PA-Attack: Guiding Gray-Box Attacks on LVLM Vision Encoders with Prototypes and Attention
作者: Hefei Mei, Zirui Wang, Chang Xu, Jianyuan Guo, Minjing Dong
分类: cs.CV
发布日期: 2026-02-23
🔗 代码/项目: GITHUB
💡 一句话要点
提出PA-Attack,通过原型引导和注意力机制增强LVLM视觉编码器的灰盒攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 视觉语言模型 灰盒攻击 注意力机制 原型学习
📋 核心要点
- 现有LVLM对抗攻击方法泛化性差,白盒攻击难以跨任务,黑盒攻击迁移成本高昂。
- PA-Attack通过原型锚定引导攻击方向,并利用注意力机制增强对关键视觉token的扰动。
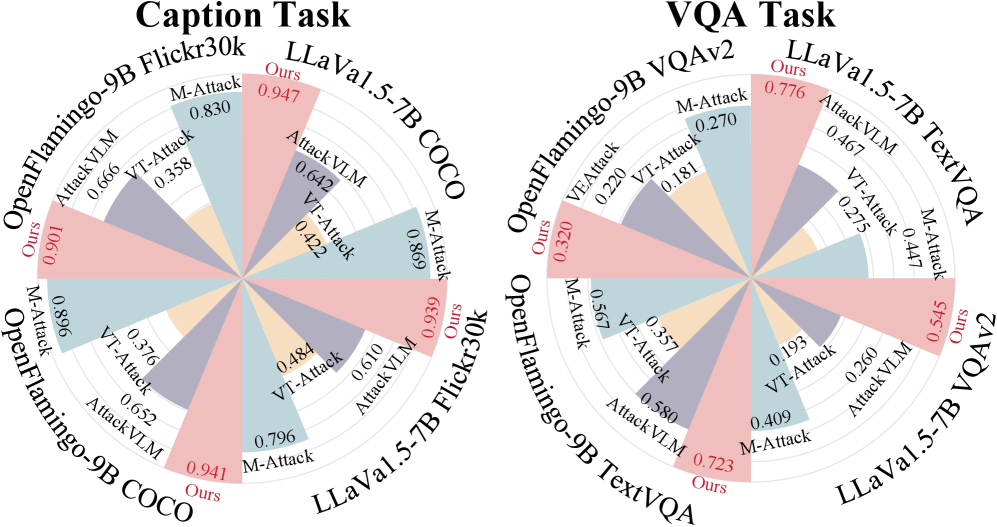
- 实验表明,PA-Attack在多种LVLM和下游任务中实现了平均75.1%的分数降低率,攻击效果显著。
📝 摘要(中文)
大型视觉语言模型(LVLM)是现代多模态应用的基础,但它们对对抗性攻击的敏感性仍然是一个关键问题。先前的白盒攻击很少能跨任务泛化,而黑盒方法依赖于昂贵的迁移,这限制了效率。视觉编码器是标准化的,并且通常在LVLM之间共享,它提供了一个稳定的灰盒支点,具有强大的跨模型迁移能力。基于此,我们提出了PA-Attack(原型锚定注意力攻击)。PA-Attack首先进行原型锚定引导,提供一个指向通用且不同原型的稳定攻击方向,解决了vanilla攻击的属性限制问题和有限的任务泛化能力。在此基础上,我们提出了一种两阶段注意力增强机制:(i)利用token级别的注意力分数,将扰动集中在关键的视觉token上,(ii)自适应地重新校准注意力权重,以跟踪对抗过程中的注意力演变。在不同的下游任务和LVLM架构上的大量实验表明,PA-Attack实现了平均75.1%的分数降低率(SRR),证明了其在LVLM中强大的攻击有效性、效率和任务泛化能力。代码可在https://github.com/hefeimei06/PA-Attack获取。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLM)在面对对抗攻击时的脆弱性问题。现有的白盒攻击方法通常依赖于特定任务,难以泛化到其他任务;而黑盒攻击方法则需要大量的迁移学习,效率低下。因此,如何设计一种高效且具有良好泛化能力的LVLM对抗攻击方法是一个关键挑战。
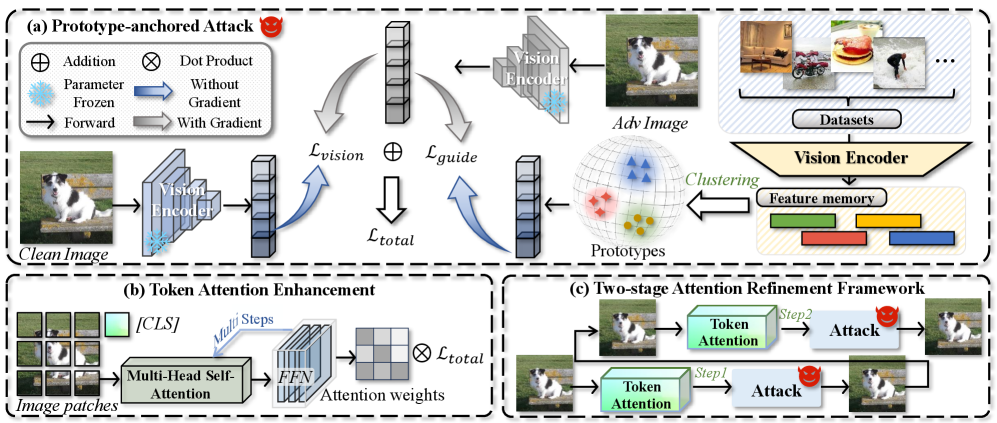
核心思路:PA-Attack的核心思路是利用LVLM中共享的视觉编码器作为灰盒攻击的支点,通过原型锚定引导攻击方向,并结合注意力机制增强对关键视觉token的扰动。这种方法旨在提高攻击的效率和泛化能力,使其能够有效地攻击不同的LVLM和下游任务。
技术框架:PA-Attack包含两个主要阶段:原型锚定引导和注意力增强。首先,通过原型锚定引导,确定一个指向通用且不同原型的稳定攻击方向。然后,通过两阶段注意力增强机制,首先利用token级别的注意力分数将扰动集中在关键的视觉token上,接着自适应地重新校准注意力权重,以跟踪对抗过程中的注意力演变。
关键创新:PA-Attack的关键创新在于其原型锚定引导和两阶段注意力增强机制。原型锚定引导解决了传统攻击方法中属性限制和任务泛化能力有限的问题。两阶段注意力增强机制则能够更有效地利用注意力信息,将扰动集中在对模型影响最大的视觉token上,从而提高攻击的效率。
关键设计:在原型锚定引导方面,需要选择合适的原型,并设计相应的损失函数来引导攻击方向。在注意力增强方面,需要选择合适的注意力计算方法,并设计自适应的权重校准策略,以跟踪对抗过程中的注意力变化。具体的参数设置和网络结构细节在论文中有详细描述,此处不再赘述。
🖼️ 关键图片
📊 实验亮点
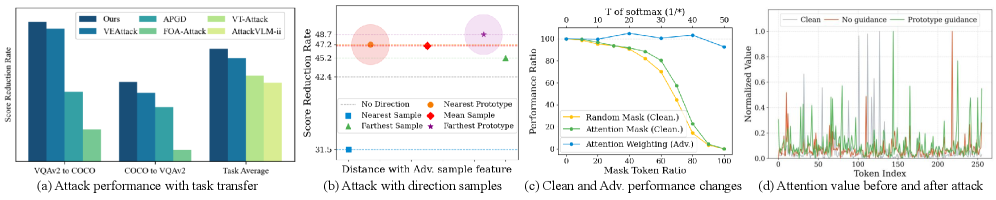
PA-Attack在多种下游任务和LVLM架构上进行了广泛的实验验证。实验结果表明,PA-Attack能够有效地降低LVLM的性能,平均实现了75.1%的分数降低率(SRR)。相较于其他攻击方法,PA-Attack在攻击效果、效率和任务泛化能力方面均表现出显著优势。
🎯 应用场景
PA-Attack的研究成果可应用于评估和提升LVLM的鲁棒性,帮助开发者发现模型潜在的安全漏洞。此外,该方法也可用于设计更安全的LVLM防御机制,提高模型在实际应用中的可靠性。该研究对于推动安全可靠的多模态人工智能发展具有重要意义。
📄 摘要(原文)
Large Vision-Language Models (LVLMs) are foundational to modern multimodal applications, yet their susceptibility to adversarial attacks remains a critical concern. Prior white-box attacks rarely generalize across tasks, and black-box methods depend on expensive transfer, which limits efficiency. The vision encoder, standardized and often shared across LVLMs, provides a stable gray-box pivot with strong cross-model transfer. Building on this premise, we introduce PA-Attack (Prototype-Anchored Attentive Attack). PA-Attack begins with a prototype-anchored guidance that provides a stable attack direction towards a general and dissimilar prototype, tackling the attribute-restricted issue and limited task generalization of vanilla attacks. Building on this, we propose a two-stage attention enhancement mechanism: (i) leverage token-level attention scores to concentrate perturbations on critical visual tokens, and (ii) adaptively recalibrate attention weights to track the evolving attention during the adversarial process. Extensive experiments across diverse downstream tasks and LVLM architectures show that PA-Attack achieves an average 75.1% score reduction rate (SRR), demonstrating strong attack effectiveness, efficiency, and task generalization in LVLMs. Code is available at https://github.com/hefeimei06/PA-Attack.