Laplacian Multi-scale Flow Matching for Generative Modeling
作者: Zelin Zhao, Petr Molodyk, Haotian Xue, Yongxin Chen
分类: cs.CV, cs.LG
发布日期: 2026-02-23
备注: Accepted to appear in ICLR 2026
💡 一句话要点
LapFlow:提出拉普拉斯多尺度流匹配方法,提升图像生成质量与效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像生成 流匹配 拉普拉斯金字塔 多尺度表示 混合Transformer 生成模型 高分辨率图像 因果注意力
📋 核心要点
- 现有流匹配方法在处理高分辨率图像生成时面临计算量大、生成速度慢等挑战。
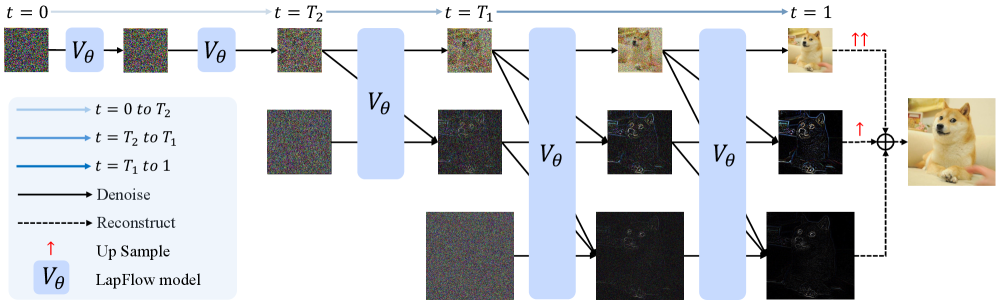
- LapFlow通过拉普拉斯金字塔分解图像,并行处理不同尺度信息,避免了尺度间的显式去噪过程。
- 实验表明,LapFlow在CelebA-HQ和ImageNet数据集上,以更少的计算量实现了更高的生成质量和更快的推理速度。
📝 摘要(中文)
本文提出了一种名为拉普拉斯多尺度流匹配(LapFlow)的新框架,通过利用多尺度表示来增强图像生成建模的流匹配。我们的方法将图像分解为拉普拉斯金字塔残差,并通过具有因果注意力机制的混合Transformer(MoT)架构并行处理不同的尺度。与之前需要在尺度之间进行显式去噪的级联方法不同,我们的模型并行生成多尺度表示,无需桥接过程。所提出的多尺度架构不仅提高了生成质量,还加速了采样过程并促进了流匹配方法的可扩展性。通过在CelebA-HQ和ImageNet上的大量实验,我们证明了我们的方法与单尺度和多尺度流匹配基线相比,以更少的GFLOPs和更快的推理实现了卓越的样本质量。所提出的模型有效地扩展到高分辨率生成(高达1024×1024),同时保持较低的计算开销。
🔬 方法详解
问题定义:现有的流匹配方法在图像生成任务中,尤其是在高分辨率图像生成时,面临着计算复杂度高、生成速度慢的问题。传统的级联方法需要在不同尺度之间进行显式的去噪处理,增加了计算负担和模型复杂度。
核心思路:LapFlow的核心思路是将图像分解为拉普拉斯金字塔残差,并在不同的尺度上并行地进行处理。通过这种多尺度表示,模型可以更好地捕捉图像的不同频率成分,从而提高生成质量。并行处理避免了尺度间的依赖,减少了计算量,加速了生成过程。
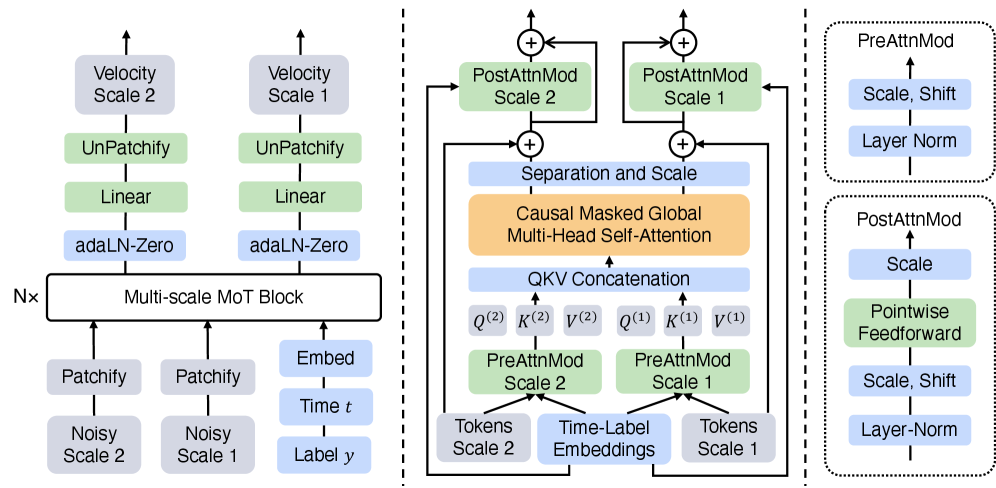
技术框架:LapFlow的整体架构基于流匹配框架,并引入了拉普拉斯金字塔分解和混合Transformer(MoT)架构。首先,输入图像被分解为拉普拉斯金字塔残差。然后,每个尺度的残差通过一个MoT模块进行处理,MoT模块包含因果注意力机制,用于建模尺度内的依赖关系。最后,将不同尺度的输出合并,生成最终的图像。
关键创新:LapFlow的关键创新在于其多尺度并行处理架构。与传统的级联方法不同,LapFlow避免了尺度间的显式去噪过程,从而显著降低了计算复杂度。此外,LapFlow利用MoT架构来建模尺度内的依赖关系,提高了生成质量。
关键设计:LapFlow的关键设计包括拉普拉斯金字塔的分解层数、MoT模块的层数和隐藏单元数、以及损失函数的选择。论文中可能使用了标准的拉普拉斯金字塔分解方法,并针对MoT模块进行了参数调整,以平衡生成质量和计算效率。损失函数可能采用了标准的流匹配损失函数,例如最小二乘损失或交叉熵损失。
🖼️ 关键图片

📊 实验亮点
LapFlow在CelebA-HQ和ImageNet数据集上取得了显著的性能提升。与单尺度和多尺度流匹配基线相比,LapFlow在生成质量上取得了显著提升,同时降低了计算量(GFLOPs)并加快了推理速度。该模型能够有效地扩展到高分辨率图像生成(高达1024×1024),同时保持较低的计算开销。
🎯 应用场景
LapFlow在图像生成领域具有广泛的应用前景,可用于生成高质量的人脸图像、自然图像等。该方法还可以应用于图像编辑、图像修复等任务。其高效的生成能力使其在需要快速生成大量图像的场景中具有重要价值,例如游戏开发、虚拟现实等。
📄 摘要(原文)
In this paper, we present Laplacian multiscale flow matching (LapFlow), a novel framework that enhances flow matching by leveraging multi-scale representations for image generative modeling. Our approach decomposes images into Laplacian pyramid residuals and processes different scales in parallel through a mixture-of-transformers (MoT) architecture with causal attention mechanisms. Unlike previous cascaded approaches that require explicit renoising between scales, our model generates multi-scale representations in parallel, eliminating the need for bridging processes. The proposed multi-scale architecture not only improves generation quality but also accelerates the sampling process and promotes scaling flow matching methods. Through extensive experimentation on CelebA-HQ and ImageNet, we demonstrate that our method achieves superior sample quality with fewer GFLOPs and faster inference compared to single-scale and multi-scale flow matching baselines. The proposed model scales effectively to high-resolution generation (up to 1024$\times$1024) while maintaining lower computational overhead.