CountEx: Fine-Grained Counting via Exemplars and Exclusion
作者: Yifeng Huang, Gia Khanh Nguyen, Minh Hoai
分类: cs.CV
发布日期: 2026-02-23
🔗 代码/项目: GITHUB
💡 一句话要点
CountEx:通过范例和排除实现细粒度计数,解决现有方法易混淆对象的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉计数 细粒度计数 多模态提示 判别式学习 排除法 目标检测 计算机视觉
📋 核心要点
- 现有基于提示的计数方法难以排除视觉相似的干扰物,导致在复杂场景中计数不准确。
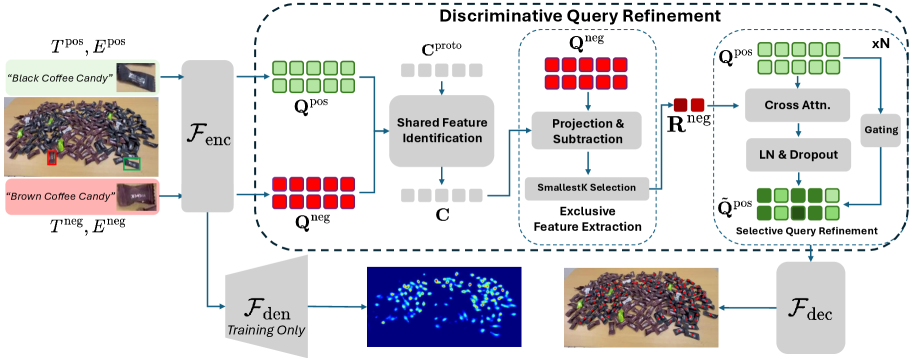
- CountEx通过多模态提示(包含和排除)指导计数,并提出判别式查询细化模块。
- 在CoCount基准测试中,CountEx显著优于现有方法,适用于已知和新类别对象的计数。
📝 摘要(中文)
本文提出了一种判别式视觉计数框架CountEx,旨在解决现有基于提示的方法的一个关键限制:无法显式排除视觉上相似的干扰物。虽然当前的方法允许用户通过包含提示来指定要计数的内容,但它们在杂乱的场景中,面对容易混淆的对象类别时,常常表现不佳,导致歧义和过度计数。CountEx使用户能够表达包含和排除的意图,通过多模态提示(包括自然语言描述和可选的视觉范例)来指定要计数的内容和要忽略的内容。CountEx的核心是一个新颖的判别式查询细化模块,该模块通过首先识别共享的视觉特征,然后隔离排除特定的模式,最后应用选择性抑制来细化计数查询,从而共同推理包含和排除的线索。为了支持对细粒度计数方法的系统评估,我们引入了CoCount,这是一个包含97个类别对的1,780个视频和10,086个带注释帧的基准。实验表明,CountEx在计数已知和新类别对象方面,比最先进的方法取得了显著的改进。数据和代码可在https://github.com/bbvisual/CountEx获得。
🔬 方法详解
问题定义:现有基于提示的视觉计数方法,尤其是那些依赖于单一“包含”提示的方法,在处理包含视觉上相似但需要排除的干扰物的复杂场景时,表现不佳。这些方法容易将干扰物错误地计入目标对象,导致计数结果不准确。因此,需要一种能够区分目标对象和干扰物,并进行精确计数的方案。
核心思路:CountEx的核心思路是同时利用“包含”和“排除”两种提示,通过多模态信息(自然语言和视觉范例)来更精确地定义计数目标。通过显式地指定需要排除的对象,模型可以更好地学习目标对象的独特特征,并抑制对干扰物的响应。这种双重提示机制能够有效减少歧义,提高计数精度。
技术框架:CountEx的整体框架包含以下几个主要模块:1) 多模态提示编码器:将自然语言描述和视觉范例编码成特征向量。2) 判别式查询细化模块:这是CountEx的核心模块,它首先识别包含和排除提示之间的共享视觉特征,然后隔离排除提示特有的模式,最后应用选择性抑制来细化计数查询。3) 计数预测器:基于细化后的查询,预测图像中目标对象的数量。整个流程旨在通过融合包含和排除信息,生成更精确的计数结果。
关键创新:CountEx的关键创新在于其判别式查询细化模块。该模块能够有效地利用包含和排除提示,通过识别共享特征和隔离排除特定模式,来细化计数查询。与现有方法仅依赖包含提示相比,CountEx能够更准确地捕捉目标对象的独特特征,并抑制对干扰物的响应。这种判别式学习方法是CountEx能够取得显著性能提升的关键。
关键设计:判别式查询细化模块的具体实现可能涉及注意力机制、特征融合策略和损失函数设计。例如,可以使用交叉注意力机制来学习包含和排除提示之间的关系,并使用对比损失函数来鼓励模型区分目标对象和干扰物。此外,网络结构的设计也至关重要,需要能够有效地处理多模态输入,并进行特征提取和融合。
🖼️ 关键图片

📊 实验亮点
CountEx在CoCount基准测试中取得了显著的性能提升。与最先进的方法相比,CountEx在计数已知类别对象和新类别对象方面均表现出更优的性能。具体而言,CountEx在多个指标上均取得了显著的改进,例如平均绝对误差(MAE)和均方误差(MSE)。这些实验结果表明,CountEx能够有效地利用包含和排除提示,提高计数精度,并具有良好的泛化能力。
🎯 应用场景
CountEx在多个领域具有广泛的应用前景,例如智能监控、零售分析、自动驾驶和生物医学图像分析。在智能监控中,可以用于精确统计人群数量或特定车辆类型。在零售分析中,可以用于统计货架上的商品数量或顾客数量。在自动驾驶中,可以用于识别和计数行人、车辆等目标。在生物医学图像分析中,可以用于计数细胞数量或识别特定类型的组织结构。CountEx的细粒度计数能力能够为这些应用提供更准确的数据支持,从而提升决策效率和智能化水平。
📄 摘要(原文)
This paper presents CountEx, a discriminative visual counting framework designed to address a key limitation of existing prompt-based methods: the inability to explicitly exclude visually similar distractors. While current approaches allow users to specify what to count via inclusion prompts, they often struggle in cluttered scenes with confusable object categories, leading to ambiguity and overcounting. CountEx enables users to express both inclusion and exclusion intent, specifying what to count and what to ignore, through multimodal prompts including natural language descriptions and optional visual exemplars. At the core of CountEx is a novel Discriminative Query Refinement module, which jointly reasons over inclusion and exclusion cues by first identifying shared visual features, then isolating exclusion-specific patterns, and finally applying selective suppression to refine the counting query. To support systematic evaluation of fine-grained counting methods, we introduce CoCount, a benchmark comprising 1,780 videos and 10,086 annotated frames across 97 category pairs. Experiments show that CountEx achieves substantial improvements over state-of-the-art methods for counting objects from both known and novel categories. The data and code are available at https://github.com/bbvisual/CountEx.