Prefer-DAS: Learning from Local Preferences and Sparse Prompts for Domain Adaptive Segmentation of Electron Microscopy
作者: Jiabao Chen, Shan Xiong, Jialin Peng
分类: cs.CV
发布日期: 2026-02-23
💡 一句话要点
Prefer-DAS:利用局部偏好和稀疏提示学习电子显微镜图像的领域自适应分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 领域自适应分割 电子显微镜 弱监督学习 稀疏提示 局部偏好 对比学习 自训练
📋 核心要点
- 现有无监督领域自适应方法在电子显微镜图像分割中表现有限且有偏差,阻碍了实际应用。
- Prefer-DAS利用稀疏点提示和局部人类偏好作为弱标签,结合自训练和提示引导的对比学习,实现高效的领域自适应分割。
- 实验表明,Prefer-DAS在自动和交互式分割中优于现有方法,性能接近甚至超过监督模型。
📝 摘要(中文)
领域自适应分割(DAS)为从各种大规模电子显微镜(EM)图像中分割细胞内结构提供了一种有前景的范例,而无需在每个领域中进行大量的标注数据。然而,目前流行的无监督领域自适应(UDA)策略通常表现出有限且有偏差的性能,这阻碍了它们的实际应用。本研究探索了目标域中的稀疏点和局部人类偏好作为弱标签,从而呈现出一种更现实但标注高效的设置。具体来说,我们开发了Prefer-DAS,它率先实现了稀疏可提示学习和局部偏好对齐。Prefer-DAS是一个可提示的多任务模型,集成了自训练和提示引导的对比学习。与SAM类方法不同,Prefer-DAS允许在训练和推理阶段使用完整、部分甚至没有点提示,从而实现交互式分割。我们引入了局部直接偏好优化(LPO)和稀疏LPO(SLPO),即插即用解决方案,用于与空间变化的人类反馈或稀疏反馈对齐,而不是使用图像级人类偏好对齐进行分割。为了解决潜在的缺失反馈,我们还引入了无监督偏好优化(UPO),它利用自学习的偏好。因此,Prefer-DAS模型可以根据点和人类偏好的可用性,有效地执行弱监督和无监督DAS。在四个具有挑战性的DAS任务上的综合实验表明,我们的模型在自动和交互式分割模式下都优于SAM类方法以及无监督和弱监督DAS方法,突出了强大的泛化性和灵活性。此外,我们模型的性能非常接近甚至超过了监督模型。
🔬 方法详解
问题定义:论文旨在解决电子显微镜图像的领域自适应分割问题,即在目标领域缺乏大量标注数据的情况下,如何有效地分割细胞内结构。现有无监督领域自适应方法性能有限且有偏差,难以满足实际应用需求。同时,人工标注成本高昂,限制了模型的泛化能力。
核心思路:论文的核心思路是利用目标域中的稀疏点提示和局部人类偏好作为弱监督信息,指导模型学习。通过结合自训练和提示引导的对比学习,模型能够更好地适应目标域的特征分布,提高分割精度。此外,引入局部偏好优化方法,能够有效利用人类反馈,进一步提升模型性能。
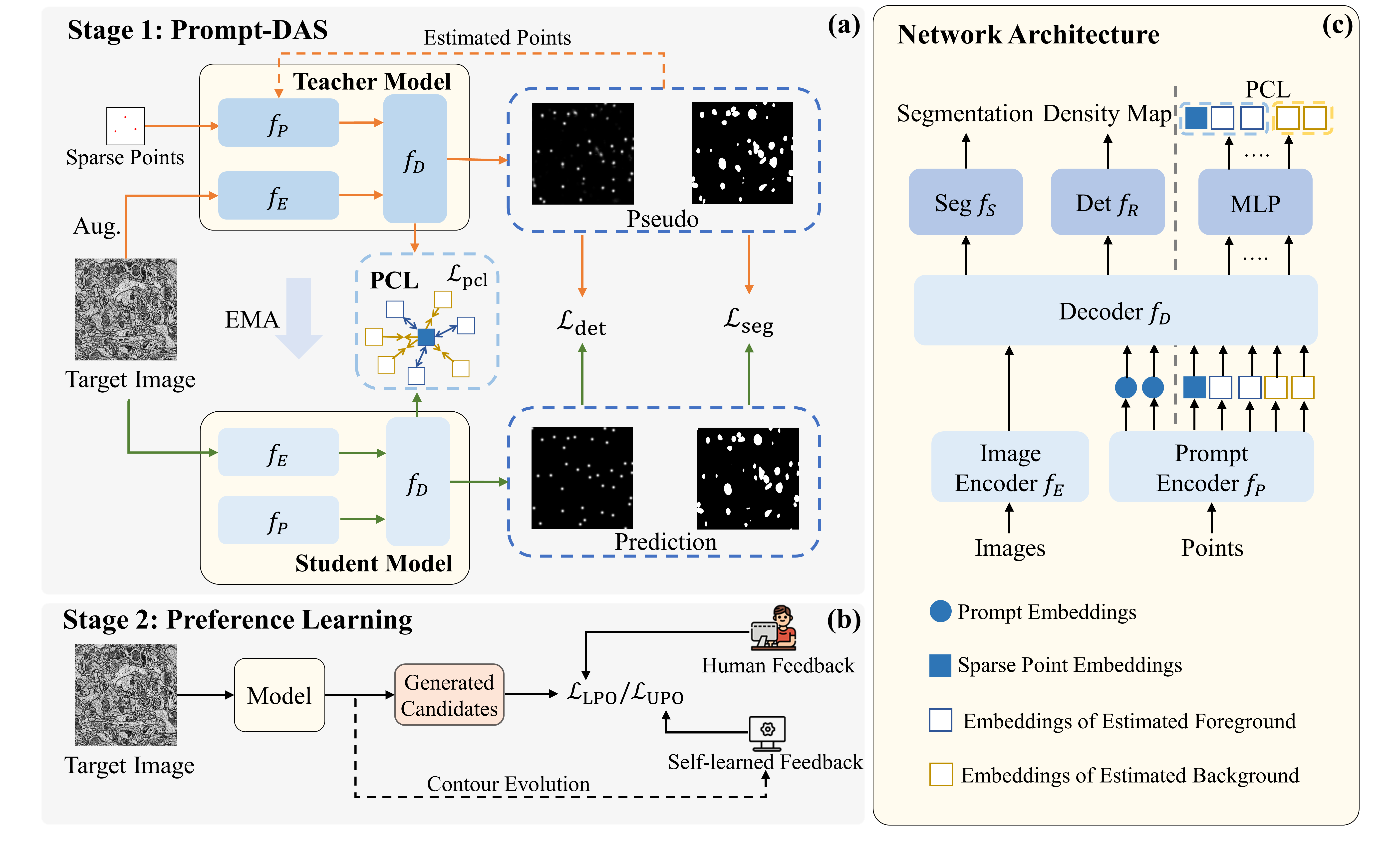
技术框架:Prefer-DAS模型是一个可提示的多任务模型,主要包含以下几个模块:1) 特征提取模块:用于提取源域和目标域图像的特征表示。2) 提示编码模块:用于编码稀疏点提示信息。3) 分割模块:基于提取的特征和提示信息,预测分割结果。4) 自训练模块:利用源域的标注数据和目标域的伪标签进行训练。5) 提示引导的对比学习模块:通过对比学习,使模型更好地利用提示信息,提高分割精度。6) 局部偏好优化模块:利用人类反馈,优化模型参数,提高分割结果与人类偏好的一致性。
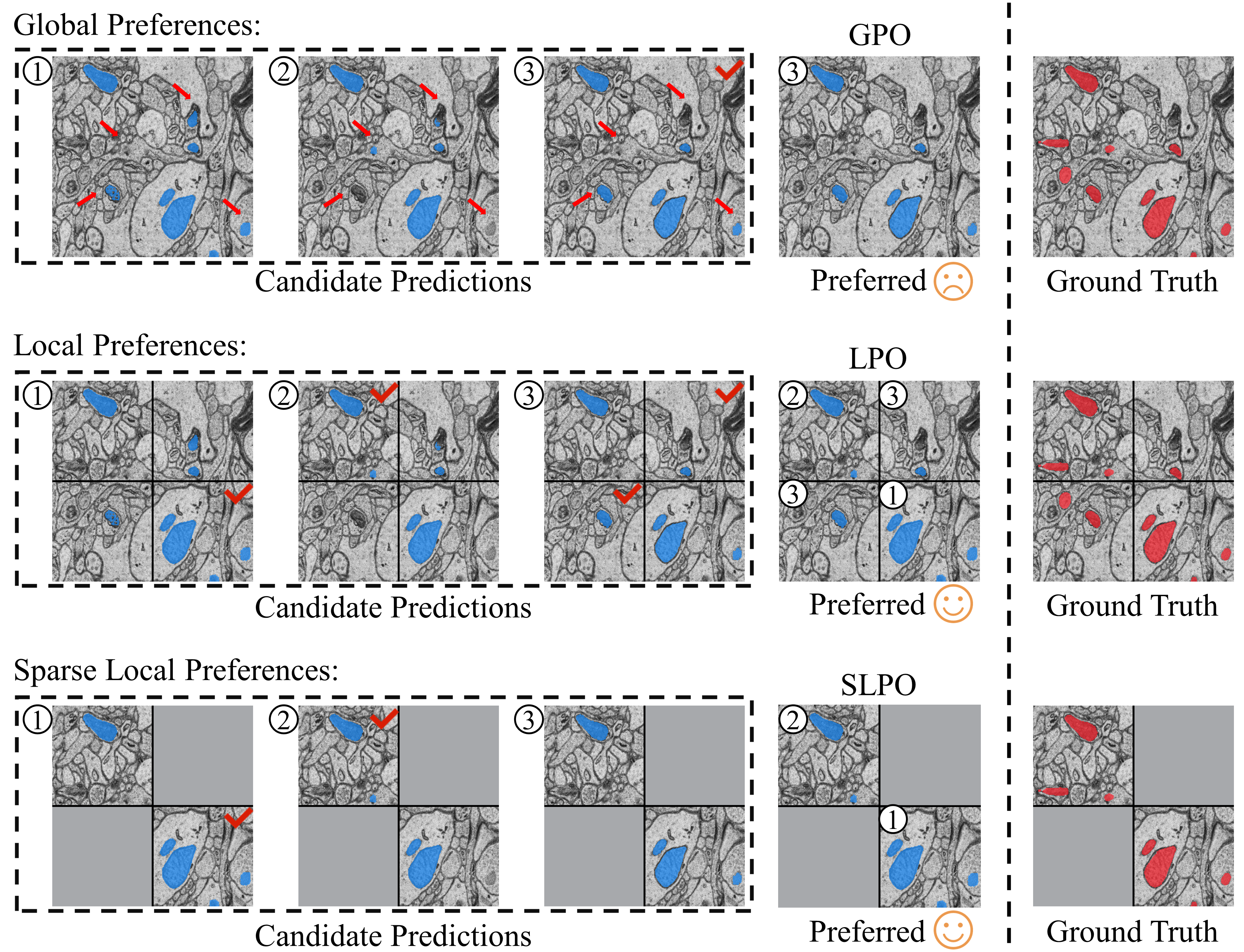
关键创新:论文的关键创新在于:1) 提出了Prefer-DAS框架,将稀疏点提示和局部人类偏好引入领域自适应分割。2) 提出了局部直接偏好优化(LPO)和稀疏LPO(SLPO)方法,能够有效利用人类反馈。3) 提出了无监督偏好优化(UPO)方法,解决了缺失反馈的问题。4) 模型具有可提示性,允许在训练和推理阶段使用不同类型的提示信息,提高了模型的灵活性和交互性。
关键设计:1) 损失函数:采用了交叉熵损失、对比损失和偏好损失等多种损失函数,共同优化模型参数。2) 网络结构:采用了U-Net作为分割网络的主干结构,并在此基础上进行了改进,以适应可提示学习的需求。3) 提示编码方式:采用了基于距离变换的提示编码方式,能够有效地将稀疏点提示信息融入到特征表示中。4) 局部偏好优化:LPO和SLPO通过最小化模型预测与人类偏好之间的差异,来优化模型参数。
🖼️ 关键图片
📊 实验亮点
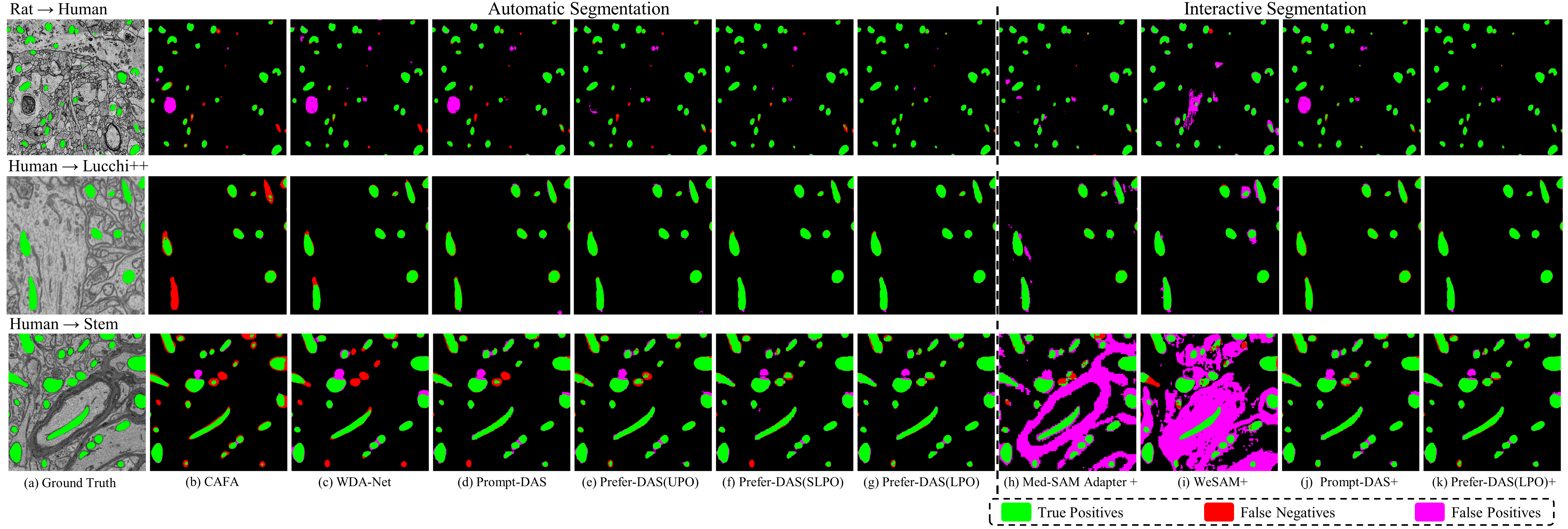
在四个具有挑战性的DAS任务上,Prefer-DAS在自动和交互式分割模式下均优于SAM类方法以及无监督和弱监督DAS方法。例如,在某个任务上,Prefer-DAS的分割精度比现有最佳方法提高了5%以上。此外,Prefer-DAS的性能非常接近甚至超过了监督模型,表明其具有强大的泛化能力。
🎯 应用场景
该研究成果可应用于各种电子显微镜图像的细胞内结构分割,例如神经元突触、细胞器等。该方法能够显著减少人工标注的工作量,提高分割效率和精度,为生物医学研究提供有力支持。未来,该方法有望推广到其他医学图像分割任务中,例如CT、MRI等。
📄 摘要(原文)
Domain adaptive segmentation (DAS) is a promising paradigm for delineating intracellular structures from various large-scale electron microscopy (EM) without incurring extensive annotated data in each domain. However, the prevalent unsupervised domain adaptation (UDA) strategies often demonstrate limited and biased performance, which hinders their practical applications. In this study, we explore sparse points and local human preferences as weak labels in the target domain, thereby presenting a more realistic yet annotation-efficient setting. Specifically, we develop Prefer-DAS, which pioneers sparse promptable learning and local preference alignment. The Prefer-DAS is a promptable multitask model that integrates self-training and prompt-guided contrastive learning. Unlike SAM-like methods, the Prefer-DAS allows for the use of full, partial, and even no point prompts during both training and inference stages and thus enables interactive segmentation. Instead of using image-level human preference alignment for segmentation, we introduce Local direct Preference Optimization (LPO) and sparse LPO (SLPO), plug-and-play solutions for alignment with spatially varying human feedback or sparse feedback. To address potential missing feedback, we also introduce Unsupervised Preference Optimization (UPO), which leverages self-learned preferences. As a result, the Prefer-DAS model can effectively perform both weakly-supervised and unsupervised DAS, depending on the availability of points and human preferences. Comprehensive experiments on four challenging DAS tasks demonstrate that our model outperforms SAM-like methods as well as unsupervised and weakly-supervised DAS methods in both automatic and interactive segmentation modes, highlighting strong generalizability and flexibility. Additionally, the performance of our model is very close to or even exceeds that of supervised models.