UrbanAlign: Post-hoc Semantic Calibration for VLM-Human Preference Alignment
作者: Yecheng Zhang, Rong Zhao, Zhizhou Sha, Yong Li, Lei Wang, Ce Hou, Wen Ji, Hao Huang, Yunshan Wan, Jian Yu, Junhao Xia, Yuru Zhang, Chunlei Shi
分类: cs.CV
发布日期: 2026-02-23
备注: 26 pages
💡 一句话要点
提出UrbanAlign以解决视觉语言模型与人类偏好对齐问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉语言模型 人类偏好对齐 后处理方法 城市感知 概念挖掘 几何校准 多代理评分 无训练校准
📋 核心要点
- 现有方法在将视觉语言模型输出与人类偏好对齐时,通常需要大量标注数据和计算资源,限制了其应用。
- 论文提出了一种无训练的后处理管道,通过概念挖掘和几何校准等步骤,直接实现VLM输出与人类偏好的对齐。
- 在城市感知任务中,UrbanAlign框架的准确率达到72.2%,显著优于现有最佳基线,展示了其有效性和可解释性。
📝 摘要(中文)
在特定领域任务中,将视觉语言模型(VLM)输出与人类偏好对齐通常需要微调或强化学习,这两者都依赖于标注数据和GPU计算。本文展示了在主观感知任务中,这种对齐可以在不进行任何模型训练的情况下实现。我们提出了一种无训练的后处理概念瓶颈管道,包含三个紧密耦合的阶段:概念挖掘、多代理结构评分和几何校准,通过端到端的维度优化循环统一。该框架在城市感知任务中应用,取得了72.2%的准确率,超越了最佳监督基线15.1个百分点和未校准VLM评分16.3个百分点,且具备全维度可解释性和零模型权重修改。
🔬 方法详解
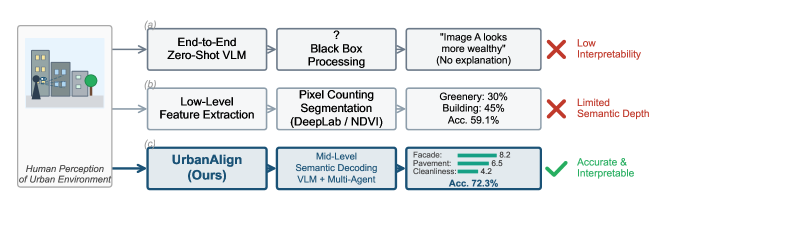
问题定义:本文旨在解决视觉语言模型(VLM)在主观感知任务中输出与人类偏好对齐的困难。现有方法依赖于微调和强化学习,需大量标注数据和计算资源,效率低下。
核心思路:我们提出了一种后处理的概念瓶颈管道,利用现有的VLM作为强大的概念提取器,通过外部校准来弥补其决策能力不足的问题。
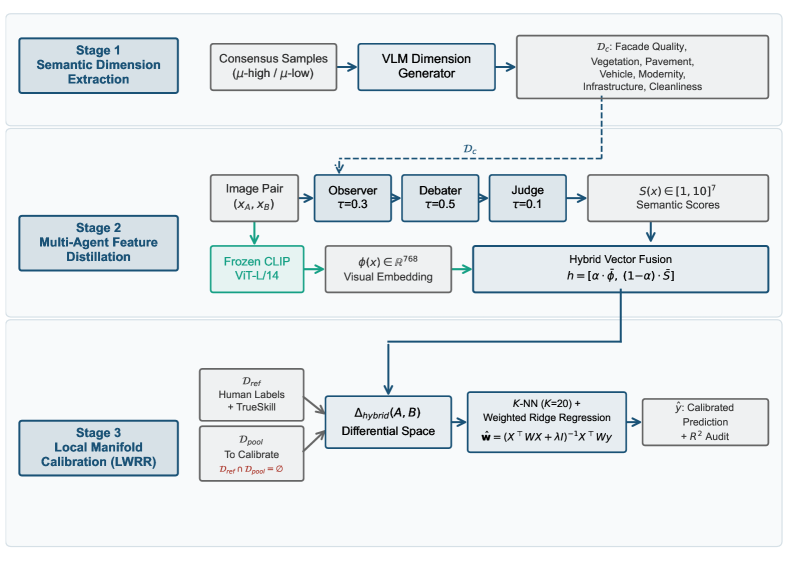
技术框架:该框架包含三个主要阶段:概念挖掘、基于多代理的结构评分和几何校准。通过一个端到端的维度优化循环,将这些阶段紧密结合。
关键创新:最重要的创新在于无需对模型进行训练,直接通过后处理方法实现了VLM输出与人类偏好的对齐,显著提高了准确性和可解释性。
关键设计:在概念挖掘阶段,从少量人类标注中提取可解释的评估维度;在评分阶段,使用观察者-辩论者-评判者链提取连续的概念分数;最后,通过局部加权岭回归在混合视觉-语义流形上校准这些分数与人类评分。
🖼️ 关键图片
📊 实验亮点
在Place Pulse 2.0数据集上,UrbanAlign框架实现了72.2%的准确率(κ=0.45),相比最佳监督基线提高了15.1个百分点,且比未校准的VLM评分提高了16.3个百分点,展示了其显著的性能提升和全维度可解释性。
🎯 应用场景
UrbanAlign框架在城市感知任务中表现出色,具有广泛的应用潜力。其方法可以推广到其他领域,如社交媒体内容分析、用户体验评估等,帮助实现更高效的视觉-语言模型对齐,提升用户满意度和系统性能。
📄 摘要(原文)
Aligning vision-language model (VLM) outputs with human preferences in domain-specific tasks typically requires fine-tuning or reinforcement learning, both of which demand labelled data and GPU compute. We show that for subjective perception tasks, this alignment can be achieved without any model training: VLMs are already strong concept extractors but poor decision calibrators, and the gap can be closed externally. We propose a training-free post-hoc concept-bottleneck pipeline consisting of three tightly coupled stages: concept mining, multi-agent structured scoring, and geometric calibration, unified by an end-to-end dimension optimization loop. Interpretable evaluation dimensions are mined from a handful of human annotations; an Observer-Debater-Judge chain extracts robust continuous concept scores from a frozen VLM; and locally-weighted ridge regression on a hybrid visual-semantic manifold calibrates these scores against human ratings. Applied to urban perception as UrbanAlign, the framework achieves 72.2% accuracy ($κ=0.45$) on Place Pulse 2.0 across six categories, outperforming the best supervised baseline by +15.1 pp and uncalibrated VLM scoring by +16.3 pp, with full dimension-level interpretability and zero model-weight modification.