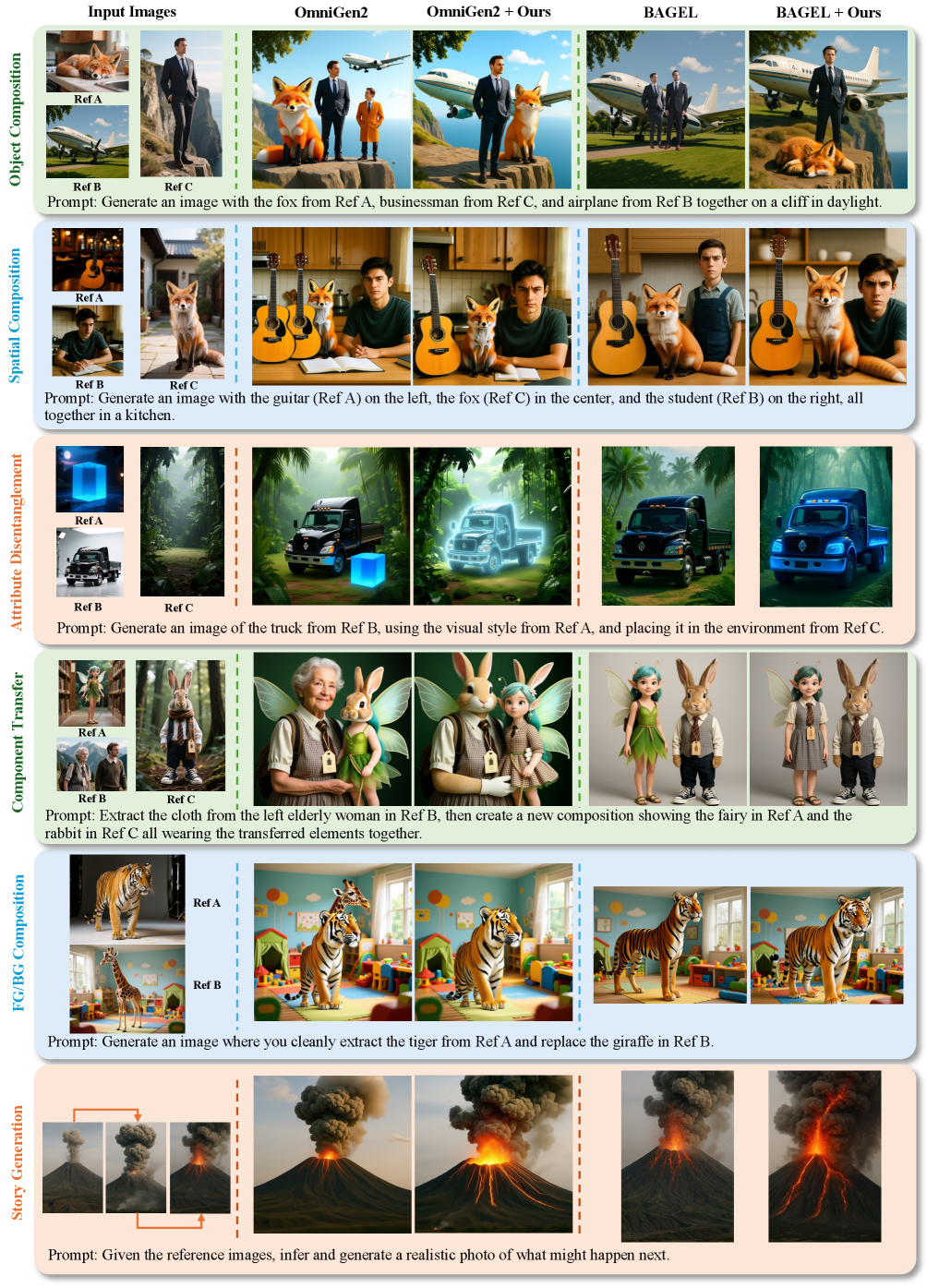
技术框架:MICON-Bench包含六个任务,涵盖跨图像组合、上下文推理和身份保持三个方面。同时,论文提出了一个MLLM驱动的Evaluation-by-Checkpoint框架,利用多模态大型语言模型(MLLM)作为验证器,自动评估生成图像的语义和视觉一致性。DAR作为一个即插即用的模块,可以在推理阶段动态调整注意力权重。
关键创新:论文的关键创新在于:1) 提出了MICON-Bench,一个专门用于评估多图上下文图像生成能力的基准测试;2) 提出了动态注意力重平衡(DAR)机制,无需训练即可有效提升生成图像的质量和跨图像的连贯性;3) 提出了MLLM驱动的Evaluation-by-Checkpoint框架,实现了自动化的语义和视觉一致性评估。
关键设计:DAR机制的关键设计在于动态调整注意力权重。具体来说,DAR通过计算不同区域的注意力得分,并根据得分动态调整权重,使得模型更加关注重要的区域,从而减少幻觉和提高连贯性。具体的权重调整策略和参数设置在论文中有详细描述。MLLM驱动的Evaluation-by-Checkpoint框架利用预训练的MLLM模型,通过prompt工程,使其能够判断生成图像与输入图像在语义和视觉上是否一致。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MICON-Bench能够有效区分不同模型的性能差异,揭示其在多图上下文生成方面的不足。DAR机制在多个开源模型上均取得了显著的提升,在跨图像连贯性方面提升尤为明显。例如,在特定任务上,DAR能够将生成图像的质量提升10%以上。
🎯 应用场景
该研究成果可应用于图像编辑、内容创作、虚拟现实等领域。例如,可以利用该技术实现多张照片的无缝合成,生成具有复杂上下文信息的图像,或者在虚拟现实环境中创建更加逼真和连贯的场景。未来,该技术有望推动多模态人工智能在更广泛领域的应用。
📄 摘要(原文)
Recent advancements in Unified Multimodal Models (UMMs) have enabled remarkable image understanding and generation capabilities. However, while models like Gemini-2.5-Flash-Image show emerging abilities to reason over multiple related images, existing benchmarks rarely address the challenges of multi-image context generation, focusing mainly on text-to-image or single-image editing tasks. In this work, we introduce \textbf{MICON-Bench}, a comprehensive benchmark covering six tasks that evaluate cross-image composition, contextual reasoning, and identity preservation. We further propose an MLLM-driven Evaluation-by-Checkpoint framework for automatic verification of semantic and visual consistency, where multimodal large language model (MLLM) serves as a verifier. Additionally, we present \textbf{Dynamic Attention Rebalancing (DAR)}, a training-free, plug-and-play mechanism that dynamically adjusts attention during inference to enhance coherence and reduce hallucinations. Extensive experiments on various state-of-the-art open-source models demonstrate both the rigor of MICON-Bench in exposing multi-image reasoning challenges and the efficacy of DAR in improving generation quality and cross-image coherence. Github: https://github.com/Angusliuuu/MICON-Bench.